templateEnsemble
アンサンブル学習テンプレート
構文
説明
例
templateEnsemble を使用して、アンサンブル学習テンプレートを指定します。アンサンブル法、学習サイクルの数、弱学習器の型を指定しなければなりません。たとえば、AdaBoostM1 法、100 個の学習器および分類木弱学習器を指定します。
t = templateEnsemble('AdaBoostM1',100,'tree')
t =
Fit template for classification AdaBoostM1.
Type: 'classification'
Method: 'AdaBoostM1'
LearnerTemplates: 'Tree'
NLearn: 100
LearnRate: []
Method、TypeLearnerTemplates および NLearn を除き、テンプレート オブジェクトのすべてのプロパティは空です。学習の際、空のプロパティはそれぞれの既定値で入力されます。たとえば、LearnRate プロパティは、1 で入力されます。
t はアンサンブル学習器の計画で、それを指定する場合、計算は実行されません。t をfitcecocに渡して、ECOC マルチクラス学習のアンサンブル バイナリ学習器を指定できます。
fitcecocで使用するためのアンサンブル テンプレートを作成します。
不整脈データ セットを読み込みます。
load arrhythmia
tabulate(categorical(Y)); Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
rng(1); % For reproducibility一部のクラスでは、データ内の相対的頻度が小さいです。
分類木の AdaBoostM1 アンサンブルに対するテンプレートを作成し、100 個の学習器および 0.1 という縮小を使用するよう指定します。既定の設定では、ブースティングは切り株 (たとえば葉のセットをもつ 1 つのノード) を成長させます。頻度の小さいクラスがあるので、少数のクラスが十分な感度をもつように、ツリーのリーフ数を多くしなければなりません。葉ノードの観測値の最小数を 3 に指定します。
tTree = templateTree('MinLeafSize',20); t = templateEnsemble('AdaBoostM1',100,tTree,'LearnRate',0.1);
Method と Type および関数呼び出し内の名前と値のペア引数の対応するプロパティを除き、テンプレート オブジェクトのすべてのプロパティは空です。t を学習関数に渡す場合、空のプロパティはそれぞれの既定値で入力されます。
t を ECOC マルチクラス モデルのバイナリ学習器として指定します。既定の 1 対 1 の 符号化設計を使用して学習させます。
Mdl = fitcecoc(X,Y,'Learners',t);MdlはClassificationECOCマルチクラス モデルです。Mdl.BinaryLearnersはCompactClassificationEnsembleモデルの 78 行 1 列の cell 配列です。Mdl.BinaryLearners{j}.Trainedは、j= 1,...,78 の場合にCompactClassificationTreeモデルの 100 行 1 列の cell 配列です。
view を使用して、バイナリ学習器のいずれかが、切り株ではない弱学習器を含むことを検証できます。
view(Mdl.BinaryLearners{1}.Trained{1},'Mode','graph')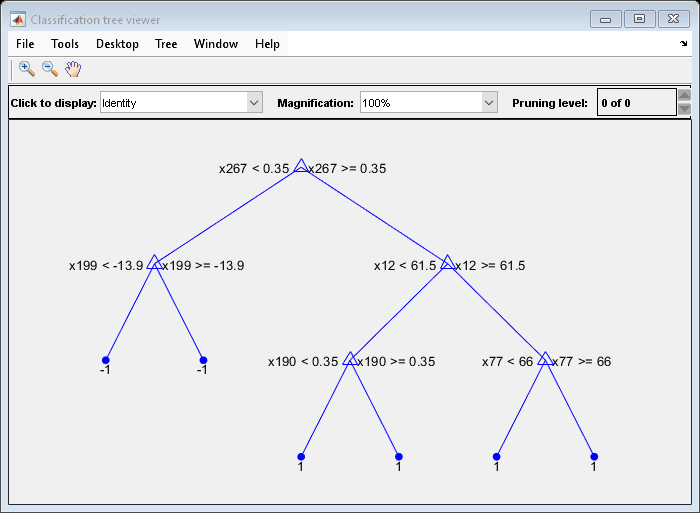
標本内 (再代入) 誤分類誤差を表示します。
L = resubLoss(Mdl,'LossFun','classiferror')
L = 0.0819
代理分岐をもつ決定木の GentleBoost アンサンブルを使用して、1 対他の ECOC 分類器に学習をさせます。学習を高速化するため、数値予測子をビン化し、並列計算を使用します。ビン化は、fitcecoc が木学習器を使用する場合のみ有効です。学習後、10 分割交差検証を使用して分類誤差を推定します。並列計算には Parallel Computing Toolbox™ が必要であることに注意してください。
標本データの読み込み
arrhythmia データ セットを読み込み検証します。
load arrhythmia
[n,p] = size(X)n = 452
p = 279
isLabels = unique(Y); nLabels = numel(isLabels)
nLabels = 13
tabulate(categorical(Y))
Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
このデータ セットには 279 個の予測子が含まれ、452 という標本サイズは相対的に小さいものです。16 個の異なるラベルのうち、13 個のみが応答 (Y) で表現されています。各ラベルは不整脈のさまざまな段階を表しており、観測値の 54.20% がクラス 1 に含まれています。
1 対他 ECOC 分類器の学習
アンサンブル テンプレートを作成します。少なくとも 3 つの引数を指定しなければなりません。手法、学習器の数、および学習器のタイプです。この例では、手法として 'GentleBoost'、学習器の個数として 100 を指定します。欠損観測値があるので、代理分岐を使用する決定木テンプレートを指定します。
tTree = templateTree('surrogate','on'); tEnsemble = templateEnsemble('GentleBoost',100,tTree);
tEnsemble はテンプレート オブジェクトです。ほとんどのプロパティは空ですが、学習中に既定値が入力されます。
決定木のアンサンブルをバイナリ学習器として使用して、1 対他の ECOC 分類器を学習させます。学習を高速化するため、ビン化と並列計算を使用します。
ビン化 (
'NumBins',50) — 学習データ セットが大きい場合、名前と値のペアの引数'NumBins'を使用することにより学習を高速化できます (精度が低下する可能性があります)。この引数は、fitcecocが木学習器を使用する場合のみ有効です。'NumBins'の値を指定した場合、指定した個数の同確率のビンにすべての数値予測子がビン化され、元のデータではなくビンのインデックスに対して木が成長します。はじめに'NumBins',50を試してから、精度と学習速度に応じて'NumBins'の値を変更できます。並列計算 (
'Options',statset('UseParallel',true)) — Parallel Computing Toolbox のライセンスがある場合、プール内のワーカーに各バイナリ学習器を送る並列計算を使用して、計算を高速化できます。ワーカーの個数はシステム構成によって異なります。デュアルコア以上のシステムの場合、バイナリ学習器について決定木を使用すると、fitcecocは Intel® スレッディング ビルディング ブロック (TBB) を使用して学習を並列化します。したがって、単一のコンピューターで'UseParallel'オプションを指定しても役に立ちません。このオプションは、クラスターに対して使用します。
さらに、事前確率として 1/K を指定します。K = 13 は異なるクラスの個数です。
options = statset('UseParallel',true); Mdl = fitcecoc(X,Y,'Coding','onevsall','Learners',tEnsemble,... 'Prior','uniform','NumBins',50,'Options',options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Mdl は ClassificationECOC モデルです。
交差検証
10 分割交差検証を使用して ECOC 分類器の交差検証を実行します。
CVMdl = crossval(Mdl,'Options',options);Warning: One or more folds do not contain points from all the groups.
CVMdl は ClassificationPartitionedECOC モデルです。少なくとも 1 つの分割の学習中に、いくつかのクラスが表示されないことが警告でわかります。したがって、これらの分割は欠損クラスに対するラベルを予測できません。cell のインデックス指定とドット表記を使用して、分割の結果を調査できます。たとえば、1 番目の分割の結果にアクセスするには CVMdl.Trained{1} と入力します。
交差検証済みの ECOC 分類器を使用して、検証分割のラベルを予測します。混同行列は、confusionchart を使用して計算できます。内側の位置のプロパティを変更してチャートを移動およびサイズ変更することにより、行要約の内部にパーセントが表示されるようにします。
oofLabel = kfoldPredict(CVMdl,'Options',options); ConfMat = confusionchart(Y,oofLabel,'RowSummary','total-normalized'); ConfMat.InnerPosition = [0.10 0.12 0.85 0.85];

ビン化されたデータの再現
学習済みモデルの BinEdges プロパティと関数discretizeを使用して、ビン化された予測子データを再現します。
X = Mdl.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
数値予測子の場合、1 からビンの数までの範囲にあるビンのインデックスが Xbinned に格納されます。カテゴリカル予測子の場合、Xbinned の値は 0 になります。X に NaN が含まれている場合、対応する Xbinned の値は NaN になります。
入力引数
名前と値の引数
出力引数
ヒント
NLearnは数十から数千までさまざまな数になります。通常、予測力が高いアンサンブルでは数百から数千の弱学習器が必要です。しかし、このような多数のサイクルの学習をアンサンブルが一度に行う必要はありません。数十個の学習器の学習から開始してアンサンブルの性能を調査し、必要な場合は分類問題用のresumeまたは回帰問題用のresumeを使用して弱学習器の数を増やすことができます。アンサンブルの性能は、アンサンブルの設定と弱学習器の設定によって決まります。つまり、既定のパラメーターを使用する弱学習器を指定すると、アンサンブルの性能が低下する可能性があります。このため、アンサンブルの設定と同じように、テンプレートを使用して弱学習器のパラメーターを調整し、汎化誤差が最小になる値を選択することをお勧めします。
Resampleを使用してリサンプリングを指定する場合は、データ セット全体に対してのリサンプリングをお勧めします。つまり、FResampleの既定設定である1を使用します。分類問題の場合 (つまり、
Typeが'classification'の場合)アンサンブル集約法 (
Method) が'bag'であり、誤分類コストが非常に不均衡である場合、in-bag の標本について、ペナルティが大きいクラスから一意な観測値がオーバーサンプリングされます。
クラスの事前確率の歪みが大きい場合、事前確率が大きいクラスから一意な観測値がオーバーサンプリングされます。
これらの組み合わせにより、標本サイズが小さい場合、ペナルティまたは事前確率が大きいクラスから抽出される out-of-bag 観測値の相対頻度が非常に低くなる可能性があります。この結果、out-of-bag の推定誤差の変動幅が非常に大きくなり、解釈が困難になる可能性があります。特に標本サイズが小さい場合に、out-of-bag の推定誤差の変動幅が大きくならないようにするには、近似関数の名前と値のペアの引数
Costを使用して誤分類コスト行列をより平衡にするか、近似関数の名前と値のペアの引数Priorを使用して事前確率ベクトルの歪みを小さくします。一部の入力引数および出力引数の順序は学習データ内の各クラスに対応するので、近似関数の名前と値のペアの引数
ClassNamesを使用してクラスの順序を指定することをお勧めします。クラスの順序を簡単に求めるには、未分類の (つまり欠損ラベルがある) 学習データからすべての観測値を削除し、個別のクラスがすべて含まれている配列を取得および表示してから、その配列を
ClassNamesに指定します。たとえば、応答変数 (Y) がラベルの cell 配列であるとします。次のコードは、変数classNamesでクラスの順序を指定します。Ycat = categorical(Y); classNames = categories(Ycat)
categoricalは<undefined>を未分類観測値に割り当て、categoriesは<undefined>を出力から除外します。したがって、このコードをラベルの cell 配列に対して使用するか、同様のコードを categorical 配列に対して使用すると、欠損ラベルがある観測値を削除しなくても各クラスのリストを取得できます。最小相当ラベルから最大相当ラベルの順になるように順序を指定するには、(前の項目のように) クラスの順序を簡単に求め、リスト内のクラスの順序を頻度順に変更してから、リストを
ClassNamesに渡します。前の例に従うと、次のコードは最小相当から最大相当の順にクラスの順序をclassNamesLHで指定します。Ycat = categorical(Y); classNames = categories(Ycat); freq = countcats(Ycat); [~,idx] = sort(freq); classNamesLH = classNames(idx);
アルゴリズム
アンサンブル集約アルゴリズムの詳細については、アンサンブル アルゴリズムを参照してください。
Methodがブースティング アルゴリズム、Learnersが決定木になるように指定した場合、既定では "切り株" が成長します。決定株は、2 つの終端ノード (葉ノード) に接続されている 1 つのルート ノードです。木の深さは、templateTreeを使用して名前と値のペアの引数MaxNumSplits、MinLeafSizeおよびMinParentSizeを指定することにより調整できます。in-bag の標本の生成では、誤分類コストが大きいクラスがオーバーサンプリングされ、誤分類コストが小さいクラスがアンダーサンプリングされます。その結果、out-of-bag の標本では、誤分類コストが大きいクラスの観測値は少なくなり、誤分類コストが小さいクラスの観測値は多くなります。小さなデータ セットと歪みが大きいコスト行列を使用してアンサンブル分類を学習させる場合、クラスあたりの out-of-bag の観測値の数は非常に少なくなることがあります。そのため、推定された out-of-bag の誤差の変動幅が非常に大きくなり、解釈が困難になる場合があります。事前確率が大きいクラスでも同じ現象が発生する場合があります。
アンサンブル集約法 (
Method) が RUSBoost である場合、名前と値のペアの引数RatioToSmallestでは最小相当クラスに関して各クラスのサンプリングの比率を指定します。たとえば、学習データに A および B という 2 つのクラスがあるとします。A には 100 個の観測値、B には 10 個の観測値が含まれています。また、最小相当クラスではm個の観測値が学習データに含まれているとします。'RatioToSmallest',2を設定した場合、s*m2*10=20になります。したがって、すべての学習器の学習では、クラス A の 20 個の観測値とクラス B の 20 個の観測値が使用されます。'RatioToSmallest',[2 2]を設定した場合も同じ結果になります。'RatioToSmallest',[2,1]を設定した場合、s1*m2*10=20およびs2*m1*10=10になります。したがって、すべての学習器の学習では、クラス A の 20 個の観測値とクラス B の 10 個の観測値が使用されます。
決定木のアンサンブルの場合とデュアルコア以上のシステムの場合、
fitcensembleとfitrensembleでは Intel® スレッディング ビルディング ブロック (TBB) を使用して学習を並列化します。Intel TBB の詳細については、https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.htmlを参照してください。
参照
[1] Freund, Y. “A more robust boosting algorithm.” arXiv:0905.2138v1, 2009.
バージョン履歴
R2014b で導入