このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
predict
アンサンブル分類モデルを使用したラベルの予測
説明
例
フィッシャーのアヤメのデータ セットを読み込みます。標本サイズを調べます。
load fisheriris
N = size(meas,1);データを学習セットとテスト セットに分割します。データの 10% をテスト用にホールドアウトします。
rng(1); % For reproducibility cvp = cvpartition(N,'Holdout',0.1); idxTrn = training(cvp); % Training set indices idxTest = test(cvp); % Test set indices
学習データを table に格納します。
tblTrn = array2table(meas(idxTrn,:)); tblTrn.Y = species(idxTrn);
AdaBoostM2 と学習セットを使用してアンサンブル分類に学習させます。弱学習器として木の切り株を指定します。
t = templateTree('MaxNumSplits',1); Mdl = fitcensemble(tblTrn,'Y','Method','AdaBoostM2','Learners',t);
テスト セットについてラベルを予測します。モデルの学習にはデータの table を使用しましたが、ラベルの予測には行列を使用できます。
labels = predict(Mdl,meas(idxTest,:));
テスト セットの混同行列を作成します。
confusionchart(species(idxTest),labels)

Mdl は、テスト セット内の 1 つの versicolor 種のアヤメを virginica として誤分類します。
ブースティング木のアンサンブルを作成し、各予測子の重要度を検査します。テスト データを使用して、アンサンブルの分類精度を評価します。
不整脈データ セットを読み込みます。データのクラス表現を判別します。
load arrhythmia
Y = categorical(Y);
tabulate(Y) Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
データ セットには 16 個のクラスが含まれていますが、すべてのクラスは表現されていません (たとえば、クラス 13)。ほとんどの観測値は不整脈がないものとして分類されています (クラス 1)。このデータ セットは非常に離散的であり、クラスが不均衡です。
不整脈があるすべての観測値 (クラス 2 ~ 15) を 1 つのクラスに結合します。不整脈の状況が不明である観測値 (クラス 16) をデータ セットから削除します。
idx = (Y ~= "16"); Y = Y(idx); X = X(idx,:); Y(Y ~= "1") = "WithArrhythmia"; Y(Y == "1") = "NoArrhythmia"; Y = removecats(Y);
データを学習セットとテスト セットに均等に分割します。
rng("default") % For reproducibility cvp = cvpartition(Y,"Holdout",0.5); idxTrain = training(cvp); idxTest = test(cvp);
cvp は、学習セットとテスト セットを指定する交差検証分割オブジェクトです。
AdaBoostM1 を使用して 100 本のブースティング分類木のアンサンブルに学習をさせます。弱学習器として木の切り株を使用するように指定します。また、欠損値がデータ セットに含まれているので、代理分岐を使用するように指定します。
t = templateTree("MaxNumSplits",1,"Surrogate","on"); numTrees = 100; mdl = fitcensemble(X(idxTrain,:),Y(idxTrain),"Method","AdaBoostM1", ... "NumLearningCycles",numTrees,"Learners",t);
mdl は学習させた ClassificationEnsemble モデルです。
各予測子について重要度を調べます。
predImportance = predictorImportance(mdl); bar(predImportance) title("Predictor Importance") xlabel("Predictor") ylabel("Importance Measure")

重要度が上位 10 番目までの予測子を識別します。
[~,idxSort] = sort(predImportance,"descend");
idx10 = idxSort(1:10)idx10 = 1×10
228 233 238 93 15 224 91 177 260 277
テスト セットの観測値を分類します。混同行列を使用して結果を表示します。青色の値は正しい分類を示し、赤色の値は誤分類された観測値を示します。
predictedValues = predict(mdl,X(idxTest,:)); confusionchart(Y(idxTest),predictedValues)
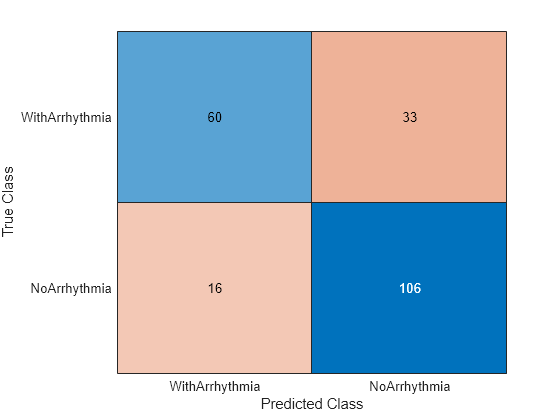
テスト セットでモデルの精度を計算します。
error = loss(mdl,X(idxTest,:),Y(idxTest), ... "LossFun","classiferror"); accuracy = 1 - error
accuracy = 0.7731
accuracy で、正しく分類された観測値の比率が推定されます。
入力引数
名前と値の引数
出力引数
詳細
代替機能
Simulink ブロック
Simulink® にアンサンブルの予測を統合するには、Statistics and Machine Learning Toolbox™ ライブラリにある ClassificationEnsemble Predict ブロックを使用するか、MATLAB® Function ブロックを関数 predict と共に使用します。例については、ClassificationEnsemble Predict ブロックの使用によるクラス ラベルの予測とMATLAB Function ブロックの使用によるクラス ラベルの予測を参照してください。
使用するアプローチを判断する際は、以下を考慮してください。
Statistics and Machine Learning Toolbox ライブラリ ブロックを使用する場合、固定小数点ツール (Fixed-Point Designer)を使用して浮動小数点モデルを固定小数点に変換できます。
MATLAB Function ブロックを関数
predictと共に使用する場合は、可変サイズの配列に対するサポートを有効にしなければなりません。MATLAB Function ブロックを使用する場合、予測の前処理や後処理のために、同じ MATLAB Function ブロック内で MATLAB 関数を使用することができます。
拡張機能
バージョン履歴
R2011a で導入