このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitcknn
k 最近傍分類器の当てはめ
構文
説明
Mdl = fitcknn(Tbl,ResponseVarName)Tbl 内の入力変数 (予測子、特徴量または属性とも呼ばれます) 、および出力 (応答) Tbl.ResponseVarName に基づいて k 最近傍分類モデルを返します。
Mdl = fitcknn(___,Name=Value)
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitcknn(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
フィッシャーのアヤメのデータを使用して "k" 最近傍分類器に学習させます。ここで、予測子の最近傍の数 "k" は 5 です。
フィッシャーのアヤメのデータを読み込みます。
load fisheriris
X = meas;
Y = species;X は、150 本のアヤメについて 4 つの測定値が含まれている数値行列です。Y は、対応するアヤメの種類が含まれている文字ベクトルの cell 配列です。
5 最近傍分類器を学習させます。非カテゴリカル予測子データを標準化します。
Mdl = fitcknn(X,Y,NumNeighbors=5,Standardize=true)
Mdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
Distance: 'euclidean'
NumNeighbors: 5
Properties, Methods
Mdl は学習させた ClassificationKNN 分類器です。
ドット表記を使用して Mdl プロパティにアクセスします。
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
Mdl.Prior
ans = 1×3
0.3333 0.3333 0.3333
Mdl.Prior にはクラスの事前確率が格納されます。これは、fitcknn の名前と値の引数 Prior を使用して指定できます。クラス事前確率の順序は Mdl.ClassNames のクラスの順序に対応します。既定では、事前確率はデータ内のクラスのそれぞれの相対的頻度です。
学習後に事前確率をリセットすることもできます。たとえば、事前確率をそれぞれ 0.5、0.2 および 0.3 に設定します。
Mdl.Prior = [0.5 0.2 0.3];
Mdl を predict に渡すと、新しい測定値にラベルを付けることができます。また、crossvalに渡すと、分類器を交差検証できます。
ミンコフスキー距離計量を使用して "k" 最近傍分類器に学習させます。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas;
Y = species;X は、150 本のアヤメについて 4 つの測定値が含まれている数値行列です。Y は、対応するアヤメの種類が含まれている文字ベクトルの cell 配列です。
3 最近傍分類器をミンコフスキー計量を使用して学習させます。ミンコフスキー計量を使用するには、網羅的探索を使用しなければなりません。非カテゴリカル予測子データを標準化します。
Mdl = fitcknn(X,Y,NumNeighbors=3, ... NSMethod="exhaustive",Distance="minkowski", ... Standardize=true);
Mdl は ClassificationKNN 分類器です。
Mdl の学習に使用されたミンコフスキー距離指数を調べます。
Mdl.DistParameter
ans = 2
距離のパラメーターは ClassificationKNN オブジェクトの作成後に変更できます。たとえば、ミンコフスキー距離指数を 4 に設定します。
Mdl.DistParameter = 4; Mdl.DistParameter
ans = 4
カイ二乗距離を使用して k 最近傍分類器に学習をさせます。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas;
Y = species;j 次元の x 点と z 点のカイ二乗距離は次のようになります。
ここで、 は次元 j に関連付けられている重みです。
カイ二乗距離関数を指定します。距離関数は以下の手順を実行しなければなりません。
Xの 1 行 (たとえばx) および行列Zを取る。xをZの各行と比較する。長さ のベクトル
Dを返す。 はZの行数です。Dの各要素はxに対応する観測とZの各行に対応する観測との間の距離です。
chiSqrDist = @(x,Z,wt)sqrt(((x-Z).^2)*wt);
この例では例示のために任意の重みを使用します。
3 最近傍分類器を学習させます。非カテゴリカル予測子データを標準化することをお勧めします。
k = 3;
w = [0.3; 0.3; 0.2; 0.2];
KNNMdl = fitcknn(X,Y,Distance=@(x,Z)chiSqrDist(x,Z,w), ...
NumNeighbors=k,Standardize=true);KNNMdl はClassificationKNN分類器です。
10 分割交差検証を使用して KNN 分類器を交差検証します。分類誤差を調べます。
rng(1); % For reproducibility
CVKNNMdl = crossval(KNNMdl);
classError = kfoldLoss(CVKNNMdl)classError = 0.0600
CVKNNMdl はClassificationPartitionedModel分類器です。
分類器を異なる加重スキームを使用するものと比較します。
w2 = [0.2; 0.2; 0.3; 0.3];
CVKNNMdl2 = fitcknn(X,Y,Distance=@(x,Z)chiSqrDist(x,Z,w2), ...
NumNeighbors=k,KFold=10,Standardize=true);
classError2 = kfoldLoss(CVKNNMdl2)classError2 = 0.0400
2 番目の加重スキームから得られた分類器のほうが標本外パフォーマンスが優れています。
fitcknn を使用して、"k" 最近傍分類器のハイパーパラメーターを自動的に最適化します。
fisheriris データ セットを読み込みます。
load fisheriris
X = meas;
Y = species;自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。
再現性を得るために、乱数シードを設定し、"expected-improvement-plus" の獲得関数を使用します。
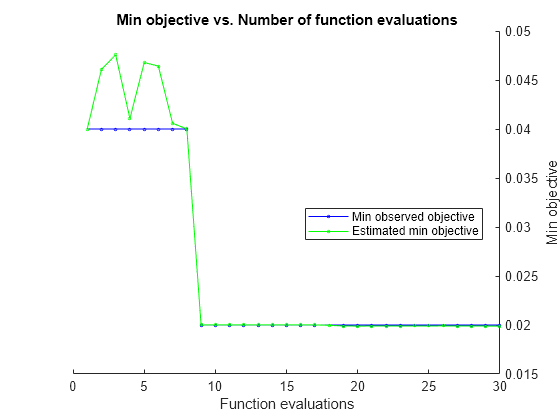
rng(1) Mdl = fitcknn(X,Y,OptimizeHyperparameters="auto", ... HyperparameterOptimizationOptions= ... struct(AcquisitionFunctionName="expected-improvement-plus"))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | NumNeighbors | Distance | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.04 | 0.46278 | 0.04 | 0.04 | 13 | minkowski | true |
| 2 | Accept | 0.19333 | 0.19938 | 0.04 | 0.046097 | 1 | correlation | true |
| 3 | Accept | 0.053333 | 0.06401 | 0.04 | 0.047573 | 14 | chebychev | true |
| 4 | Accept | 0.046667 | 0.076706 | 0.04 | 0.041053 | 2 | minkowski | false |
| 5 | Accept | 0.053333 | 0.054991 | 0.04 | 0.046782 | 7 | minkowski | true |
| 6 | Accept | 0.10667 | 0.095408 | 0.04 | 0.046422 | 2 | mahalanobis | false |
| 7 | Accept | 0.093333 | 0.042848 | 0.04 | 0.040581 | 75 | minkowski | false |
| 8 | Accept | 0.15333 | 0.039579 | 0.04 | 0.040008 | 75 | minkowski | true |
| 9 | Best | 0.02 | 0.037067 | 0.02 | 0.02001 | 4 | minkowski | false |
| 10 | Accept | 0.026667 | 0.040269 | 0.02 | 0.020012 | 8 | minkowski | false |
| 11 | Accept | 0.21333 | 0.041647 | 0.02 | 0.020008 | 69 | chebychev | true |
| 12 | Accept | 0.053333 | 0.039976 | 0.02 | 0.020009 | 5 | chebychev | true |
| 13 | Accept | 0.053333 | 0.052008 | 0.02 | 0.020009 | 1 | chebychev | true |
| 14 | Accept | 0.053333 | 0.089704 | 0.02 | 0.020008 | 5 | seuclidean | false |
| 15 | Accept | 0.053333 | 0.053743 | 0.02 | 0.020008 | 21 | seuclidean | false |
| 16 | Accept | 0.053333 | 0.091401 | 0.02 | 0.020009 | 1 | seuclidean | false |
| 17 | Accept | 0.15333 | 0.063143 | 0.02 | 0.020007 | 75 | seuclidean | false |
| 18 | Accept | 0.02 | 0.059493 | 0.02 | 0.019969 | 5 | minkowski | false |
| 19 | Accept | 0.33333 | 0.073748 | 0.02 | 0.019898 | 2 | spearman | false |
| 20 | Accept | 0.23333 | 0.067935 | 0.02 | 0.019888 | 71 | mahalanobis | false |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | NumNeighbors | Distance | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.046667 | 0.045476 | 0.02 | 0.019895 | 1 | cityblock | true |
| 22 | Accept | 0.053333 | 0.057295 | 0.02 | 0.019892 | 6 | cityblock | true |
| 23 | Accept | 0.12 | 0.057028 | 0.02 | 0.019895 | 75 | cityblock | true |
| 24 | Accept | 0.06 | 0.05025 | 0.02 | 0.019903 | 2 | cityblock | false |
| 25 | Accept | 0.033333 | 0.049075 | 0.02 | 0.019899 | 17 | cityblock | false |
| 26 | Accept | 0.12 | 0.054058 | 0.02 | 0.019907 | 74 | cityblock | false |
| 27 | Accept | 0.033333 | 0.045995 | 0.02 | 0.019894 | 7 | cityblock | false |
| 28 | Accept | 0.02 | 0.040869 | 0.02 | 0.019897 | 1 | chebychev | false |
| 29 | Accept | 0.02 | 0.096866 | 0.02 | 0.019891 | 4 | chebychev | false |
| 30 | Accept | 0.08 | 0.050688 | 0.02 | 0.019891 | 28 | chebychev | false |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 13.1433 seconds
Total objective function evaluation time: 2.2934
Best observed feasible point:
NumNeighbors Distance Standardize
____________ _________ ___________
4 minkowski false
Observed objective function value = 0.02
Estimated objective function value = 0.020124
Function evaluation time = 0.037067
Best estimated feasible point (according to models):
NumNeighbors Distance Standardize
____________ _________ ___________
5 minkowski false
Estimated objective function value = 0.019891
Estimated function evaluation time = 0.062602
Mdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
Distance: 'minkowski'
NumNeighbors: 5
Properties, Methods
学習させた分類器 Mdl は、最適な推定実行可能点に対応し、NumNeighbors、Distance、および Standardize に同じハイパーパラメーター値を使用しています。
結果を検証します。"k" 最近傍分類器で標準化を使用しない場合、ClassificationKNN オブジェクトの Mu プロパティと Sigma プロパティは空になることに注意してください。
bestEstimatedPoint = bestPoint(Mdl.HyperparameterOptimizationResults, ... Criterion="min-visited-upper-confidence-interval")
bestEstimatedPoint=1×3 table
NumNeighbors Distance Standardize
____________ _________ ___________
5 minkowski false
classifierProperties = table(Mdl.NumNeighbors,string(Mdl.Distance), ... struct(Means=Mdl.Mu,StandardDeviations=Mdl.Sigma), ... VariableNames=["NumNeighbors","Distance","Standardize"])
classifierProperties=1×3 table
NumNeighbors Distance Standardize
____________ ___________ ___________
5 "minkowski" 1×1 struct
classifierProperties.Standardize
ans = struct with fields:
Means: []
StandardDeviations: []
入力引数
名前と値の引数
出力引数
ヒント
モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
代替方法
fitcknn はマルチクラス KNN 分類器を学習させることができます。また、fitcecoc を使用して、マルチクラス学習問題を一連の KNN バイナリ学習器に縮小できます。