predict
k 最近傍分類モデルの使用によるラベルの予測
説明
例
フィッシャーのアヤメのデータに対して k 最近傍分類器を作成します。ここで k = 5 です。新しいデータでいくつかのモデル予測を評価します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas;
Y = species;5 つの最近傍について分類器を作成します。非カテゴリカル予測子データを標準化します。
mdl = fitcknn(X,Y,'NumNeighbors',5,'Standardize',1);
最小、平均および最大の特性をもつ花の分類を予測します。
Xnew = [min(X);mean(X);max(X)]; [label,score,cost] = predict(mdl,Xnew)
label = 3×1 cell
{'versicolor'}
{'versicolor'}
{'virginica' }
score = 3×3
0.4000 0.6000 0
0 1.0000 0
0 0 1.0000
cost = 3×3
0.6000 0.4000 1.0000
1.0000 0 1.0000
1.0000 1.0000 0
スコア行列とコスト行列の 2 行目および 3 行目にはバイナリ値が格納されます。つまり、花の測定値の平均値と最大値に対する 5 つの最近傍はすべて同じ分類になります。
"k" 最近傍分類器にさまざまな "k" の値で学習させ、分類器の判定境界を比較します。
fisheriris データ セットを読み込みます。
load fisheririsこのデータ セットには、3 種のアヤメの花のがく片と花弁からの長さと幅の測定値が含まれています。がく片の長さと幅および観測済みのすべての setosa 種のアヤメを削除します。
inds = ~strcmp(species,'setosa');
X = meas(inds,3:4);
species = species(inds); バイナリ ラベル変数 y を作成します。ラベルは、virginica 種のアヤメが 1 で、versicolor 種が 0 です。
y = strcmp(species,'virginica');"k" 最近傍分類器に学習させます。検出する最近傍の数として 5 を指定し、予測子データを標準化します。
EstMdl = fitcknn(X,y,'NumNeighbors',5,'Standardize',1)
EstMdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [0 1]
ScoreTransform: 'none'
NumObservations: 100
Distance: 'euclidean'
NumNeighbors: 5
Properties, Methods
EstMdl は学習させた ClassificationKNN 分類器です。そのプロパティの一部がコマンド ウィンドウに表示されます。
2 つのアヤメの種類をそれらの特徴に基づいて区別する判定境界の線をプロットします。
x1 = min(X(:,1)):0.01:max(X(:,1)); x2 = min(X(:,2)):0.01:max(X(:,2)); [x1G,x2G] = meshgrid(x1,x2); XGrid = [x1G(:),x2G(:)]; pred = predict(EstMdl,XGrid); figure gscatter(XGrid(:,1),XGrid(:,2),pred,[1,0,0;0,0.5,1]) hold on plot(X(y == 0,1),X(y == 0,2),'ko', ... X(y == 1,1),X(y == 1,2),'kx') xlabel('Petal length (cm)') ylabel('Petal width (cm)') title('{\bf 5-Nearest Neighbor Classifier Decision Boundary}') legend('Versicolor Region','Virginica Region', ... 'Sampled Versicolor','Sampled Virginica', ... 'Location','best') axis tight hold off

赤と青の領域間の分割が判定境界です。近傍数 "k" を変更すると、境界が変化します。
k = 1 (fitcknn の NumNeighbors の既定値) と k = 20 を使用して分類器に再学習させます。
EstMdl1 = fitcknn(X,y); pred1 = predict(EstMdl1,XGrid); EstMdl20 = fitcknn(X,y,'NumNeighbors',20); pred20 = predict(EstMdl20,XGrid); figure gscatter(XGrid(:,1),XGrid(:,2),pred1,[1,0,0;0,0.5,1]) hold on plot(X(y == 0,1),X(y == 0,2),'ko', ... X(y == 1,1),X(y == 1,2),'kx') xlabel('Petal length (cm)') ylabel('Petal width (cm)') title('{\bf 1-Nearest Neighbor Classifier Decision Boundary}') legend('Versicolor Region','Virginica Region', ... 'Sampled Versicolor','Sampled Virginica', ... 'Location','best') axis tight hold off

figure gscatter(XGrid(:,1),XGrid(:,2),pred20,[1,0,0;0,0.5,1]) hold on plot(X(y == 0,1),X(y == 0,2),'ko', ... X(y == 1,1),X(y == 1,2),'kx') xlabel('Petal length (cm)') ylabel('Petal width (cm)') title('{\bf 20-Nearest Neighbor Classifier Decision Boundary}') legend('Versicolor Region','Virginica Region', ... 'Sampled Versicolor','Sampled Virginica', ... 'Location','best') axis tight hold off
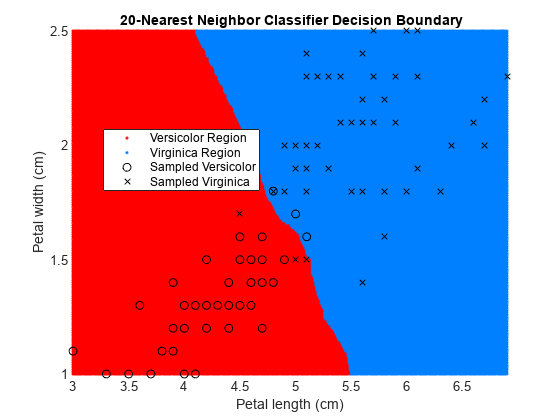
"k" が増えると判定境界が線形化しているように見えます。この線形化は、アルゴリズムで重み付けされる各入力の重要度が "k" の増加に伴って下がることによるものです。k = 1 の場合、ほぼすべての学習標本の種類がアルゴリズムで正しく予測されています。k = 20 の場合は、学習セット内でのアルゴリズムによる誤分類率が高くなっています。"k" の最適値は、fitcknn の名前と値の引数 OptimizeHyperparameters を使用して探すことができます。例については、当てはめた KNN 分類器の最適化を参照してください。
入力引数
出力引数
アルゴリズム
代替機能
Simulink ブロック
Simulink® に最近傍分類モデルの予測を統合するには、Statistics and Machine Learning Toolbox™ ライブラリにある ClassificationKNN Predict ブロックを使用するか、MATLAB® Function ブロックを関数 predict と共に使用します。例については、ClassificationKNN Predict ブロックの使用によるクラス ラベルの予測とMATLAB Function ブロックの使用によるクラス ラベルの予測を参照してください。
使用するアプローチを判断する際は、以下を考慮してください。
Statistics and Machine Learning Toolbox ライブラリ ブロックを使用する場合、固定小数点ツール (Fixed-Point Designer)を使用して浮動小数点モデルを固定小数点に変換できます。
MATLAB Function ブロックを関数
predictと共に使用する場合は、可変サイズの配列に対するサポートを有効にしなければなりません。MATLAB Function ブロックを使用する場合、予測の前処理や後処理のために、同じ MATLAB Function ブロック内で MATLAB 関数を使用することができます。
拡張機能
バージョン履歴
R2012a で導入