templateECOC
誤り訂正出力符号学習器のテンプレート
説明
t = templateECOC(Name,Value)
たとえば、符号化設計の指定、事後確率を当てはめるかどうかの指定、バイナリ学習器のタイプの指定を行うことができます。
コマンド ウィンドウに t を表示する場合、すべてのオプションは、名前と値のペア引数を使用して指定する場合を除き、空 ([]) で表示されます。学習中、空のオプションに既定値が使用されます。
例
templateECOC を使用して既定の ECOC テンプレートを作成します。
t = templateECOC()
t =
Fit template for classification ECOC.
BinaryLearners: ''
Coding: ''
FitPosterior: []
Options: []
VerbosityLevel: []
NumConcurrent: []
Version: 1
Method: 'ECOC'
Type: 'classification'
Method と Type を除き、テンプレート オブジェクトのすべてのプロパティは空です。t を testckfold に渡すと、空のプロパティにはそれぞれの既定値が設定されます。たとえば、BinaryLearners プロパティは、'SVM' で入力されます。他の既定値の詳細は、fitcecocを参照してください。
t は ECOC 学習器の計画です。これを作成しても、何も計算されません。t を testckfold に渡すと、ECOC 分類モデルを他のモデルと統計的に比較するための計画を指定できます。
予測子または特徴量を選択する方法として、2 つのモデルを学習させます。一方のモデルの学習に使用した予測子のサブセットをもう一方のモデルにも使用します。モデルの予測性能を統計的に比較します。少ない予測子で学習させたモデルの方が多くの予測子で学習させたモデルより性能が高いことを示す十分な証拠がある場合、以後は効率的な方のモデルを使用できます。
フィッシャーのアヤメのデータ セットを読み込みます。2 次元の予測子の組み合わせをすべてプロットします。
load fisheriris d = size(meas,2); % Number of predictors pairs = nchoosek(1:d,2)
pairs = 6×2
1 2
1 3
1 4
2 3
2 4
3 4
for j = 1:size(pairs,1) subplot(3,2,j) gscatter(meas(:,pairs(j,1)),meas(:,pairs(j,2)),species) xlabel(sprintf('meas(:,%d)',pairs(j,1))) ylabel(sprintf('meas(:,%d)',pairs(j,2))) legend off end
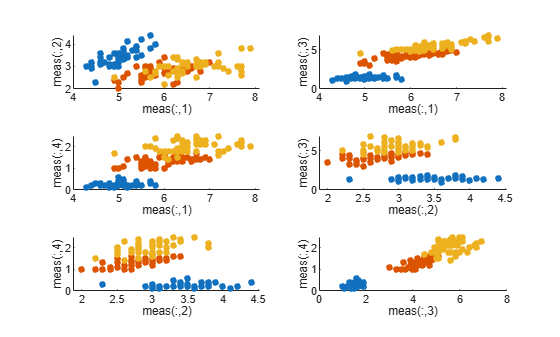
この散布図では、meas(:,3) と meas(:,4) がグループを十分に分離しているように見えます。
ECOC テンプレートを作成します。1 対他の符号化設計を使用するように指定します。
t = templateECOC('Coding','onevsall');
既定の設定では、ECOC モデルは線形 SVM バイナリ学習器を使用します。'Learners' の名前と値のペアの引数によって指定すると、サポートされている他のアルゴリズムを選択できます。
予測子 3 および 4 のみを使用して学習させた ECOC モデルが、すべての予測子を使用して学習させた ECOC モデルと同程度以下の性能であるかどうかを検定します。この帰無仮説が棄却されると、予測子 3 および 4 のみを使用して学習させた ECOC モデルが、すべての予測子を使用して学習させた ECOC モデルより性能が高いことが示されます。予測子 3 および 4 を使用して学習をさせた ECOC モデルの分類誤差を 、すべての予測子を使用して学習をさせた ECOC モデルの分類誤差を で表すと、検定は次のようになります。
既定の設定では testckfold は 5 x 2 の k 分割 F 検定を実行しますが、これは片側検定に適していません。5 x 2 の k 分割 t 検定を実行するように指定します。
rng(1); % For reproducibility [h,pValue] = testckfold(t,t,meas(:,pairs(6,:)),meas,species,... 'Alternative','greater','Test','5x2t')
h = logical
0
pValue = 0.8940
h = 0 なので、予測子 3 および 4 を使用して学習させたモデルが、すべての予測子を使用して学習させたモデルより精度が高いことを示す十分な証拠はありません。
名前と値の引数
出力引数
アルゴリズム
参照
バージョン履歴
R2015a で導入