categorical
カテゴリに割り当てられた値を含む配列
説明
categorical は、High、Med、Low などの離散カテゴリの有限集合に値を割り当てるデータ型です。これらのカテゴリには High > Med > Low などの数学的な順序を指定することができますが、必須ではありません。categorical 配列は、非数値データを効率的に格納し操作するのに適しており、値に付けられたわかりやすい名前も維持されます。一般的に、categorical 配列は table の行のグループを定義するために使用します。
作成
categorical 配列を作成するには、次のようにします。
以下に説明するように
categorical関数を使用します。discretize関数を使用して連続データをビン化します。ビンを categorical 配列として返します。2 つの categorical 配列を乗算します。この積は、カテゴリが 2 つのオペランドのカテゴリのすべての可能な組み合わせである categorical 配列です。
構文
説明
C = categorical(A,___,Name=Value)Ordinal を true に設定します。
入力引数
名前と値の引数
出力引数
例
気象計コードのリストから categorical 配列を作成します。次に、それを温度測定値の table に追加します。categorical 配列を使用すると、table 内のデータをカテゴリ別に解析できます。
まず、気象計コードの配列を作成します。
Stations = ["S1" "S2" "S1" "S3" "S2"]
Stations = 1×5 string
"S1" "S2" "S1" "S3" "S2"
気象計コードから categorical 配列を作成するには、categorical 関数を使用します。
Stations = categorical(Stations)
Stations = 1×5 categorical
S1 S2 S1 S3 S2
そのカテゴリを表示します。3 つの気象計コードがカテゴリです。
categories(Stations)
ans = 3×1 cell
{'S1'}
{'S2'}
{'S3'}
次に、気象データを含む table を作成します。この table には、温度、日付、および気象計コードが含まれています。
Temperatures = [58;72;56;90;76]; Dates = datetime(["2017-04-17";"2017-04-18";"2017-04-30";"2017-05-01";"2017-04-27"]); Stations = Stations'; tempReadings = table(Temperatures,Dates,Stations)
tempReadings=5×3 table
Temperatures Dates Stations
____________ ___________ ________
58 17-Apr-2017 S1
72 18-Apr-2017 S2
56 30-Apr-2017 S1
90 01-May-2017 S3
76 27-Apr-2017 S2
table 内のデータを気象計別に分類します。たとえば、気象計 S2 のデータを含む table の行を返します。Stations が S2 に等しいかどうかを示す論理インデックスの配列を使用して table にインデックスを付けます。
TF = (tempReadings.Stations == "S2")TF = 5×1 logical array
0
1
0
0
1
tempReadings(TF,:)
ans=2×3 table
Temperatures Dates Stations
____________ ___________ ________
72 18-Apr-2017 S2
76 27-Apr-2017 S2
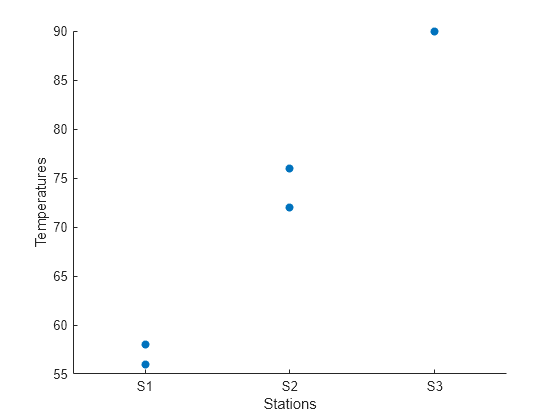
気象計に関連付けられたデータのパターンを見つけるために、気象計別の温度測定値の散布図を作成します。
scatter(tempReadings,"Stations","Temperatures","filled")
string 配列を categorical 配列に変換します。categorical 配列に、元の配列に存在しない値を含むカテゴリのセットが含まれていることを指定します。
まず、繰り返しの値のセットを含む string 配列を作成します。
A = ["red" "blue" "blue" "blue" "blue" "red"]
A = 1×6 string
"red" "blue" "blue" "blue" "blue" "red"
string 配列を categorical 配列に変換します。カテゴリを指定します。カテゴリとして green を含めます。
valueset = ["blue" "red" "green"]; C = categorical(A,valueset)
C = 1×6 categorical
red blue blue blue blue red
categorical 配列のカテゴリを表示します。入力 string 配列からのものではないカテゴリが含まれています。
categories(C)
ans = 3×1 cell
{'blue' }
{'red' }
{'green'}
数値配列を作成します。
A = [1 3 2; 2 1 3; 3 1 2]
A = 3×3
1 3 2
2 1 3
3 1 2
数値配列を categorical 配列に変換します。カテゴリの値と名前を指定します。
C = categorical(A,[1 2 3],["red" "green" "blue"])
C = 3×3 categorical
red blue green
green red blue
blue red green
そのカテゴリを表示します。
categories(C)
ans = 3×1 cell
{'red' }
{'green'}
{'blue' }
C は順序 categorical 配列でありません。したがって、C 内の値の比較には、等号演算子 == および ~= のみを使用できます。
カテゴリ red に属する要素を検索します。論理インデックス付けを使用してこれらの要素にアクセスします。
TF = (C == "red")TF = 3×3 logical array
1 0 0
0 1 0
0 1 0
C(TF)
ans = 3×1 categorical
red
red
red
既定では、categorical 関数は欠損値 (NaN、NaT、空の string、欠損 string など) を未定義のカテゴリ値に変換します。ただし、categorical を呼び出す際に、欠損値が属するカテゴリを指定できます。
たとえば、空の string と欠損 string を含む string 配列を作成します。
A = ["hi" "lo" missing "" "lo" "lo" "hi"]
A = 1×7 string
"hi" "lo" <missing> "" "lo" "lo" "hi"
まず、string 配列を、未定義の要素を含む categorical 配列に変換します。
C = categorical(A)
C = 1×7 categorical
hi lo <undefined> <undefined> lo lo hi
categories(C)
ans = 2×1 cell
{'hi'}
{'lo'}
次に、それを再度変換します。ただし、今回は欠損 string のカテゴリとして INDEF を指定します。
C = categorical(A,["lo" "hi" missing],["lo" "hi" "INDEF"])
C = 1×7 categorical
hi lo INDEF <undefined> lo lo hi
categories(C)
ans = 3×1 cell
{'lo' }
{'hi' }
{'INDEF'}
欠損 string と空の string の両方のカテゴリとして INDEF を指定します。
C = categorical(A,["lo" "hi" missing ""],["lo" "hi" "INDEF" "INDEF"])
C = 1×7 categorical
hi lo INDEF INDEF lo lo hi
categories(C)
ans = 3×1 cell
{'lo' }
{'hi' }
{'INDEF'}
5 行 2 列の数値配列を作成します。
A = [3 2;3 3;3 2;2 1;3 2]
A = 5×2
3 2
3 3
3 2
2 1
3 2
A を順序 categorical 配列に変換します。ここで、1、2、3 は、それぞれカテゴリ child、adult、senior を表します。
valueset = [1 2 3]; catnames = ["child" "adult" "senior"]; C = categorical(A,valueset,catnames,Ordinal=true)
C = 5×2 categorical
senior adult
senior senior
senior adult
adult child
senior adult
C は順序配列であるため、C のカテゴリは、数学的な順序 child < adult < senior になります。順序カテゴリ値では、すべての関係演算子を使用できます。たとえば、adult より大きい値をもつ要素を返します。
TF = C > "adult"TF = 5×2 logical array
1 0
1 1
1 0
0 0
1 0
C(TF)
ans = 5×1 categorical
senior
senior
senior
senior
senior
NaN の配列を作成して categorical 配列に変換することにより、任意のサイズの categorical 配列を事前割り当てできます。配列を事前割り当てした後、カテゴリ名を指定してカテゴリを配列に追加することにより、カテゴリを初期化できます。
最初に、NaN の配列を作成します。任意のサイズの配列を作成できます。たとえば、NaN の 2 行 4 列の配列を作成します。
A = NaN(2,4)
A = 2×4
NaN NaN NaN NaN
NaN NaN NaN NaN
その後、NaN の配列を変換して、categorical 配列を事前割り当てします。関数 categorical は、NaN を未定義の categorical 値に変換します。NaN が "not a number" (非数) を表すのと同様に、<undefined> はカテゴリに属さない categorical 値を表します。
C = categorical(A)
C = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
実際、この時点では C にはカテゴリがありません。
categories(C)
ans = 0×0 empty cell array
C のカテゴリを初期化するには、addcats 関数を使用して、カテゴリ名を指定し C に追加します。たとえば、small、medium、および large を、C の 3 つのカテゴリとして追加します。
C = addcats(C,["small" "medium" "large"])
C = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
C の要素は未定義値ですが、カテゴリは addcats により初期化されています。
categories(C)
ans = 3×1 cell
{'small' }
{'medium'}
{'large' }
C にカテゴリが存在するようになったため、定義済みの categorical 値を C の要素として割り当てることができます。
C(1) = "medium"; C(8) = "small"; C(3:5) = "large"
C = 2×4 categorical
medium large large <undefined>
<undefined> large <undefined> small
discretize 関数は、連続データからカテゴリを作成する場合、特に間隔の狭い入力値がある場合に推奨されます。2 つの値の間隔が狭いとは、2 つの値の差が約 5e-5 未満の場合を指します。値の間隔が狭い場合、categorical 関数は値から一意のカテゴリ名を作成できません。
100 個の乱数を含む数値配列を作成します。
X = rand(100,1)
X = 100×1
0.8147
0.9058
0.1270
0.9134
0.6324
0.0975
0.2785
0.5469
0.9575
0.9649
0.1576
0.9706
0.9572
0.4854
0.8003
⋮
数値を 3 つのカテゴリにビン化するには、discretize を使用します。ビンの境界とビンのカテゴリ名を指定します。
C = discretize(X,[0 .25 .75 1],"categorical",["small" "medium" "large"])
C = 100×1 categorical
large
large
small
large
medium
small
medium
medium
large
large
small
large
large
medium
large
small
medium
large
large
large
medium
small
large
large
medium
large
medium
medium
medium
small
⋮
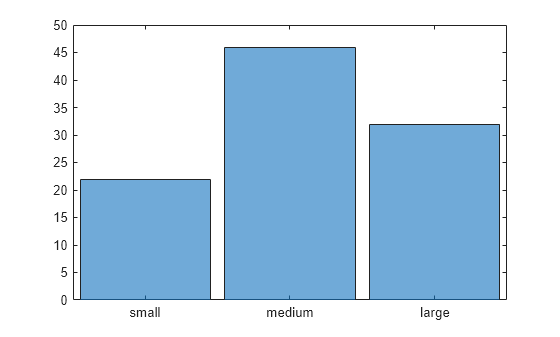
3 つのカテゴリのデータのヒストグラムをプロットします。
histogram(C)
2 つの categorical 配列を乗算すると、結果は新しいカテゴリ セットを含む 1 つの categorical 配列になります。新しいカテゴリは、元の 2 つの categorical 配列のカテゴリから作成されたすべての順序付きペアです。カテゴリの可能なすべての組み合わせのセットは、元の 2 つのカテゴリ セットの "デカルト積" としても知られています。
たとえば、2 つの categorical 配列を作成します。これらの配列には、6 人の患者の血液型と Rh 因子がリストされています。
bloodGroups = categorical(["A" "AB" "O" "O" "A" "A"], ... ["A" "B" "AB" "O"])
bloodGroups = 1×6 categorical
A AB O O A A
Rhfactors = categorical(["+" "+" "-" "-" "+" "+"])
Rhfactors = 1×6 categorical
+ + - - + +
2 つの配列のカテゴリを表示します。2 つの categorical 配列は、要素数は同じですが、異なる数のカテゴリをもつことができます。
categories(bloodGroups)
ans = 4×1 cell
{'A' }
{'B' }
{'AB'}
{'O' }
categories(Rhfactors)
ans = 2×1 cell
{'+'}
{'-'}
2 つの categorical 配列を乗算します。積の要素は、入力配列の対応する要素の組み合わせから得られます。
bloodTypes = bloodGroups .* Rhfactors
bloodTypes = 1×6 categorical
A + AB + O - O - A + A +
ただし、積の "カテゴリ" は、2 つの配列のカテゴリから作成できる "すべての" 順序付きペアです。したがって、一部のカテゴリが出力配列のどの要素でも表されない可能性があります。
categories(bloodTypes)
ans = 8×1 cell
{'A +' }
{'A -' }
{'B +' }
{'B -' }
{'AB +'}
{'AB -'}
{'O +' }
{'O -' }
制限
入力配列が数値、datetime、または duration の配列であり、入力の値からカテゴリ名を作成した場合、
categoricalは有効数字 5 桁に丸めます。たとえば、
categorical([1 1.23456789])は、これら 2 つの値からカテゴリ名1と1.2346を作成します。連続する数値、duration、または datetime のデータからカテゴリを作成するには、discretize関数を使用します。入力配列の数値、datetime、duration の値の間隔が狭すぎる場合、
categoricalはそれらの値からカテゴリ名を作成できません。一般に、値の間隔が狭すぎるとは、入力内の任意の 2 つの値の差が約5e-5未満である場合を指します。たとえば、
categorical([1 1.00001])では 2 つの数値の差が小さすぎるため、これらの数値からカテゴリ名を作成できません。連続する数値、duration、または datetime のデータからカテゴリを作成するには、discretize関数を使用します。
ヒント
categorical 配列を受け入れる関数、または返す関数の一覧については、categorical 配列を参照してください。
拡張機能
バージョン履歴
R2013b で導入