このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitcensemble
アンサンブル学習器を分類用に準備
構文
説明
Mdl = fitcensemble(Tbl,ResponseVarName)Tbl が格納されている学習済みアンサンブル分類モデル オブジェクト (Mdl) を返します。ResponseVarName は、Tbl 内の応答変数の名前です。既定では、fitcensemble はバイナリ分類に LogitBoost を、マルチクラス分類に AdaBoostM2 を使用します。
Mdl = fitcensemble(___,Name,Value)Name,Value ペア引数で指定される追加のオプションと、前の構文の入力引数のいずれかを使用します。たとえば、学習サイクル数、アンサンブル集約法、10 分割交差検証の実施を指定できます。
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitcensemble(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
データ内の使用可能な予測子変数をすべて使用して、予測アンサンブル分類を作成します。次に、予測子の数を減らして、別のアンサンブルに学習をさせます。これらのアンサンブルの標本内予測精度を比較します。
census1994 データ セットを読み込みます。
load census1994データ セット全体と既定のオプションを使用して、分類モデルのアンサンブルに学習をさせます。
Mdl1 = fitcensemble(adultdata,'salary')Mdl1 =
ClassificationEnsemble
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
ResponseName: 'salary'
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
NumTrained: 100
Method: 'LogitBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [100×1 double]
FitInfoDescription: {2×1 cell}
Properties, Methods
Mdl は ClassificationEnsemble モデルです。Mdl には、次のような顕著な特徴があります。
データには 2 つのクラスがあるので、アンサンブル集約アルゴリズムは LogitBoost です。
アンサンブル集約法がブースティング アルゴリズムなので、最大 10 分割を許容する分類木がアンサンブルを構成します。
100 本の木がアンサンブルを構成します。
このアンサンブル分類を使用して、データから無作為に抽出した 5 つの観測値のラベルを予測します。予測されたラベルと真の値を比較します。
rng(1) % For reproducibility [pX,pIdx] = datasample(adultdata,5); label = predict(Mdl1,pX); table(label,adultdata.salary(pIdx),'VariableNames',{'Predicted','Truth'})
ans=5×2 table
Predicted Truth
_________ _____
<=50K <=50K
<=50K <=50K
<=50K <=50K
<=50K <=50K
<=50K <=50K
age と education のみを使用して、新しいアンサンブルに学習をさせます。
Mdl2 = fitcensemble(adultdata,'salary ~ age + education');Mdl1 と Mdl2 の再代入損失を比較します。
rsLoss1 = resubLoss(Mdl1)
rsLoss1 = 0.1058
rsLoss2 = resubLoss(Mdl2)
rsLoss2 = 0.2037
すべての予測子を使用するアンサンブルの方が、標本内誤分類率が小さくなります。
fitcensemble を使用して、ブースティング分類木のアンサンブルに学習をさせます。名前と値のペアの引数 'NumBins' を指定して数値予測子をビン化することにより、学習時間を短縮します。この引数は、fitcensemble が木学習器を使用する場合のみ有効です。学習後、学習済みモデルの BinEdges プロパティと関数discretizeを使用して、ビン化された予測子データを再現できます。
標本データ セットを生成します。
rng('default') % For reproducibility N = 1e6; X = [mvnrnd([-1 -1],eye(2),N); mvnrnd([1 1],eye(2),N)]; y = [zeros(N,1); ones(N,1)];
データ セットを可視化します。
figure scatter(X(1:N,1),X(1:N,2),'Marker','.','MarkerEdgeAlpha',0.01) hold on scatter(X(N+1:2*N,1),X(N+1:2*N,2),'Marker','.','MarkerEdgeAlpha',0.01)
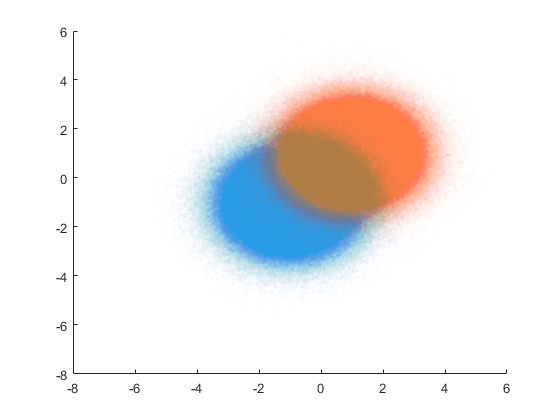
適応ロジスティック回帰 (LogitBoost、バイナリ分類の既定) を使用して、ブースティング分類木のアンサンブルに学習をさせます。比較のため、関数の実行時間を測定します。
tic Mdl1 = fitcensemble(X,y); toc
Elapsed time is 478.988422 seconds.
名前と値のペアの引数 'NumBins' を使用して、学習を高速化します。'NumBins' の値として正の整数スカラーを指定した場合、指定した個数の同確率のビンにすべての数値予測子がビン化され、元のデータではなくビンのインデックスに対して木が成長します。カテゴリカル予測子はビン化されません。
tic
Mdl2 = fitcensemble(X,y,'NumBins',50);
tocElapsed time is 165.598434 seconds.
元のデータではなくビン化されたデータを使用すると、処理が約 3 倍高速になります。経過時間はオペレーティング システムによって変化する可能性があることに注意してください。
再代入による分類誤差を比較します。
rsLoss1 = resubLoss(Mdl1)
rsLoss1 = 0.0788
rsLoss2 = resubLoss(Mdl2)
rsLoss2 = 0.0788
この例では、予測子の値をビン化することにより、精度を失わずに学習時間が短縮されました。一般に、この例のような大規模な学習データ セットを使用する場合、ビン化オプションを使用すると学習を高速化できますが、精度が低下する可能性があります。さらに学習時間を短縮するには、指定するビンの個数を少なくします。
学習済みモデルの BinEdges プロパティと関数discretizeを使用して、ビン化された予測子データを再現します。
X = Mdl2.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl2.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
数値予測子の場合、1 からビンの数までの範囲にあるビンのインデックスが Xbinned に格納されます。カテゴリカル予測子の場合、Xbinned の値は 0 になります。X に NaN が含まれている場合、対応する Xbinned の値は NaN になります。
ブースティング分類木のアンサンブルの汎化誤差を推定します。
ionosphere データ セットを読み込みます。
load ionosphereAdaBoostM1 と 10 分割の交差検証を使用して、分類木のアンサンブルを交差検証します。決定木テンプレートを使用して各木を最大 5 回分割するように指定します。
rng(5); % For reproducibility t = templateTree('MaxNumSplits',5); Mdl = fitcensemble(X,Y,'Method','AdaBoostM1','Learners',t,'CrossVal','on');
Mdl は ClassificationPartitionedEnsemble モデルです。
10 分割交差検証を行った累積誤分類率をプロットします。アンサンブルの推定汎化誤差を表示します。
kflc = kfoldLoss(Mdl,'Mode','cumulative'); figure; plot(kflc); ylabel('10-fold Misclassification rate'); xlabel('Learning cycle');
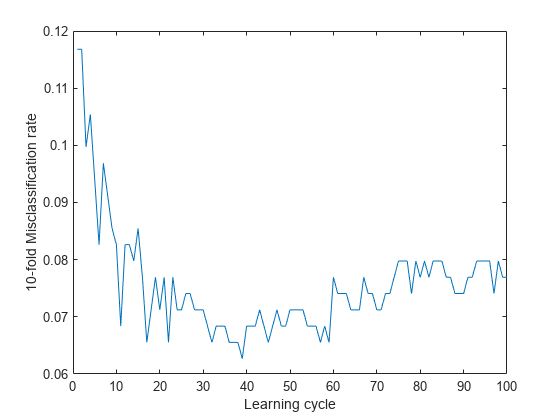
estGenError = kflc(end)
estGenError = 0.0769
既定の設定では、kfoldLoss は汎化誤差を返します。しかし、累積損失をプロットすると、アンサンブル内に弱学習器が蓄積するにつれて損失がどのように変化するかを観察できます。
このアンサンブルでは、約 50 個の弱学習器が蓄積した後の誤分類率が約 0.06 になっています。そして、弱学習器がさらにアンサンブルに加わると、誤分類率がわずかに増加しています。
アンサンブルの汎化誤差が満足できるものになった場合は、予測モデルを作成するため、交差検証以外の設定をすべて使用して、再度アンサンブルに学習をさせます。ただし、木あたりの決定分岐の最大数や学習サイクル数などのハイパーパラメーターを調整することをお勧めします。
fitcensemble を使用してハイパーパラメーターを自動的に最適化します。
ionosphere データ セットを読み込みます。
load ionosphere自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めることができます。
Mdl = fitcensemble(X,Y,'OptimizeHyperparameters','auto')
この例では、再現性を得るため、乱数シードを設定し、'expected-improvement-plus' の獲得関数を使用します。また、ランダム フォレスト アルゴリズムの再現性を得るため、木学習器について名前と値のペアの引数 'Reproducible' として true を指定します。
rng('default') t = templateTree('Reproducible',true); Mdl = fitcensemble(X,Y,'OptimizeHyperparameters','auto','Learners',t, ... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName','expected-improvement-plus'))
|===================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize | | | result | | runtime | (observed) | (estim.) | | ycles | | | |===================================================================================================================================| | 1 | Best | 0.10256 | 2.8201 | 0.10256 | 0.10256 | RUSBoost | 11 | 0.010199 | 17 | | 2 | Best | 0.082621 | 6.3089 | 0.082621 | 0.083414 | LogitBoost | 206 | 0.96537 | 33 | | 3 | Accept | 0.099715 | 4.0004 | 0.082621 | 0.082624 | AdaBoostM1 | 130 | 0.0072814 | 2 | | 4 | Best | 0.068376 | 1.5887 | 0.068376 | 0.068395 | Bag | 25 | - | 5 | | 5 | Best | 0.059829 | 1.7618 | 0.059829 | 0.062829 | LogitBoost | 58 | 0.19016 | 5 | | 6 | Accept | 0.068376 | 1.6662 | 0.059829 | 0.065561 | LogitBoost | 58 | 0.10005 | 5 | | 7 | Accept | 0.088319 | 13.07 | 0.059829 | 0.065786 | LogitBoost | 494 | 0.014474 | 3 | | 8 | Accept | 0.065527 | 0.79673 | 0.059829 | 0.065894 | LogitBoost | 26 | 0.75515 | 8 | | 9 | Accept | 0.15385 | 0.93354 | 0.059829 | 0.061156 | LogitBoost | 32 | 0.0010037 | 59 | | 10 | Accept | 0.059829 | 3.8828 | 0.059829 | 0.059731 | LogitBoost | 143 | 0.44428 | 1 | | 11 | Accept | 0.35897 | 2.3272 | 0.059829 | 0.059826 | Bag | 54 | - | 175 | | 12 | Accept | 0.068376 | 0.53634 | 0.059829 | 0.059825 | Bag | 10 | - | 1 | | 13 | Accept | 0.12251 | 9.5155 | 0.059829 | 0.059826 | AdaBoostM1 | 442 | 0.57897 | 102 | | 14 | Accept | 0.11966 | 4.9323 | 0.059829 | 0.059827 | RUSBoost | 95 | 0.80822 | 1 | | 15 | Accept | 0.062678 | 4.2429 | 0.059829 | 0.059826 | GentleBoost | 156 | 0.99502 | 1 | | 16 | Accept | 0.065527 | 3.0688 | 0.059829 | 0.059824 | GentleBoost | 115 | 0.99693 | 13 | | 17 | Best | 0.05698 | 1.659 | 0.05698 | 0.056997 | GentleBoost | 60 | 0.0010045 | 3 | | 18 | Accept | 0.13675 | 2.0647 | 0.05698 | 0.057002 | GentleBoost | 86 | 0.0010263 | 108 | | 19 | Accept | 0.062678 | 2.4037 | 0.05698 | 0.05703 | GentleBoost | 88 | 0.6344 | 4 | | 20 | Accept | 0.065527 | 1.029 | 0.05698 | 0.057228 | GentleBoost | 35 | 0.0010155 | 1 | |===================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize | | | result | | runtime | (observed) | (estim.) | | ycles | | | |===================================================================================================================================| | 21 | Accept | 0.079772 | 0.44308 | 0.05698 | 0.057214 | LogitBoost | 11 | 0.9796 | 2 | | 22 | Accept | 0.065527 | 21.191 | 0.05698 | 0.057523 | Bag | 499 | - | 1 | | 23 | Accept | 0.068376 | 20.294 | 0.05698 | 0.057671 | Bag | 494 | - | 2 | | 24 | Accept | 0.64103 | 1.2793 | 0.05698 | 0.057468 | RUSBoost | 30 | 0.088421 | 174 | | 25 | Accept | 0.088319 | 0.53606 | 0.05698 | 0.057456 | RUSBoost | 10 | 0.010292 | 5 | | 26 | Accept | 0.074074 | 0.36802 | 0.05698 | 0.05753 | AdaBoostM1 | 11 | 0.14192 | 13 | | 27 | Accept | 0.099715 | 12.133 | 0.05698 | 0.057646 | AdaBoostM1 | 498 | 0.0010096 | 6 | | 28 | Accept | 0.079772 | 10.877 | 0.05698 | 0.057886 | AdaBoostM1 | 474 | 0.030547 | 31 | | 29 | Accept | 0.068376 | 12.326 | 0.05698 | 0.061326 | GentleBoost | 493 | 0.36142 | 2 | | 30 | Accept | 0.065527 | 0.3945 | 0.05698 | 0.061165 | LogitBoost | 11 | 0.71408 | 16 |
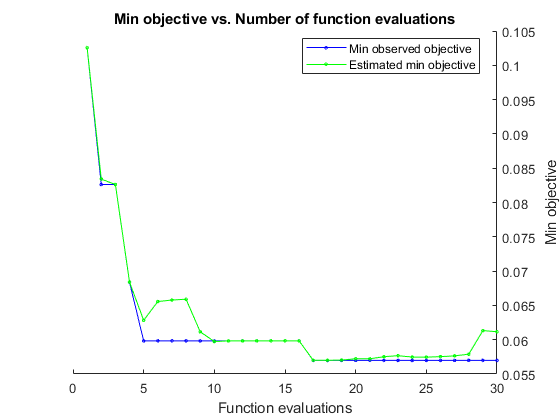
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 165.9329 seconds
Total objective function evaluation time: 148.4504
Best observed feasible point:
Method NumLearningCycles LearnRate MinLeafSize
___________ _________________ _________ ___________
GentleBoost 60 0.0010045 3
Observed objective function value = 0.05698
Estimated objective function value = 0.061165
Function evaluation time = 1.659
Best estimated feasible point (according to models):
Method NumLearningCycles LearnRate MinLeafSize
___________ _________________ _________ ___________
GentleBoost 60 0.0010045 3
Estimated objective function value = 0.061165
Estimated function evaluation time = 1.6503
Mdl =
ClassificationEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
NumTrained: 60
Method: 'GentleBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [60×1 double]
FitInfoDescription: {2×1 cell}
Properties, Methods
最適化では、バイナリ分類のアンサンブル集約法、NumLearningCycles、適用可能な手法の LearnRate、および木学習器の MinLeafSize に対して探索を行いました。出力は、推定交差検証損失が最小になるアンサンブル分類器です。
十分な予測性能をもつブースティング分類木のアンサンブルを作成する方法の 1 つは、交差検証を使用して決定木の複雑度レベルを調整することです。最適な複雑度レベルを求めるときに、学習率を調整して学習サイクル数を最小化します。
この例では、交差検証オプション (名前と値のペアの引数 'KFold') と関数 kfoldLoss を使用して、最適なパラメーターを手動で求めます。あるいは、名前と値のペアの引数 'OptimizeHyperparameters' を使用して自動的にハイパーパラメーターを最適化することもできます。アンサンブル分類の最適化を参照してください。
ionosphere データ セットを読み込みます。
load ionosphere最適な木の複雑度レベルを求めるため、以下を行います。
一連のアンサンブルを交差検証します。以後のアンサンブルについて、決定株 (1 つの分割) から最大 n - 1 個の分割まで木の複雑度レベルを指数的に増やします。n は標本サイズです。また、各アンサンブル学習率を 0.1 から 1 までの間で変化させます。
各アンサンブルの交差検証済み誤分類率を推定します。
木の複雑度レベル () について、学習サイクル数に対してプロットすることにより、アンサンブルの交差検証済み累積誤分類率を比較します。同じ Figure に、各学習率に対応する別々の曲線をプロットします。
誤分類率が最小になる曲線を選択し、対応する学習サイクルおよび学習率に注目します。
深い分類木と切り株を交差検証します。これらの分類木は基準として機能します。
rng(1) % For reproducibility MdlDeep = fitctree(X,Y,'CrossVal','on','MergeLeaves','off', ... 'MinParentSize',1); MdlStump = fitctree(X,Y,'MaxNumSplits',1,'CrossVal','on');
5 分割の交差検証を使用して、150 本のブースティング分類木のアンサンブルを交差検証します。木のテンプレートを使用して、 という数列の値を使用して分割の最大数を変化させます。m は、 が n - 1 を超えない値です。各バリアントについて、{0.1, 0.25, 0.5, 1} という集合の各値を使用して、それぞれの学習率を調整します。
n = size(X,1); m = floor(log(n - 1)/log(3)); learnRate = [0.1 0.25 0.5 1]; numLR = numel(learnRate); maxNumSplits = 3.^(0:m); numMNS = numel(maxNumSplits); numTrees = 150; Mdl = cell(numMNS,numLR); for k = 1:numLR for j = 1:numMNS t = templateTree('MaxNumSplits',maxNumSplits(j)); Mdl{j,k} = fitcensemble(X,Y,'NumLearningCycles',numTrees,... 'Learners',t,'KFold',5,'LearnRate',learnRate(k)); end end
各アンサンブルについて、および基準として機能する分類木について、交差検証済み累積誤分類率を推定します。
kflAll = @(x)kfoldLoss(x,'Mode','cumulative'); errorCell = cellfun(kflAll,Mdl,'Uniform',false); error = reshape(cell2mat(errorCell),[numTrees numel(maxNumSplits) numel(learnRate)]); errorDeep = kfoldLoss(MdlDeep); errorStump = kfoldLoss(MdlStump);
アンサンブル内の木の本数が増加すると交差検証済み誤分類率がどのように変化するかをプロットします。同じプロットに学習率ごとの曲線をプロットし、木の複雑度レベルを変えた別のプロットをそれぞれ作成します。木の複雑度レベルからプロット対象となるサブセットを選択します。
mnsPlot = [1 round(numel(maxNumSplits)/2) numel(maxNumSplits)]; figure for k = 1:3 subplot(2,2,k) plot(squeeze(error(:,mnsPlot(k),:)),'LineWidth',2) axis tight hold on h = gca; plot(h.XLim,[errorDeep errorDeep],'-.b','LineWidth',2) plot(h.XLim,[errorStump errorStump],'-.r','LineWidth',2) plot(h.XLim,min(min(error(:,mnsPlot(k),:))).*[1 1],'--k') h.YLim = [0 0.2]; xlabel('Number of trees') ylabel('Cross-validated misclass. rate') title(sprintf('MaxNumSplits = %0.3g', maxNumSplits(mnsPlot(k)))) hold off end hL = legend([cellstr(num2str(learnRate','Learning Rate = %0.2f')); ... 'Deep Tree';'Stump';'Min. misclass. rate']); hL.Position(1) = 0.6;

各曲線では、アンサンブルの最適な木の本数の位置で交差検証済み誤分類率が最小になります。
全体的に誤分類率が最小になる最大分割数、木の本数および学習率を特定します。
[minErr,minErrIdxLin] = min(error(:));
[idxNumTrees,idxMNS,idxLR] = ind2sub(size(error),minErrIdxLin);
fprintf('\nMin. misclass. rate = %0.5f',minErr)Min. misclass. rate = 0.05128
fprintf('\nOptimal Parameter Values:\nNum. Trees = %d',idxNumTrees);Optimal Parameter Values: Num. Trees = 130
fprintf('\nMaxNumSplits = %d\nLearning Rate = %0.2f\n',... maxNumSplits(idxMNS),learnRate(idxLR))
MaxNumSplits = 9 Learning Rate = 1.00
最適なハイパーパラメーターおよび学習セット全体に基づいて予測アンサンブルを作成します。
tFinal = templateTree('MaxNumSplits',maxNumSplits(idxMNS)); MdlFinal = fitcensemble(X,Y,'NumLearningCycles',idxNumTrees,... 'Learners',tFinal,'LearnRate',learnRate(idxLR))
MdlFinal =
ClassificationEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
NumTrained: 130
Method: 'LogitBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [130×1 double]
FitInfoDescription: {2×1 cell}
Properties, Methods
MdlFinal は ClassificationEnsemble です。与えられた予測子データに対してレーダー反射が良好であるかどうかを予測するには、予測子データと MdlFinal を predict に渡すことができます。
交差検証オプション ('KFold') と関数 kfoldLoss を使用して最適な値を手動で求める代わりに、名前と値のペアの引数 'OptimizeHyperparameters' を使用できます。'OptimizeHyperparameters' を指定すると、ベイズ最適化を使用して、最適なパラメーターが自動的に求められます。'OptimizeHyperparameters' を使用して取得した最適な値は、手動で求めたものと異なる可能性があります。
mdl = fitcensemble(X,Y,'OptimizeHyperparameters',{'NumLearningCycles','LearnRate','MaxNumSplits'})
|====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits | | | result | | runtime | (observed) | (estim.) | ycles | | | |====================================================================================================================| | 1 | Best | 0.094017 | 3.7194 | 0.094017 | 0.094017 | 137 | 0.001364 | 3 | | 2 | Accept | 0.12251 | 0.66511 | 0.094017 | 0.095735 | 15 | 0.013089 | 144 |
| 3 | Best | 0.065527 | 0.90035 | 0.065527 | 0.067815 | 31 | 0.47201 | 2 | | 4 | Accept | 0.19943 | 8.6107 | 0.065527 | 0.070015 | 340 | 0.92167 | 7 | | 5 | Accept | 0.071225 | 0.90081 | 0.065527 | 0.065583 | 32 | 0.14422 | 2 | | 6 | Accept | 0.099715 | 0.688 | 0.065527 | 0.065573 | 23 | 0.0010566 | 2 | | 7 | Accept | 0.11681 | 0.90799 | 0.065527 | 0.065565 | 28 | 0.0010156 | 259 | | 8 | Accept | 0.17379 | 0.82143 | 0.065527 | 0.065559 | 29 | 0.0013435 | 1 | | 9 | Best | 0.059829 | 0.59677 | 0.059829 | 0.059844 | 18 | 0.87865 | 3 | | 10 | Accept | 0.11111 | 0.40132 | 0.059829 | 0.059843 | 10 | 0.0012112 | 48 | | 11 | Accept | 0.08547 | 0.41121 | 0.059829 | 0.059842 | 10 | 0.62108 | 25 | | 12 | Accept | 0.11681 | 0.41538 | 0.059829 | 0.059841 | 10 | 0.0012154 | 20 | | 13 | Accept | 0.082621 | 0.46504 | 0.059829 | 0.059842 | 10 | 0.55351 | 35 | | 14 | Accept | 0.079772 | 0.46297 | 0.059829 | 0.05984 | 11 | 0.74109 | 74 | | 15 | Accept | 0.088319 | 0.69297 | 0.059829 | 0.05984 | 19 | 0.91106 | 347 | | 16 | Accept | 0.062678 | 0.3637 | 0.059829 | 0.059886 | 10 | 0.97239 | 3 | | 17 | Accept | 0.065527 | 1.9404 | 0.059829 | 0.059887 | 78 | 0.97069 | 3 | | 18 | Accept | 0.065527 | 0.39816 | 0.059829 | 0.062228 | 11 | 0.75051 | 2 | | 19 | Best | 0.054131 | 0.36381 | 0.054131 | 0.059083 | 10 | 0.69072 | 3 | | 20 | Accept | 0.065527 | 0.38429 | 0.054131 | 0.060938 | 10 | 0.64403 | 3 | |====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits | | | result | | runtime | (observed) | (estim.) | ycles | | | |====================================================================================================================| | 21 | Accept | 0.079772 | 0.40405 | 0.054131 | 0.060161 | 10 | 0.80548 | 13 | | 22 | Accept | 0.05698 | 0.37983 | 0.054131 | 0.059658 | 10 | 0.56949 | 5 | | 23 | Accept | 0.10826 | 0.36128 | 0.054131 | 0.059244 | 10 | 0.0055133 | 5 | | 24 | Accept | 0.074074 | 0.38056 | 0.054131 | 0.05933 | 10 | 0.92056 | 6 | | 25 | Accept | 0.11966 | 0.35336 | 0.054131 | 0.059132 | 10 | 0.27254 | 1 | | 26 | Accept | 0.065527 | 0.77041 | 0.054131 | 0.059859 | 26 | 0.97412 | 3 | | 27 | Accept | 0.068376 | 0.38116 | 0.054131 | 0.060205 | 10 | 0.82146 | 4 | | 28 | Accept | 0.062678 | 0.47015 | 0.054131 | 0.060713 | 14 | 0.99445 | 3 | | 29 | Accept | 0.11966 | 0.41033 | 0.054131 | 0.060826 | 10 | 0.0012621 | 344 | | 30 | Accept | 0.08547 | 0.45352 | 0.054131 | 0.060771 | 10 | 0.93676 | 187 |
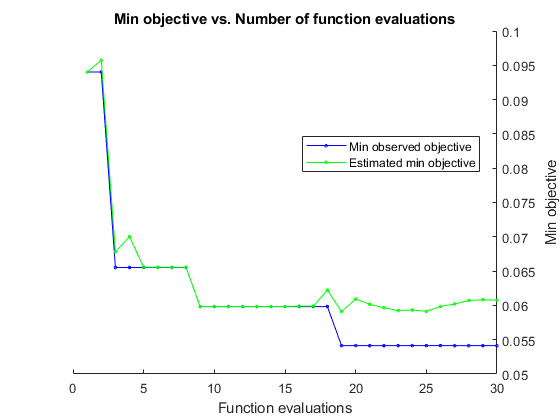
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 41.5854 seconds
Total objective function evaluation time: 28.4744
Best observed feasible point:
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
10 0.69072 3
Observed objective function value = 0.054131
Estimated objective function value = 0.061741
Function evaluation time = 0.36381
Best estimated feasible point (according to models):
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
14 0.99445 3
Estimated objective function value = 0.060771
Estimated function evaluation time = 0.48009
mdl =
ClassificationEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
NumTrained: 14
Method: 'LogitBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [14×1 double]
FitInfoDescription: {2×1 cell}
Properties, Methods
入力引数
名前と値の引数
出力引数
ヒント
NumLearningCyclesは数十から数千までさまざまな数になります。通常、予測力が高いアンサンブルでは数百から数千の弱学習器が必要です。しかし、このような多数のサイクルの学習をアンサンブルが一度に行う必要はありません。数十個の学習器の学習から開始してアンサンブルの性能を調査し、必要な場合は分類問題用のresumeを使用して弱学習器の数を増やすことができます。アンサンブルの性能は、アンサンブルの設定と弱学習器の設定によって決まります。つまり、既定のパラメーターを使用する弱学習器を指定すると、アンサンブルの性能が低下する可能性があります。このため、アンサンブルの設定と同じように、テンプレートを使用して弱学習器のパラメーターを調整し、汎化誤差が最小になる値を選択することをお勧めします。
Resampleを使用してリサンプリングを指定する場合は、データ セット全体に対してのリサンプリングをお勧めします。つまり、FResampleの既定設定である1を使用します。アンサンブル集約法 (
Method) が'bag'であり、誤分類コスト (
Cost) が非常に不均衡である場合、in-bag の標本について、ペナルティが大きいクラスから一意な観測値がオーバーサンプリングされます。クラスの事前確率 (
Prior) の歪みが大きい場合、事前確率が大きいクラスから一意な観測値がオーバーサンプリングされます。
これらの組み合わせにより、標本サイズが小さい場合、ペナルティまたは事前確率が大きいクラスから抽出される out-of-bag 観測値の相対頻度が低くなる可能性があります。この結果、out-of-bag の推定誤差の変動幅が非常に大きくなり、解釈が困難になる可能性があります。特に標本サイズが小さい場合に、out-of-bag の推定誤差の変動幅が大きくならないようにするには、
Costを使用して誤分類コスト行列をより平衡にするか、Priorを使用して事前確率ベクトルの歪みを小さくします。一部の入力引数および出力引数の順序は学習データ内の各クラスに対応するので、名前と値のペアの引数
ClassNamesを使用してクラスの順序を指定することをお勧めします。クラスの順序を簡単に求めるには、未分類の (つまり欠損ラベルがある) 観測値を学習データからすべて削除し、異なるクラスがすべて含まれている配列を取得および表示してから、その配列を
ClassNamesに指定します。たとえば、応答変数 (Y) がラベルの cell 配列であるとします。次のコードは、変数classNamesでクラスの順序を指定します。Ycat = categorical(Y); classNames = categories(Ycat)
categoricalは<undefined>を未分類観測値に割り当て、categoriesは<undefined>を出力から除外します。したがって、このコードをラベルの cell 配列に対して使用するか、同様のコードを categorical 配列に対して使用すると、欠損ラベルがある観測値を削除しなくても各クラスのリストを取得できます。最小相当ラベルから最大相当ラベルの順になるようにクラスの順序を指定するには、(前の項目のように) クラスの順序を簡単に調べ、リスト内のクラスの順序を頻度順に変更してから、リストを
ClassNamesに渡します。前の例に従うと、次のコードは最小相当から最大相当の順にクラスの順序をclassNamesLHで指定します。Ycat = categorical(Y); classNames = categories(Ycat); freq = countcats(Ycat); [~,idx] = sort(freq); classNamesLH = classNames(idx);
モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
アンサンブル集約アルゴリズムの詳細については、アンサンブル アルゴリズムを参照してください。
Methodがブースティング アルゴリズム、Learnersが決定木になるように設定した場合、既定では浅い決定木が成長します。木の深さは、templateTreeを使用して名前と値のペアの引数MaxNumSplits、MinLeafSizeおよびMinParentSizeを指定することにより調整できます。名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列 (C) が変更なしで格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。モデルの学習用に、事前確率と観測値の重みが更新されて、コスト行列で指定されているペナルティが組み込まれます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。バギング (
'Method','Bag') の場合、fitcensembleは、誤分類コストが大きいクラスをオーバーサンプリングし、誤分類コストが小さいクラスをアンダーサンプリングすることにより、in-bag の標本を生成します。その結果、out-of-bag の標本では、誤分類コストが大きいクラスの観測値は少なくなり、誤分類コストが小さいクラスの観測値は多くなります。小さいデータ セットと歪みが大きいコスト行列を使用してアンサンブル分類に学習をさせる場合、クラスあたりの out-of-bag 観測値の数が少なくなる可能性があります。このため、out-of-bag の推定誤差の変動幅が非常に大きくなり、解釈が困難になる可能性があります。事前確率が大きいクラスでも同じ現象が発生する場合があります。アンサンブル集約法 (
'Method','RUSBoost') が RUSBoost である場合、名前と値のペアの引数RatioToSmallestでは最小相当クラスに関して各クラスのサンプリングの比率を指定します。たとえば、学習データに A および B という 2 つのクラスがあるとします。A には 100 個の観測値、B には 10 個の観測値が含まれています。また、最小相当クラスではm個の観測値が学習データに含まれているとします。'RatioToSmallest',2を設定した場合、s*m2*10=20になります。したがって、fitcensembleはクラス A の 20 個の観測値とクラス B の 20 個の観測値を使用して、すべての学習器に学習をさせます。'RatioToSmallest',[2 2]を設定した場合も同じ結果になります。'RatioToSmallest',[2,1]を設定した場合、s1*m2*10=20およびs2*m1*10=10になります。したがって、fitcensembleはクラス A の 20 個の観測値とクラス B の 10 個の観測値を使用して、すべての学習器に学習をさせます。
デュアルコア以上のシステムの場合、
fitcensembleでは Intel スレッディング ビルディング ブロック (TBB) を使用して学習を並列化します。Intel TBB の詳細については、https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.htmlを参照してください。
参照
[1] Breiman, L. “Bagging Predictors.” Machine Learning. Vol. 26, pp. 123–140, 1996.
[2] Breiman, L. “Random Forests.” Machine Learning. Vol. 45, pp. 5–32, 2001.
[4] Freund, Y. and R. E. Schapire. “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting.” J. of Computer and System Sciences, Vol. 55, pp. 119–139, 1997.
[5] Friedman, J. “Greedy function approximation: A gradient boosting machine.” Annals of Statistics, Vol. 29, No. 5, pp. 1189–1232, 2001.
[6] Friedman, J., T. Hastie, and R. Tibshirani. “Additive logistic regression: A statistical view of boosting.” Annals of Statistics, Vol. 28, No. 2, pp. 337–407, 2000.
[7] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning section edition, Springer, New York, 2008.
[8] Ho, T. K. “The random subspace method for constructing decision forests.” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 20, No. 8, pp. 832–844, 1998.
[9] Schapire, R. E., Y. Freund, P. Bartlett, and W.S. Lee. “Boosting the margin: A new explanation for the effectiveness of voting methods.” Annals of Statistics, Vol. 26, No. 5, pp. 1651–1686, 1998.
[10] Seiffert, C., T. Khoshgoftaar, J. Hulse, and A. Napolitano. “RUSBoost: Improving classification performance when training data is skewed.” 19th International Conference on Pattern Recognition, pp. 1–4, 2008.
[11] Warmuth, M., J. Liao, and G. Ratsch. “Totally corrective boosting algorithms that maximize the margin.” Proc. 23rd Int’l. Conf. on Machine Learning, ACM, New York, pp. 1001–1008, 2006.