testckfold
交差検証の反復により 2 つの分類モデルの精度を比較
構文
説明
testckfold は、反復的に 2 つの分類モデルの交差検証を行うことにより 2 つのモデルの精度を統計的に評価し、分類損失の差を求め、分類損失の差を結合して検定統計量を計算します。このタイプの検定は、標本サイズが制限されている場合に特に適しています。
複数の分類モデルの精度が異なるかどうかや、ある分類モデルの性能が別のモデルより優れているかどうかを評価できます。実行できる検定には、5 x 2 のペア t 検定、5 x 2 のペア F 検定、10 x 10 の反復交差 t 検定があります。詳細は、反復交差検証を参照してください。計算を高速化するため、testckfold は並列計算をサポートしています (Parallel Computing Toolbox™ のライセンスが必要)。
h = testckfold(C1,C2,X1,X2)X1 および X2 内の予測子および応答データを使用する真のクラス ラベルの予測において、分類モデル C1 および C2 の精度は等しい」です。h = 1 の場合、帰無仮説は 5% の有意水準で棄却されます。
testckfold は、C1 および C2 をそれぞれ X1 および X2 内のすべての予測子変数に適用することにより交差検証を実施します。X1 および X2 内の真のクラス ラベルは同じでなければなりません。X1、X2、C1.ResponseName および C2.ResponseName 内の応答変数名は同じでなければなりません。
モデルを比較する方法の例については、ヒントを参照してください。
h = testckfold(___,Name,Value)Name,Value ペア引数で指定された追加オプションを使用します。たとえば、対立仮説のタイプ、検定のタイプ、並列計算の使用を指定できます。
例
fitctree の既定設定では、網羅的探索を使用して、各ノードで分割に最適な予測子が選択されます。また、曲率検定を実施すると、応答が独立していないと考えられる予測子を分割することもできます。この例では、網羅的探索による最適分割によって成長させた分類木と、交互作用がある曲率検定の実施により成長させた分類木とを統計的に比較します。
census1994 データ セットを読み込みます。
load census1994.mat rng(1) % For reproducibility
学習セットのテーブル adultdata を使用して、既定の分類木を成長させます。応答変数名は 'salary' です。
C1 = fitctree(adultdata,'salary')C1 =
ClassificationTree
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
ResponseName: 'salary'
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
Properties, Methods
C1 は完全な ClassificationTree モデルです。このモデルの ResponseName プロパティは 'salary' です。C1 は、網羅的探索を使用し、最大の分割ゲインに基づいて分割に最適な予測子を求めます。
同じデータ セットを使用して、別の分類木を成長させます。この分類木では、交互作用がある曲率検定を使用して分割に最適な予測子を求めるよう指定します。
C2 = fitctree(adultdata,'salary','PredictorSelection','interaction-curvature')
C2 =
ClassificationTree
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
ResponseName: 'salary'
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
Properties, Methods
C2 も、ResponseName が 'salary' に等しい完全な ClassificationTree モデルです。
5 x 2 のペア F 検定を実施して、学習セットを使用した場合の 2 つのモデルの精度を比較します。データ セット内の応答変数名と ResponseName プロパティの応答変数名はすべて等しく、両方のセットの応答データが等しいので、応答データの指定を省略できます。
h = testckfold(C1,C2,adultdata,adultdata)
h = logical
0
h = 0 なので、C1 と C2 は精度が等しいという帰無仮説を 5% の水準で棄却することはできません。
5 x 2 のペア F 検定を使用して、2 つのモデルの誤分類率を比較する統計検定を実行します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris;既定のオプションを使用して、単純ベイズ テンプレートと分類木テンプレートを作成します。
C1 = templateNaiveBayes; C2 = templateTree;
C1 と C2 は、それぞれ単純ベイズ アルゴリズムと分類木アルゴリズムに対応するテンプレート オブジェクトです。
2 つのモデルの予測精度が同じであるかどうかを検定します。各モデルに同じ予測子データを使用します。既定では testckfold は 5 x 2 の両側ペア F 検定を実行します。
rng(1); % For reproducibility
h = testckfold(C1,C2,meas,meas,species)h = logical
0
h = 0 なので、2 つのモデルの予測精度が等しいという帰無仮説は棄却できません。
10 x 10 の反復交差 t 検定を使用して、単純なモデルの精度が複雑なモデルより高いかどうかを評価する統計検定を実行します。
フィッシャーのアヤメのデータ セットを読み込みます。setosa 種のアヤメを誤分類する場合、virginica 種のアヤメを versicolor 種として誤分類するコストの 2 倍をペナルティとするように、コスト行列を作成します。
load fisheriris;
tabulate(species) Value Count Percent
setosa 50 33.33%
versicolor 50 33.33%
virginica 50 33.33%
Cost = [0 2 2;2 0 1;2 1 0];
ClassNames = {'setosa' 'versicolor' 'virginica'};...
% Specifies the order of the rows and columns in Cost各クラスの経験分布は一様で、分類コストはわずかに不均衡です。
2 つの ECOC テンプレートを作成します。一方のテンプレートでは線形 SVM バイナリ学習器を、もう一方のテンプレートでは RBF カーネルがある SVM バイナリ学習器を使用します。
tSVMLinear = templateSVM('Standardize',true); % Linear SVM by default tSVMRBF = templateSVM('KernelFunction','RBF','Standardize',true); C1 = templateECOC('Learners',tSVMLinear); C2 = templateECOC('Learners',tSVMRBF);
C1 と C2 は ECOC テンプレート オブジェクトです。C1 は線形 SVM 用に、C2 は RBF カーネル学習がある SVM 用に準備されています。
分類コストに関して、単純なモデル (C1) の精度は複雑なモデル (C2) より高くないという帰無仮説を検定します。10 x 10 の反復交差検証を実行します。p 値と誤分類コストを返すように指定します。
rng(1); % For reproducibility [h,p,e1,e2] = testckfold(C1,C2,meas,meas,species,... 'Alternative','greater','Test','10x10t','Cost',Cost,... 'ClassNames',ClassNames)
h = logical
0
p = 0.1077
e1 = 10×10
0 0 0 0.0667 0 0.0667 0.1333 0 0.1333 0
0.0667 0.0667 0 0 0 0 0.0667 0 0.0667 0.0667
0 0 0 0 0 0.0667 0.0667 0.0667 0.0667 0.0667
0.0667 0.0667 0 0.0667 0 0.0667 0 0 0.0667 0
0.0667 0.0667 0.0667 0 0.0667 0.0667 0 0 0 0
0 0 0.1333 0 0 0.0667 0 0 0.0667 0.0667
0.0667 0.0667 0 0 0.0667 0 0 0.0667 0 0.0667
0.0667 0 0.0667 0.0667 0 0.1333 0 0.0667 0 0
0 0.0667 0.1333 0.0667 0.0667 0 0 0 0 0
0 0.0667 0.0667 0.0667 0.0667 0 0 0.0667 0 0
e2 = 10×10
0 0 0 0.1333 0 0.0667 0.1333 0 0.2667 0
0.0667 0.0667 0 0.1333 0 0 0 0.1333 0.1333 0.0667
0.1333 0.1333 0 0 0 0.0667 0 0.0667 0.0667 0.0667
0 0.1333 0 0.0667 0.1333 0.1333 0 0 0.0667 0
0.0667 0.0667 0.0667 0 0.0667 0.1333 0.1333 0 0 0.0667
0.0667 0 0.0667 0.0667 0 0.0667 0.1333 0 0.0667 0.0667
0.2000 0.0667 0 0 0.0667 0 0 0.1333 0 0.0667
0.2000 0 0 0.1333 0 0.1333 0 0.0667 0 0
0 0.0667 0.0667 0.0667 0.1333 0 0.2000 0 0 0
0.0667 0.0667 0 0.0667 0.1333 0 0 0.0667 0.1333 0.0667
p 値は、0.10 よりわずかに大きくなっています。これは、単純なモデルの精度が複雑なモデルと同程度であるという帰無仮説を棄却できないことを意味します。この結果は、最大 0.10 の有意水準 (Alpha) では変化しません。
e1 と e2 は、誤分類コストが含まれている 10 行 10 列の行列です。行 r は、反復交差検証の r 回目の実行に対応します。列 k は、特定の交差検証の実行における検定セットの分割 k に対応します。たとえば、e2 の要素 (2,4) は 0.1333 です。この値は、交差検証の 2 回目の実行において、検定セットが分割 4 のときに、検定セットの推定誤分類コストが 0.1333 であることを意味します。
予測子変数 (特徴量) のサブセットをより大きいセットから選択して、分類モデルの複雑さを減らします。そして、2 つのモデルの精度を統計的に比較します。
ionosphere データ セットを読み込みます。
load ionosphereAdaBoostM1 とすべての予測子セットを使用して、100 個のブースティング分類木があるアンサンブルを学習させます。各予測子について重要度を調べます。
t = templateTree('MaxNumSplits',1); % Weak-learner template tree object C = fitcensemble(X,Y,'Method','AdaBoostM1','Learners',t); predImp = predictorImportance(C); bar(predImp) h = gca; h.XTick = 1:2:h.XLim(2); title('Predictor Importances') xlabel('Predictor') ylabel('Importance measure')
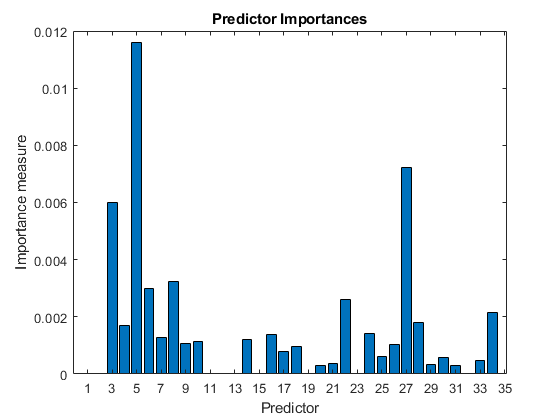
重要度が上位 5 番目までの予測子を識別します。
[~,idxSort] = sort(predImp,'descend');
idx5 = idxSort(1:5);2 つのモデルの予測精度が同じであるかどうかを検定します。縮小したデータ セットを指定してから、完全な予測子データを指定します。計算を高速化するため、並列計算を使用します。
s = RandStream('mlfg6331_64'); Options = statset('UseParallel',true,'Streams',s,'UseSubstreams',true); [h,p,e1,e2] = testckfold(C,C,X(:,idx5),X,Y,'Options',Options)
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
h = logical
0
p = 0.4161
e1 = 5×2
0.0686 0.0795
0.0800 0.0625
0.0914 0.0568
0.0400 0.0739
0.0914 0.0966
e2 = 5×2
0.0914 0.0625
0.1257 0.0682
0.0971 0.0625
0.0800 0.0909
0.0914 0.1193
testckfold では学習済みの分類モデルをテンプレートとして扱うので、C の当てはめたパラメーターはすべて無視されます。つまり、testckfold は、指定されたオプションと予測子データのみを使用して分割外の分類損失を推定することにより C の交差検証を実行します。
h = 0 なので、2 つのモデルの予測精度が等しいという帰無仮説は棄却できません。この結果から、単純なアンサンブルの方が有利であることがわかります。
入力引数
名前と値の引数
出力引数
詳細
ヒント
モデルを比較する方法の例には、次のようなものがあります。
同じ予測子データのセットを渡して、単純な分類モデルと複雑なモデルの精度を比較する。
2 つの異なる予測子のセットを使用して、2 つの異なるモデルの精度を比較する。
さまざまな特徴選択を実行する。たとえば、ある予測子のセットを使用して学習をさせたモデルの精度と、同じ予測子のサブセットまたは別の予測子のセットを使用して学習をさせたモデルの精度を比較できます。予測子のセットは自由に選択できます。また、PCA (
pca参照) や逐次特徴選択 (sequentialfs参照) などの特徴選択手法を使用することもできます。
次の両方が成り立つ場合、
Yの指定を省略できます。この場合、
testckfoldはテーブル内の共通する応答変数を使用します。コストを考慮しない特徴選択を実行する方法の 1 つとして、次のようなものがあります。
1 番目の分類モデル (
C1) の特性を示す分類モデル テンプレートを作成します。2 番目の分類モデル (
C2) の特性を示す分類モデル テンプレートを作成します。2 つの予測子データのセットを指定します。たとえば、完全な予測子セットとして
X1を、縮小したセットとしてX2を指定します。「
testckfold(C1,C2,X1,X2,Y,'Alternative','less')」と入力します。testckfoldが1を返した場合、少ない予測子を使用する分類モデルは完全な予測子セットを使用する分類モデルより性能が優れていることを示す十分な証拠があることになります。
あるいは、2 つのモデルの精度に有意な差があるかどうかを評価することもできます。この評価を実行するには、手順 4 から
'Alternative','less'の指定を削除します。testckfoldでは両側検定が実行されます。h = 0の場合、2 つのモデルの精度に差があることを示す十分な証拠がないことになります。これらの検定は誤分類率の分類損失に適していますが、他の損失関数 (
LossFun参照) を指定することもできます。重要な仮定として、両側検定の帰無仮説において、推定した分類損失は独立しており、平均が 0 で有限の一般分散をもつ正規分布になっている必要があります。誤分類率以外の分類損失は、この仮定に違反する可能性があります。非常に離散的なデータ、不均衡なクラス、および非常に不均衡なコスト行列は、分類損失の差の計算における正規性の仮定に違反する可能性があります。
アルゴリズム
'Test','10x10t' を使用して 10 x 10 の反復交差 t 検定を実行するように指定した場合、testckfold は t 分布の自由度 10 を使用して棄却限界領域の検出と p 値を推定します。詳細は、[2]および[3]を参照してください。
代替方法
次の場合に testcholdout を使用します。
テスト セットの標本サイズが大きい。
マクネマー検定のバリアントを実装して 2 つの分類モデルの精度を比較する。
カイ二乗検定または尤度比検定による、コストを考慮する検定。カイ二乗検定では
quadprog(Optimization Toolbox) を使用しますが、これには Optimization Toolbox™ のライセンスが必要です。
参照
[1] Alpaydin, E. “Combined 5 x 2 CV F Test for Comparing Supervised Classification Learning Algorithms.” Neural Computation, Vol. 11, No. 8, 1999, pp. 1885–1992.
[2] Bouckaert. R. “Choosing Between Two Learning Algorithms Based on Calibrated Tests.” International Conference on Machine Learning, 2003, pp. 51–58.
[3] Bouckaert, R., and E. Frank. “Evaluating the Replicability of Significance Tests for Comparing Learning Algorithms.” Advances in Knowledge Discovery and Data Mining, 8th Pacific-Asia Conference, 2004, pp. 3–12.
[4] Dietterich, T. “Approximate statistical tests for comparing supervised classification learning algorithms.” Neural Computation, Vol. 10, No. 7, 1998, pp. 1895–1923.
[5] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, 2nd Ed. New York: Springer, 2008.