ClassificationEnsemble Predict ブロックの使用によるクラス ラベルの予測
この例では、最適なハイパーパラメーターでアンサンブル モデルの学習を行い、ClassificationEnsemble Predictブロックを Simulink® のラベル予測に使用する方法を示します。このブロックは、観測値 (予測子データ) を受け入れて、学習済みのアンサンブル分類モデルを使用することにより、その観測値の予測されたクラス ラベルとクラス スコアを返します。
最適なハイパーパラメーターでの分類モデルの学習
CreditRating_Historical データ セットを読み込みます。このデータ セットには、顧客 ID、顧客の財務比率、業種ラベル、および信用格付けが格納されています。標本サイズを調べます。
tbl = readtable('CreditRating_Historical.dat');
n = numel(tbl)n = 31456
table の最初の 3 行を表示します。
head(tbl,3)
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ _____ _____ _______ ________ _____ ________ ______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB'}
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
tbl.Industry は業種ラベルのカテゴリカル変数です。ClassificationEnsemble Predict ブロックのモデルの学習を行う場合、カテゴリカル予測子をモデルに含めるには、関数 dummyvar を使用してカテゴリカル予測子を前処理しなければなりません。名前と値の引数 'CategoricalPredictors' は使用できません。tbl.Industry についてダミー変数を作成します。
d = dummyvar(tbl.Industry);
tbl.Industry の各カテゴリに対応するダミー変数が dummyvar で作成されます。tbl.Industry のカテゴリの数と d のダミー変数の数を調べます。
unique(tbl.Industry)'
ans = 1×12
1 2 3 4 5 6 7 8 9 10 11 12
size(d)
ans = 1×2
3932 12
予測子変数の数値行列と応答変数の cell 配列を作成します。
X = [table2array(tbl(:,2:6)) d]; Y = tbl.Rating;
X は、17 個の変数 (5 個の財務比率と 12 個の業種ラベルのダミー変数) が含まれている数値行列です。tbl.ID は格付けの予測に有用ではないため、X ではこの変数は使用されません。Y は、対応する格付けが含まれている文字ベクトルの cell 配列です。
データは連続的に入手するものとし、また、はじめの 3000 個の観測値を入手しており、残りの 932 個はまだ入手していないとします。現在の標本と将来の標本にデータを分割します。
prsntX = X(1:3000,:); prsntY = Y(1:3000); ftrX = X(3001:end,:); ftrY = Y(3001:end);
現在利用できるすべてのデータ prsntX および prsntY と次のオプションを使用してアンサンブルの学習を行います。
最適なハイパーパラメーターでアンサンブルの学習を行うために、
'OptimizeHyperparameters'を'auto'に指定します。'auto'オプションは、fitcensembleの'Method'、'NumLearningCycles'、および'LearnRate'(適用可能な手法) と木学習器の'MinLeafSize'について最適な値を探します。再現性を得るために、乱数シードを設定し、
'expected-improvement-plus'の獲得関数を使用します。また、ランダム フォレスト アルゴリズムの再現性を得るため、木学習器の'Reproducible'をtrueに指定します。名前と値の引数
'ClassNames'を使用してクラスの順序を指定します。ClassificationEnsemble Predict ブロックの score 端子からの出力値は同じ順序です。
rng('default') t = templateTree('Reproducible',true); ensMdl = fitcensemble(prsntX,prsntY, ... 'ClassNames',{'AAA' 'AA' 'A' 'BBB' 'BB' 'B' 'CCC'}, ... 'OptimizeHyperparameters','auto','Learners',t, ... 'HyperparameterOptimizationOptions', ... struct('AcquisitionFunctionName','expected-improvement-plus'))
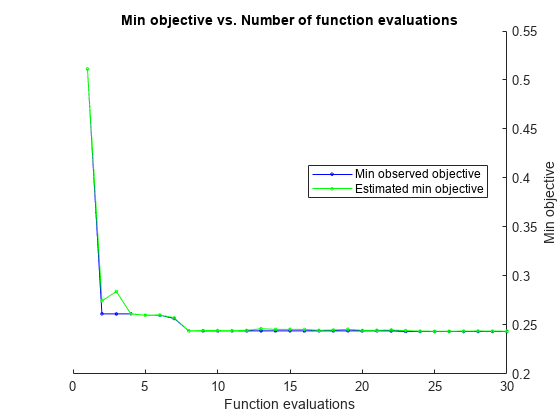
|===================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize | | | result | | runtime | (observed) | (estim.) | | ycles | | | |===================================================================================================================================| | 1 | Best | 0.51133 | 15.97 | 0.51133 | 0.51133 | AdaBoostM2 | 429 | 0.082478 | 871 | | 2 | Best | 0.26133 | 23.171 | 0.26133 | 0.27463 | AdaBoostM2 | 492 | 0.19957 | 4 | | 3 | Accept | 0.85133 | 0.83994 | 0.26133 | 0.28421 | RUSBoost | 10 | 0.34528 | 1179 | | 4 | Accept | 0.263 | 0.77678 | 0.26133 | 0.26124 | AdaBoostM2 | 13 | 0.27107 | 10 | | 5 | Best | 0.26 | 1.247 | 0.26 | 0.26003 | Bag | 10 | - | 1 | | 6 | Accept | 0.28933 | 1.8886 | 0.26 | 0.2602 | Bag | 36 | - | 101 | | 7 | Best | 0.25667 | 1.735 | 0.25667 | 0.25726 | AdaBoostM2 | 33 | 0.99501 | 11 | | 8 | Best | 0.244 | 32.962 | 0.244 | 0.24406 | Bag | 460 | - | 7 | | 9 | Accept | 0.246 | 4.7119 | 0.244 | 0.24435 | Bag | 60 | - | 4 | | 10 | Accept | 0.25533 | 1.7242 | 0.244 | 0.24437 | AdaBoostM2 | 33 | 0.99516 | 1 | | 11 | Accept | 0.25733 | 1.898 | 0.244 | 0.2442 | Bag | 25 | - | 8 | | 12 | Accept | 0.74267 | 18.987 | 0.244 | 0.24449 | Bag | 498 | - | 1462 | | 13 | Accept | 0.28433 | 10.744 | 0.244 | 0.24621 | RUSBoost | 210 | 0.0011248 | 1 | | 14 | Accept | 0.25733 | 25.844 | 0.244 | 0.24555 | Bag | 488 | - | 32 | | 15 | Accept | 0.28567 | 0.66833 | 0.244 | 0.24554 | RUSBoost | 11 | 0.18108 | 6 | | 16 | Accept | 0.25133 | 21.788 | 0.244 | 0.24547 | AdaBoostM2 | 474 | 0.15161 | 43 | | 17 | Accept | 0.24567 | 37.148 | 0.244 | 0.24459 | Bag | 490 | - | 3 | | 18 | Accept | 0.26033 | 21.358 | 0.244 | 0.2449 | AdaBoostM2 | 472 | 0.017039 | 24 | | 19 | Accept | 0.28467 | 1.0004 | 0.244 | 0.24561 | RUSBoost | 19 | 0.95267 | 2 | | 20 | Best | 0.244 | 35.361 | 0.244 | 0.24454 | Bag | 486 | - | 3 | |===================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize | | | result | | runtime | (observed) | (estim.) | | ycles | | | |===================================================================================================================================| | 21 | Accept | 0.26 | 1.0501 | 0.244 | 0.24458 | AdaBoostM2 | 20 | 0.88583 | 35 | | 22 | Accept | 0.24733 | 31.308 | 0.244 | 0.24487 | Bag | 448 | - | 5 | | 23 | Best | 0.24333 | 36.065 | 0.24333 | 0.24427 | Bag | 497 | - | 3 | | 24 | Accept | 0.24333 | 38.869 | 0.24333 | 0.24374 | Bag | 499 | - | 2 | | 25 | Accept | 0.24367 | 36.523 | 0.24333 | 0.24366 | Bag | 482 | - | 2 | | 26 | Accept | 0.257 | 21.389 | 0.24333 | 0.24364 | AdaBoostM2 | 487 | 0.72228 | 85 | | 27 | Accept | 0.31167 | 19.351 | 0.24333 | 0.24372 | RUSBoost | 445 | 0.012747 | 101 | | 28 | Accept | 0.32033 | 23.955 | 0.24333 | 0.24386 | RUSBoost | 487 | 0.82301 | 31 | | 29 | Accept | 0.244 | 39.404 | 0.24333 | 0.24372 | Bag | 476 | - | 2 | | 30 | Accept | 0.261 | 0.93501 | 0.24333 | 0.24367 | Bag | 10 | - | 2 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 518.9828 seconds
Total objective function evaluation time: 508.672
Best observed feasible point:
Method NumLearningCycles LearnRate MinLeafSize
______ _________________ _________ ___________
Bag 497 NaN 3
Observed objective function value = 0.24333
Estimated objective function value = 0.24424
Function evaluation time = 36.0653
Best estimated feasible point (according to models):
Method NumLearningCycles LearnRate MinLeafSize
______ _________________ _________ ___________
Bag 499 NaN 2
Estimated objective function value = 0.24367
Estimated function evaluation time = 38.7372
ensMdl =
ClassificationBaggedEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'AAA' 'AA' 'A' 'BBB' 'BB' 'B' 'CCC'}
ScoreTransform: 'none'
NumObservations: 3000
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
NumTrained: 499
Method: 'Bag'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: []
FitInfoDescription: 'None'
FResample: 1
Replace: 1
UseObsForLearner: [3000×499 logical]
Properties, Methods
fitcensemble は、ランダム フォレスト アルゴリズム ('Bag') が最適な手法であると特定し、ClassificationBaggedEnsembleオブジェクトを返します。
Simulink モデルの作成
この例では、ClassificationEnsemble Predictブロックを含む Simulink モデル slexCreditRatingClassificationEnsemblePredictExample.slx が用意されています。この節の説明に従って、この Simulink モデルを開くことも、新しいモデルを作成することもできます。
Simulink モデル slexCreditRatingClassificationEnsemblePredictExample.slx を開きます。
SimMdlName = 'slexCreditRatingClassificationEnsemblePredictExample';
open_system(SimMdlName)
Simulink モデルを開くと、Simulink モデルを読み込む前に、ソフトウェアがコールバック関数 PreLoadFcn のコードを実行します。slexCreditRatingClassificationEnsemblePredictExample のコールバック関数 PreLoadFcn には、学習済みモデルの変数 ensMdl がワークスペースにあるかどうかをチェックするコードが含まれています。ワークスペースに変数がない場合、PreLoadFcn は標本データを読み込み、最適なハイパーパラメーターを使用してモデルに学習させ、Simulink モデルの入力信号を作成します。コールバック関数を表示するには、[モデル化] タブの [設定] セクションで、[モデル設定] をクリックし、[モデル プロパティ] を選択します。次に、[コールバック] タブで、[モデルのコールバック] ペインのコールバック関数 PreLoadFcn を選択します。
新しい Simulink モデルを作成するには、[空のモデル] テンプレートを開き、ClassificationEnsemble Predict ブロックを追加します。Inport ブロックと Outport ブロックを追加して、それらを ClassificationEnsemble Predict ブロックに接続します。
ClassificationEnsemble Predict ブロックをダブルクリックして、[ブロック パラメーター] ダイアログ ボックスを開きます。[Select trained machine learning model] パラメーターを ensMdl として指定します。これは、学習済みのモデルを含むワークスペース変数の名前です。[リフレッシュ] ボタンをクリックします。ダイアログ ボックスの [Trained Machine Learning Model] に、モデル ensMdl の学習に使用されるオプションが表示されます。[Add output port for predicted class scores] チェック ボックスをオンにして、2 番目の出力端子 score を追加します。
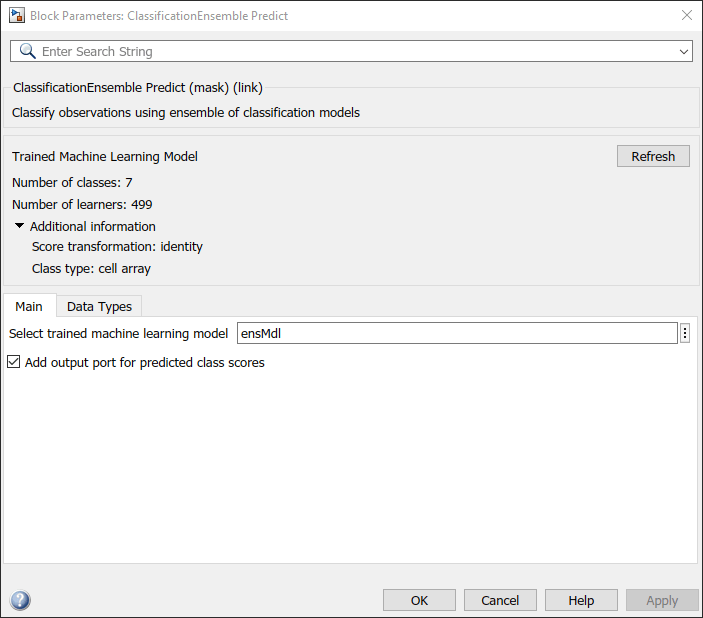
ClassificationEnsemble Predict ブロックには、17 個の予測子の値を含む観測値が必要です。Inport ブロックをダブルクリックし、[信号属性] タブで [端子の次元] を 17 に設定します。
Simulink モデルの構造体配列の形式で、入力信号を作成します。構造体配列には、次のフィールドが含まれていなければなりません。
time— 観測値がモデルに入力された時点。この例では、期間に 0 ~ 931 の整数を含めます。方向は予測子データ内の観測値に対応しなければなりません。したがって、この場合はtimeが列ベクトルでなければなりません。signals—valuesフィールドとdimensionsフィールドが含まれている、入力データを説明する 1 行 1 列の構造体配列。valuesは予測子データの行列、dimensionsは予測子変数の個数です。
将来の標本用に適切な構造体配列を作成します。
creditRatingInput.time = (0:931)'; creditRatingInput.signals(1).values = ftrX; creditRatingInput.signals(1).dimensions = size(ftrX,2);
ワークスペースから信号データをインポートするには、次を実行します。
[コンフィギュレーション パラメーター] ダイアログ ボックスを開く。[モデル化] タブで、[モデル設定] をクリック。
[データのインポート/エクスポート] ペインで [入力] チェック ボックスをオンにし、隣のテキスト ボックスに「
creditRatingInput」と入力。[ソルバー] ペインの [シミュレーション時間] で、[終了時間] を
creditRatingInput.time(end)に設定。[ソルバーの選択] で、[タイプ] をFixed-stepに、[ソルバー] をdiscrete (no continuous states)に設定。
詳細は、シミュレーションのための信号データの読み込み (Simulink)を参照してください。
モデルをシミュレートします。
sim(SimMdlName);
Inport ブロックでは、観測値を検出すると、その観測値を ClassificationEnsemble Predict ブロックに送ります。シミュレーション データ インスペクター (Simulink)を使用して、Outport ブロックのログ データを表示できます。
参考
ClassificationEnsemble Predict