templateTree
決定木テンプレートの作成
説明
t = templateTreet を指定します。
アンサンブル分類の場合は
fitcensembleアンサンブル回帰の場合は
fitrensembleECOC モデル分類の場合は
fitcecoc
既定の決定木テンプレートを指定する場合、学習中にすべての入力引数の既定値が使用されます。決定木の型を指定することをお勧めします。たとえば分類木テンプレートには'Type','classification' を指定します。決定木の型を指定し、コマンド ウィンドウに t を表示する場合、Type を除くすべてのオプションは空 ([]) で表示されます。
t = templateTree(Name,Value)
たとえば、カテゴリカル予測子での最適な分割を検出するためのアルゴリズム、分割基準、分割ごとに選択する予測子の数などを指定できます。
コマンド ウィンドウに t を表示する場合、すべてのオプションは、名前と値のペア引数を使用して指定する場合を除き、空 ([]) で表示されます。学習中、空のオプションに既定値が使用されます。
例
代理分岐により決定木テンプレートを作成し、このテンプレートを使用して標本データによるアンサンブル学習を実行します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris代理分岐を使用する木の切り株の決定木テンプレートを作成します。
t = templateTree('Surrogate','on','MaxNumSplits',1)
t =
Fit template for Tree.
Surrogate: 'on'
MaxNumSplits: 1
テンプレート オブジェクトのオプションは、Surrogate と MaxNumSplits 以外は空です。t を学習関数に渡す場合、空のオプションはそれぞれの既定値で入力されます。
t をアンサンブル分類の弱学習器として指定します。
Mdl = fitcensemble(meas,species,'Method','AdaBoostM2','Learners',t)
Mdl =
ClassificationEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
NumTrained: 100
Method: 'AdaBoostM2'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [100×1 double]
FitInfoDescription: {2×1 cell}
Properties, Methods
標本内 (再代入) 誤分類誤差を表示します。
L = resubLoss(Mdl)
L = 0.0333
十分な予測性能をもつブースティング回帰木のアンサンブルを作成する方法の 1 つは、交差検証を使用して決定木の複雑度レベルを調整することです。最適な複雑度レベルを求めるときに、学習率を調整して学習サイクル数の最小化も行います。
この例では、交差検証オプション (名前と値のペアの引数 'KFold') と関数 kfoldLoss を使用して、最適なパラメーターを手動で求めます。あるいは、名前と値のペアの引数 'OptimizeHyperparameters' を使用して自動的にハイパーパラメーターを最適化することもできます。アンサンブル回帰の最適化を参照してください。
carsmall データ セットを読み込みます。燃費の予測子として、気筒数、気筒ごとの排気量、馬力、重量を選択します。
load carsmall
Tbl = table(Cylinders,Displacement,Horsepower,Weight,MPG);回帰木をブースティングする場合、木の深さの制御に関する既定値は次のとおりです。
MaxNumSplitsは10。MinLeafSizeは5MinParentSizeは10
最適な木の複雑度レベルを求めるため、以下を行います。
一連のアンサンブルを交差検証します。以後のアンサンブルについて、決定株 (1 つの分割) から最大 n - 1 個の分割まで木の複雑度レベルを指数的に増やします。n は標本サイズです。また、各アンサンブル学習率を 0.1 から 1 までの間で変化させます。
アンサンブルごとに交差検証の平均二乗誤差 (MSE) を推定します。
木の複雑度レベル () について、学習サイクル数に対してプロットすることにより、アンサンブルの交差検証済み累積 MSE を比較します。同じ Figure に、各学習率に対応する別々の曲線をプロットします。
MSE が最小になる曲線を選択し、対応する学習サイクルおよび学習率に注目します。
深い回帰木と切り株を交差検証します。欠損値がデータに含まれているので、代理分岐を使用します。これらの回帰木は基準として機能します。
rng(1) % For reproducibility MdlDeep = fitrtree(Tbl,'MPG','CrossVal','on','MergeLeaves','off', ... 'MinParentSize',1,'Surrogate','on'); MdlStump = fitrtree(Tbl,'MPG','MaxNumSplits',1,'CrossVal','on', ... 'Surrogate','on');
5 分割の交差検証を使用して、150 本のブースティング回帰木のアンサンブルを交差検証します。木テンプレートを使用して、以下を行います。
という数列の値を使用して分割の最大数を変化させます。m は、 が n - 1 を超えない値です。
代理分岐を有効にします。
{0.1, 0.25, 0.5, 1} という集合の各値を使用して、それぞれの学習率を調整します。
n = size(Tbl,1); m = floor(log2(n - 1)); learnRate = [0.1 0.25 0.5 1]; numLR = numel(learnRate); maxNumSplits = 2.^(0:m); numMNS = numel(maxNumSplits); numTrees = 150; Mdl = cell(numMNS,numLR); for k = 1:numLR for j = 1:numMNS t = templateTree('MaxNumSplits',maxNumSplits(j),'Surrogate','on'); Mdl{j,k} = fitrensemble(Tbl,'MPG','NumLearningCycles',numTrees, ... 'Learners',t,'KFold',5,'LearnRate',learnRate(k)); end end
各アンサンブルの交差検証済み累積 MSE を推定します。
kflAll = @(x)kfoldLoss(x,'Mode','cumulative'); errorCell = cellfun(kflAll,Mdl,'Uniform',false); error = reshape(cell2mat(errorCell),[numTrees numel(maxNumSplits) numel(learnRate)]); errorDeep = kfoldLoss(MdlDeep); errorStump = kfoldLoss(MdlStump);
アンサンブル内の木の本数が増加すると交差検証済み MSE がどのように変化するかをプロットします。同じプロットに学習率ごとの曲線をプロットし、木の複雑度レベルを変えた別のプロットをそれぞれ作成します。木の複雑度レベルからプロット対象となるサブセットを選択します。
mnsPlot = [1 round(numel(maxNumSplits)/2) numel(maxNumSplits)]; figure; for k = 1:3 subplot(2,2,k) plot(squeeze(error(:,mnsPlot(k),:)),'LineWidth',2) axis tight hold on h = gca; plot(h.XLim,[errorDeep errorDeep],'-.b','LineWidth',2) plot(h.XLim,[errorStump errorStump],'-.r','LineWidth',2) plot(h.XLim,min(min(error(:,mnsPlot(k),:))).*[1 1],'--k') h.YLim = [10 50]; xlabel('Number of trees') ylabel('Cross-validated MSE') title(sprintf('MaxNumSplits = %0.3g', maxNumSplits(mnsPlot(k)))) hold off end hL = legend([cellstr(num2str(learnRate','Learning Rate = %0.2f')); ... 'Deep Tree';'Stump';'Min. MSE']); hL.Position(1) = 0.6;
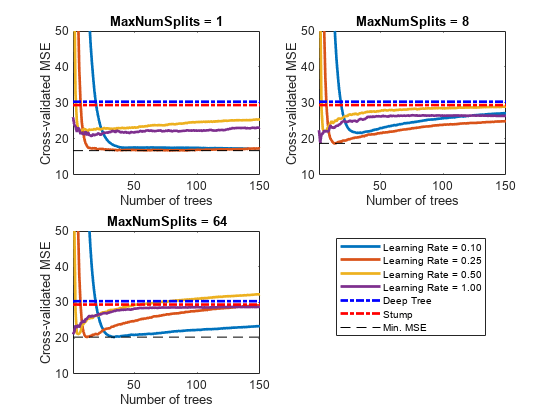
各曲線では、アンサンブル内の木の本数が最適な位置で交差検証の MSE が最小になります。
全体的に MSE が最小になる最大分割数、木の数および学習率を特定します。
[minErr,minErrIdxLin] = min(error(:));
[idxNumTrees,idxMNS,idxLR] = ind2sub(size(error),minErrIdxLin);
fprintf('\nMin. MSE = %0.5f',minErr)Min. MSE = 16.77593
fprintf('\nOptimal Parameter Values:\nNum. Trees = %d',idxNumTrees);Optimal Parameter Values: Num. Trees = 78
fprintf('\nMaxNumSplits = %d\nLearning Rate = %0.2f\n',... maxNumSplits(idxMNS),learnRate(idxLR))
MaxNumSplits = 1 Learning Rate = 0.25
最適なハイパーパラメーターおよび学習セット全体に基づいて予測アンサンブルを作成します。
tFinal = templateTree('MaxNumSplits',maxNumSplits(idxMNS),'Surrogate','on'); MdlFinal = fitrensemble(Tbl,'MPG','NumLearningCycles',idxNumTrees, ... 'Learners',tFinal,'LearnRate',learnRate(idxLR))
MdlFinal =
RegressionEnsemble
PredictorNames: {'Cylinders' 'Displacement' 'Horsepower' 'Weight'}
ResponseName: 'MPG'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
NumTrained: 78
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [78×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
MdlFinal は RegressionEnsemble です。与えられた気筒数、全気筒の排気量、馬力、重量に対して燃費を予測するため、予測子データと MdlFinal を predict に渡すことができます。
交差検証オプション ('KFold') と関数 kfoldLoss を使用して最適な値を手動で求める代わりに、名前と値のペアの引数 'OptimizeHyperparameters' を使用できます。'OptimizeHyperparameters' を指定すると、ベイズ最適化を使用して、最適なパラメーターが自動的に求められます。'OptimizeHyperparameters' を使用して取得した最適な値は、手動で求めたものと異なる可能性があります。
t = templateTree('Surrogate','on'); mdl = fitrensemble(Tbl,'MPG','Learners',t, ... 'OptimizeHyperparameters',{'NumLearningCycles','LearnRate','MaxNumSplits'})
|====================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits |
| | result | log(1+loss) | runtime | (observed) | (estim.) | ycles | | |
|====================================================================================================================|
| 1 | Best | 3.3955 | 0.36088 | 3.3955 | 3.3955 | 26 | 0.072054 | 3 |
| 2 | Accept | 6.0976 | 0.6851 | 3.3955 | 3.5549 | 170 | 0.0010295 | 70 |
| 3 | Best | 3.2914 | 0.80048 | 3.2914 | 3.2917 | 273 | 0.61026 | 6 |
| 4 | Accept | 6.1839 | 0.18262 | 3.2914 | 3.2915 | 80 | 0.0016871 | 1 |
| 5 | Best | 3.0379 | 0.13909 | 3.0379 | 3.0384 | 18 | 0.21288 | 37 |
| 6 | Accept | 3.052 | 0.13395 | 3.0379 | 3.0401 | 28 | 0.18021 | 14 |
| 7 | Accept | 3.1721 | 0.26985 | 3.0379 | 3.0374 | 62 | 0.23151 | 26 |
| 8 | Accept | 3.059 | 0.083066 | 3.0379 | 3.0438 | 10 | 0.25885 | 23 |
| 9 | Accept | 3.4008 | 0.076308 | 3.0379 | 3.0737 | 10 | 0.98355 | 19 |
| 10 | Accept | 3.292 | 0.067188 | 3.0379 | 3.1221 | 10 | 0.19202 | 16 |
| 11 | Accept | 6.1314 | 0.061305 | 3.0379 | 3.1185 | 10 | 0.015655 | 14 |
| 12 | Accept | 3.8518 | 0.060778 | 3.0379 | 3.0368 | 10 | 0.1381 | 13 |
| 13 | Best | 3.0143 | 0.066383 | 3.0143 | 3.0101 | 11 | 0.42156 | 8 |
| 14 | Best | 2.9247 | 0.259 | 2.9247 | 2.9256 | 139 | 0.071377 | 1 |
| 15 | Accept | 2.9286 | 0.15802 | 2.9247 | 2.9239 | 75 | 0.09247 | 1 |
| 16 | Accept | 3.0862 | 0.15809 | 2.9247 | 2.926 | 69 | 0.9448 | 1 |
| 17 | Accept | 3.1311 | 0.11234 | 2.9247 | 2.9247 | 22 | 0.36025 | 16 |
| 18 | Best | 2.9037 | 0.30817 | 2.9037 | 2.9036 | 133 | 0.10959 | 1 |
| 19 | Accept | 3.1948 | 0.088969 | 2.9037 | 2.9038 | 19 | 0.63655 | 12 |
| 20 | Accept | 3.2142 | 0.70346 | 2.9037 | 2.9038 | 483 | 0.98259 | 1 |
|====================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits |
| | result | log(1+loss) | runtime | (observed) | (estim.) | ycles | | |
|====================================================================================================================|
| 21 | Accept | 2.9181 | 0.22092 | 2.9037 | 2.9054 | 138 | 0.088444 | 1 |
| 22 | Accept | 2.9255 | 0.16826 | 2.9037 | 2.9062 | 87 | 0.12507 | 1 |
| 23 | Accept | 3.1468 | 1.8382 | 2.9037 | 2.9061 | 494 | 0.043654 | 19 |
| 24 | Accept | 2.927 | 0.18157 | 2.9037 | 2.9055 | 101 | 0.05203 | 1 |
| 25 | Accept | 2.9211 | 0.15202 | 2.9037 | 2.9056 | 87 | 0.06514 | 1 |
| 26 | Accept | 2.9208 | 0.27716 | 2.9037 | 2.9076 | 106 | 0.10431 | 1 |
| 27 | Accept | 2.9084 | 0.78328 | 2.9037 | 2.9067 | 497 | 0.1341 | 1 |
| 28 | Best | 2.8925 | 0.42159 | 2.8925 | 2.8926 | 271 | 0.11251 | 1 |
| 29 | Accept | 2.9079 | 0.45784 | 2.8925 | 2.8926 | 230 | 0.1407 | 1 |
| 30 | Accept | 2.8948 | 0.84887 | 2.8925 | 2.8912 | 495 | 0.090942 | 1 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 24.5081 seconds
Total objective function evaluation time: 10.1247
Best observed feasible point:
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
271 0.11251 1
Observed objective function value = 2.8925
Estimated objective function value = 2.8912
Function evaluation time = 0.42159
Best estimated feasible point (according to models):
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
271 0.11251 1
Estimated objective function value = 2.8912
Estimated function evaluation time = 0.47434

mdl =
RegressionEnsemble
PredictorNames: {'Cylinders' 'Displacement' 'Horsepower' 'Weight'}
ResponseName: 'MPG'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
NumTrained: 271
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [271×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
carsmall データ セットを読み込みます。与えられた加速、気筒数、エンジン排気量、馬力、製造業者、モデル年および重量に対して自動車の燃費の平均を予測するモデルを考えます。Cylinders、Mfg および Model_Year はカテゴリカル変数であるとします。
load carsmall Cylinders = categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg,... Model_Year,Weight,MPG);
カテゴリカル変数で表現されるカテゴリの個数を表示します。
numCylinders = numel(categories(Cylinders))
numCylinders = 3
numMfg = numel(categories(Mfg))
numMfg = 28
numModelYear = numel(categories(Model_Year))
numModelYear = 3
Cylinders と Model_Year には 3 つしかカテゴリがないので、予測子分割アルゴリズムの標準 CART ではこの 2 つの変数よりも連続予測子が分割されます。
データ セット全体を使用して、500 本の回帰木のランダム フォレストに学習をさせます。偏りの無い木を成長させるため、予測子の分割に曲率検定を使用するよう指定します。データには欠損値が含まれているので、代理分岐を使用するよう指定します。無作為な予測子の選択を再現するため、rng を使用して乱数発生器のシードを設定し、'Reproducible',true を指定します。
rng('default'); % For reproducibility t = templateTree('PredictorSelection','curvature','Surrogate','on', ... 'Reproducible',true); % For reproducibility of random predictor selections Mdl = fitrensemble(X,'MPG','Method','bag','NumLearningCycles',500, ... 'Learners',t);
out-of-bag 観測値を並べ替えることにより、予測子の重要度の尺度を推定します。並列計算を実行します。
options = statset('UseParallel',true); imp = oobPermutedPredictorImportance(Mdl,'Options',options);
Starting parallel pool (parpool) using the 'Processes' profile ... 18-Aug-2025 13:34:21: Job Running. Waiting for parallel pool workers to connect ... Connected to parallel pool with 6 workers.
棒グラフを使用して推定を比較します。
figure; bar(imp); title('Out-of-Bag Permuted Predictor Importance Estimates'); ylabel('Estimates'); xlabel('Predictors'); h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none';

このケースでは、最も重要な予測子は Model_Year であり、次に重要なのは Cylinders です。これらの結果を予測子の重要度の推定の結果と比較します。
fitcecocで使用するためのアンサンブル テンプレートを作成します。
不整脈データ セットを読み込みます。
load arrhythmia
tabulate(categorical(Y)); Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
rng(1); % For reproducibility一部のクラスでは、データ内の相対的頻度が小さいです。
分類木の AdaBoostM1 アンサンブルに対するテンプレートを作成し、100 個の学習器および 0.1 という縮小を使用するよう指定します。既定の設定では、ブースティングは切り株 (たとえば葉のセットをもつ 1 つのノード) を成長させます。頻度の小さいクラスがあるので、少数のクラスが十分な感度をもつように、ツリーのリーフ数を多くしなければなりません。葉ノードの観測値の最小数を 3 に指定します。
tTree = templateTree('MinLeafSize',20); t = templateEnsemble('AdaBoostM1',100,tTree,'LearnRate',0.1);
Method と Type および関数呼び出し内の名前と値のペア引数の対応するプロパティを除き、テンプレート オブジェクトのすべてのプロパティは空です。t を学習関数に渡す場合、空のプロパティはそれぞれの既定値で入力されます。
t を ECOC マルチクラス モデルのバイナリ学習器として指定します。既定の 1 対 1 の 符号化設計を使用して学習させます。
Mdl = fitcecoc(X,Y,'Learners',t);MdlはClassificationECOCマルチクラス モデルです。Mdl.BinaryLearnersはCompactClassificationEnsembleモデルの 78 行 1 列の cell 配列です。Mdl.BinaryLearners{j}.Trainedは、j= 1,...,78 の場合にCompactClassificationTreeモデルの 100 行 1 列の cell 配列です。
view を使用して、バイナリ学習器のいずれかが、切り株ではない弱学習器を含むことを検証できます。
view(Mdl.BinaryLearners{1}.Trained{1},'Mode','graph')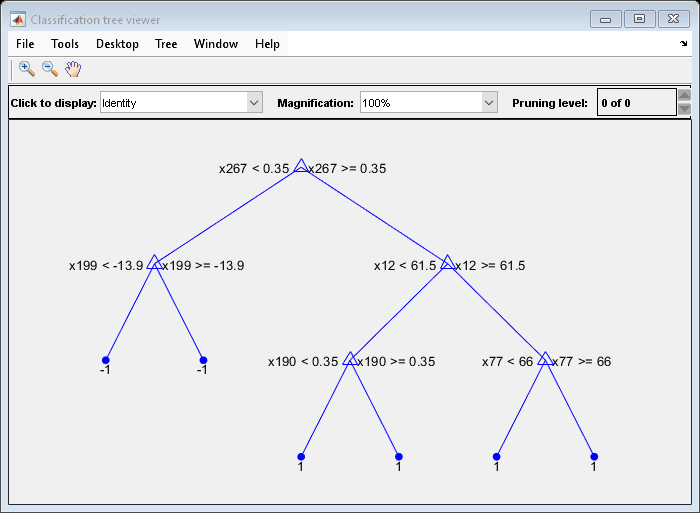
標本内 (再代入) 誤分類誤差を表示します。
L = resubLoss(Mdl,'LossFun','classiferror')
L = 0.0819
名前と値の引数
出力引数
アルゴリズム
MaxNumSplitsに対応するため、現在の "レイヤー" に含まれているすべてのノードを分割してから枝ノードの数をカウントします。レイヤーとは、ルート ノードから同じ距離にあるノードの集合です。枝ノードの数がMaxNumSplitsを超えた場合、以下の処理が行われます。現在のレイヤーに含まれている枝ノード数が、最大でも
MaxNumSplitsになるように、分割を解除する数を判断する。不純度順に枝ノードを並べ替える。
適切ではない分岐の分割を解除する。
それまでに成長させた決定木を返す。
この手順は、バランスが最大の木を生成することを目指しています。
次の条件のいずれかが満たされるまで、枝ノードをレイヤー単位で分割します。
MaxNumSplits+ 1 個の枝ノードが存在している。推奨されている分割を行うと、少なくとも 1 つの枝ノードで観測値の数が
MinParentSizeより少なくなる。推奨される分割を行うと、少なくとも 1 つの葉ノードで観測値の数が
MinLeafSizeより少なくなる。レイヤー内で適切な分割を検出できない。つまり、現在の枝刈り基準 (
PruneCriterion参照) では、レイヤー内で推奨されている分割を行っても状況が改善されない。このイベントの特殊なケースは、すべてのノードが純粋 (ノード内のすべての観測値が同じクラス) になる場合です。PredictorSelectionの値が'curvature'または'interaction-curvature'の場合に、すべての検定で p 値が 0.05 を超える。
MaxNumSplitsとMinLeafSizeは、既定値で行われる分割に影響を与えません。'MaxNumSplits'を設定した場合、MaxNumSplits回の分割が発生する前に、MinParentSizeの値が原因となって分割が停止することもあります。決定木を成長させるときの分割予測子の選択とノード分割アルゴリズムの詳細については、分類木の場合はアルゴリズムを、回帰木の場合はアルゴリズムを参照してください。
参照
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
[2] Coppersmith, D., S. J. Hong, and J. R. M. Hosking. “Partitioning Nominal Attributes in Decision Trees.” Data Mining and Knowledge Discovery, Vol. 3, 1999, pp. 197–217.
[3] Loh, W.Y. “Regression Trees with Unbiased Variable Selection and Interaction Detection.” Statistica Sinica, Vol. 12, 2002, pp. 361–386.
[4] Loh, W.Y. and Y.S. Shih. “Split Selection Methods for Classification Trees.” Statistica Sinica, Vol. 7, 1997, pp. 815–840.
バージョン履歴
R2014a で導入