testcholdout
2 つの分類モデルの予測精度を比較
構文
説明
testcholdout は、2 つの分類モデルの精度を統計的に評価します。この関数では、予測したラベルを真のラベルに対して比較してから、誤分類率の違いが統計的に有意であるかどうかを調べます。
複数の分類モデルの精度が異なるかどうかや、ある分類モデルの性能が別のモデルより優れているかどうかを評価できます。testcholdout では、漸近検定、厳密条件検定、mid-p 値検定など、いくつかのマクネマー検定のバリエーションを実行できます。コストを考慮する評価については、カイ二乗検定 (Optimization Toolbox™ のライセンスが必要) や尤度比検定などの検定を行うことできます。
h = testcholdout(YHat1,YHat2,Y,Name,Value)Name,Value ペア引数で指定された追加オプションを適用して行った仮説検定の結果を返します。たとえば、対立仮説のタイプ、検定のタイプ、コスト行列を指定できます。
例
入力引数
名前と値の引数
出力引数
詳細
"マクネマー検定" は、標本のペアに依存関係があることによって生じる問題に対処して 2 つの母集団比率を比較する仮説検定です。
2 つの分類モデルの予測精度を比較する方法の 1 つは、次のとおりです。
データを学習セットとテスト セットに分割します。
学習セットを使用して両方の分類モデルを学習させます。
テスト セットを使用してクラス ラベルを予測します。
次の図のような 2 x 2 の表に結果を要約します。
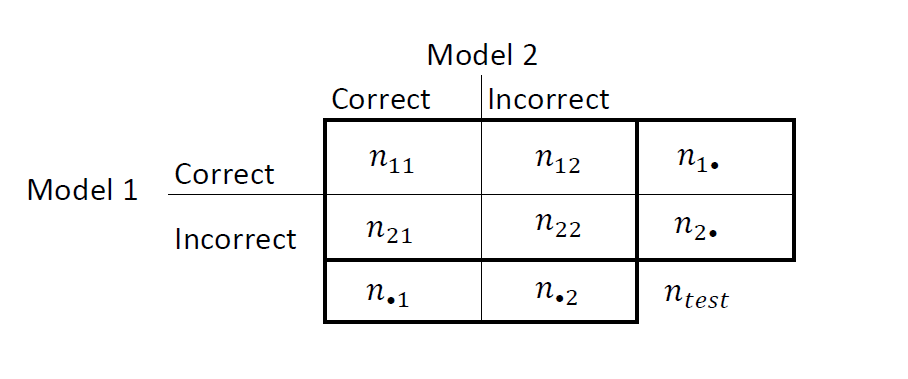
nii は、一致するペアの数、つまり両方のモデルで同じように (正しくまたは誤って) 分類される観測の数です。i ≠ j の場合の nij は、一致しないペアの数、つまりモデルでさまざまに (正しくまたは誤って) 分類される観測の数です。
モデル 1 および 2 の誤分類率は、それぞれ および です。2 つのモデルの精度を比較する両側検定は、次のようになります。
この帰無仮説は母集団の周辺確率が同等であることを示しているので、帰無仮説は に縮小されます。また、この帰無仮説では、N12 が (n12 + n21,0.5) の二項分布になります。[1]
以上は、マクネマー検定のバリエーションとして利用できる "漸近"、"厳密条件" および "mid-p 値" マクネマー検定の基礎となります。以下の定義は、利用可能なバリアントの概要です。
漸近 ― 漸近マクネマー検定の統計量と (有意水準 α に対する) 棄却域は、次のようになります。
片側検定の場合、検定統計量は次のようになります。
である場合 (Φ は標準ガウス累積分布関数)、H0 は棄却されます。
両側検定の場合、検定統計量は次のようになります。
である場合 ( は x で評価した χm2 累積分布関数)、H0 は棄却されます。
漸近検定では、大標本理論、具体的には二項分布に対するガウス近似が必要です。
厳密条件 — 厳密条件マクネマー検定の統計量と (有意水準 α に対する) 棄却域は、次のようになります ([4]、[5])。
片側検定の場合、検定統計量は次のようになります。
である場合 ( は x で評価した、標本サイズが n、成功確率が p の二項累積分布関数)、H0 は棄却されます。
両側検定の場合、検定統計量は次のようになります。
である場合、H0 は棄却されます。
厳密条件検定では、常にノミナル カバレッジが達成されます。シミュレーション研究[2]によると、この検定は保守的であり、他のバリアントに比べて統計的検出力が不足しています。検定標本が小規模な場合や非常に離散的な場合は、mid-p 値検定の使用を検討してください ([1], Ch. 3.6.3)。
mid-p 値検定 — mid-p 値マクネマー検定の統計量と (有意水準 α に対する) 棄却域は、次のようになります ([3])。
片側検定の場合、検定統計量は次のようになります。
である場合 ( と はそれぞれ x で評価した、標本サイズが n、成功確率が p の二項累積分布関数および二項確率密度関数)、H0 は棄却されます。
両側検定の場合、検定統計量は次のようになります。
である場合、H0 は棄却されます。
mid-p 値検定は、厳密条件検定の過度に保守的な挙動に対処します。シミュレーション研究[2]によると、この検定はノミナルの被覆が達成され、統計的検出力が優れています。
ヒント
予測したクラス ラベルを取得するには、学習済みの分類モデルと新しい予測子データを
predictメソッドに渡すことをお勧めします。たとえば、SVM モデルで予測したラベルについては、predictを参照してください。コストを考慮する検定では数値を最適化しますが、これには追加の計算リソースが必要です。尤度比検定では、ある区間におけるラグランジュ乗数の根を求めるため間接的に数値を最適化します。データ セットによっては、根が区間の境界付近にある場合、メソッドが失敗する可能性があります。このため、Optimization Toolbox のライセンスがある場合は、コストを考慮するカイ二乗検定を代わりに実行することを検討してください。詳細は、
CostTestおよびコストを考慮する検定を参照してください。
参照
バージョン履歴
R2015a で導入