ClassificationTree Predict ブロックの使用によるクラス ラベルの予測
この例では、分類学習器アプリを使用して分類決定木モデルの学習を行い、ClassificationTree Predictブロックを Simulink® のラベル予測に使用する方法を示します。このブロックは、観測値 (予測子データ) を受け入れて、学習済みの分類決定木モデルを使用することにより、その観測値の予測されたクラス ラベルとクラス スコアを返します。
分類学習器アプリにおける分類モデルの学習
分類学習器アプリでハイパーパラメーターの最適化を使用して、分類決定木モデルの学習を行います。
1.MATLAB® コマンド ウィンドウで、ionosphere データ セットを読み込みます。これには、レーダー反射の品質 (Y) と、34 個の変数の予測子データ (X) が含まれます。レーダー反射の品質は良好 ('g') または不良 ('b') のいずれかです。
ionosphere データ セットを読み込みます。標本サイズを調べます。
load ionosphere
n = numel(Y)n = 351
レーダー反射は連続的に検出されるものとし、また、はじめの 300 個の観測値を入手しており、残りの 51 個はまだ入手していないとします。現在の標本と将来の標本にデータを分割します。
prsntX = X(1:300,:); prsntY = Y(1:300); ftrX = X(301:end,:); ftrY = Y(301:end);
2.分類学習器を開きます。[アプリ] タブの [アプリ] セクションで [さらに表示] 矢印をクリックして、アプリ ギャラリーを表示します。[機械学習および深層学習] グループの [分類学習器] をクリックします。
3.[分類学習器] タブで、[ファイル] セクションの [新規セッション] をクリックし、[ワークスペースから] を選択します。
4.[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから行列 prsntX を選択します。[応答] の [ワークスペースから] オプション ボタンをクリックし、ワークスペースからベクトル prsntY を選択します。既定の検証オプションは 5 分割交差検証であるため、過適合が防止されます。この例では、既定の設定を変更しないでください。
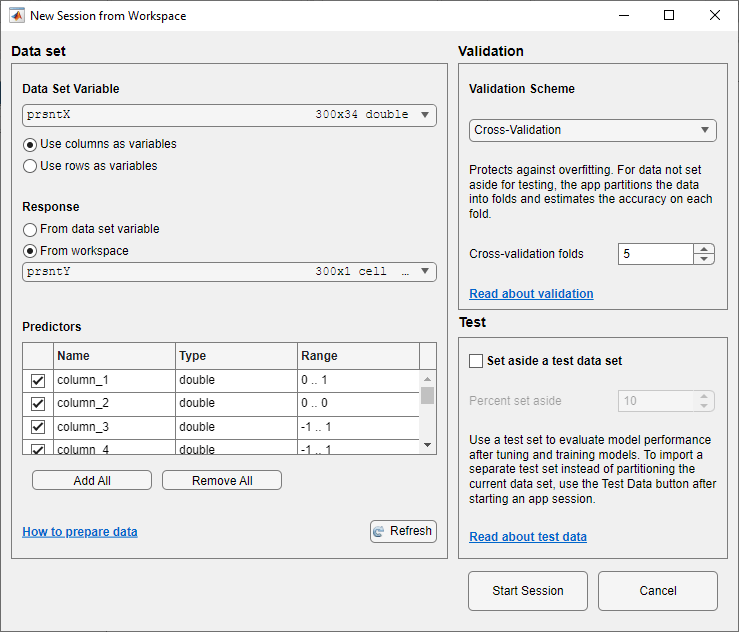
5.既定のオプションをそのまま使用して続行するため、[セッションの開始] をクリックします。
6.学習させる最適化可能なツリー モデルを選択します。[学習] タブの [モデル] セクションで [さらに表示] 矢印をクリックしてギャラリーを開きます。[決定木] グループで [最適化可能なツリー] をクリックします。

7.[学習] セクションで、[すべてを学習] をクリックして [選択を学習] を選択します。最適化プロセスが実行されると [最小分類誤差のプロット] が表示されます。反復ごとに、ハイパーパラメーター値の異なる組み合わせが試され、その反復までに観測された最小の検証分類誤差をもつプロットが更新され、濃い青で示されます。最適化プロセスが完了すると、最適化された一連のハイパーパラメーターが選択され、赤の四角形で示されます。詳細については、最小分類誤差のプロットを参照してください。
最適化されたハイパーパラメーターはプロットの右の [最適化の結果] セクションとモデルの [概要] タブの [モデルのハイパーパラメーター] セクションの両方に一覧表示されます。一般に、最適化の結果に再現性はありません。
8.モデルを MATLAB ワークスペースにエクスポートします。[分類学習器] タブで、[エクスポート] セクションの [モデルのエクスポート] をクリックし、[モデルのエクスポート] を選択して [OK] をクリックします。エクスポートされたモデルの既定の名前は trainedModel です。
あるいは、アプリでのモデルの学習時と同じ設定を使用して分類モデルの学習を行う MATLAB コードを生成できます。[分類学習器] タブの [エクスポート] セクションで [関数の生成] をクリックします。アプリによってコードがセッションから生成され、ファイルが MATLAB エディターに表示されます。ファイルでは、予測子変数と応答変数を受け入れ、分類モデルの学習を行い、交差検証を実行する関数が定義されます。関数名を trainClassificationTreeModel に変更し、関数ファイルを保存します。関数 trainClassificationTreeModel を使用して決定木分類モデルに学習をさせます。
trainedModel = trainClassificationTreeModel(prsntX,prsntY);
9.学習済みのモデルを trainedModel 変数から抽出します。trainedModel には、ClassificationTree フィールドのClassificationTreeモデル オブジェクトが含まれます。
treeMdl = trainedModel.ClassificationTree;
ハイパーパラメーターの最適化によってモデルが過適合になることがあるため、分類学習器アプリにデータをインポートする前にテスト セットを別途作成しておき、最適化されたモデルの性能をそのテスト セットで確認することを推奨します。詳細については、分類学習器アプリでハイパーパラメーターの最適化を使用した分類器の学習を参照してください。
Simulink モデルの作成
この例では、ClassificationTree Predictブロックを含む Simulink モデル slexIonosphereClassificationTreePredictExample.slx が用意されています。この節の説明に従って、この Simulink モデルを開くことも、新しいモデルを作成することもできます。
Simulink モデル slexIonosphereClassificationTreePredictExample.slx を開きます。
SimMdlName = 'slexIonosphereClassificationTreePredictExample';
open_system(SimMdlName)
Simulink モデルを開くと、Simulink モデルを読み込む前に、ソフトウェアがコールバック関数 PreLoadFcn のコードを実行します。slexIonosphereClassificationTreePredictExample のコールバック関数 PreLoadFcn には、学習済みモデルの変数 treeMdl がワークスペースにあるかどうかをチェックするコードが含まれています。ワークスペースに変数がない場合、PreLoadFcn は標本データを読み込み、ツリー モデルに学習させ、Simulink モデルの入力信号を作成します。コールバック関数を表示するには、[モデル化] タブの [設定] セクションで、[モデル設定] をクリックし、[モデル プロパティ] を選択します。次に、[コールバック] タブで、[モデルのコールバック] ペインのコールバック関数 PreLoadFcn を選択します。
新しい Simulink モデルを作成するには、[空のモデル] テンプレートを開き、ClassificationTree Predict ブロックを追加します。Inport ブロックと Outport ブロックを追加して、それらを ClassificationTree Predict ブロックに接続します。
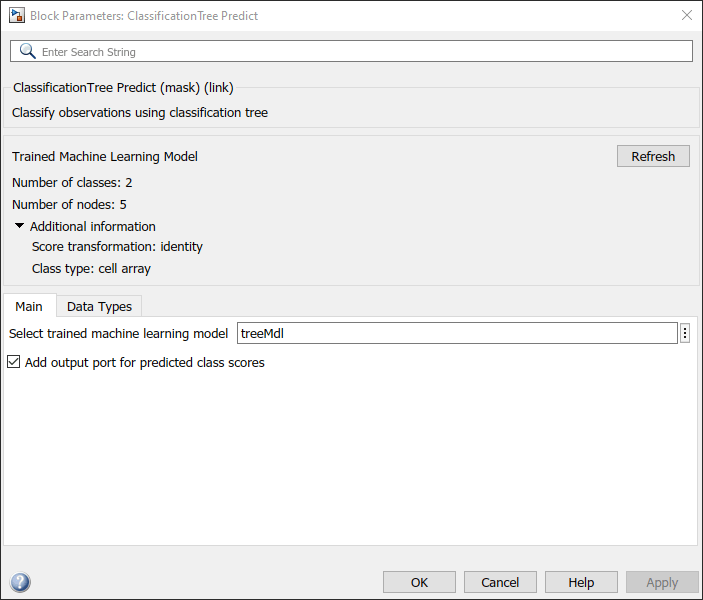
ClassificationTree Predict ブロックをダブルクリックして、[ブロック パラメーター] ダイアログ ボックスを開きます。学習済みのモデルを含むワークスペース変数の名前を指定できます。既定の変数名は treeMdl です。[リフレッシュ] ボタンをクリックします。ダイアログ ボックスの [Trained Machine Learning Model] に、モデル treeMdl の学習に使用されるオプションが表示されます。[Add output port for predicted class scores] チェック ボックスをオンにして、2 番目の出力端子 score を追加します。
ClassificationTree Predict ブロックには、34 個の予測子の値を含む観測値が必要です。Inport ブロックをダブルクリックし、[信号属性] タブで [端子の次元] を 34 に設定します。
Simulink モデルの構造体配列の形式で、入力信号を作成します。構造体配列には、次のフィールドが含まれていなければなりません。
time— 観測値がモデルに入力された時点。この例では、期間に 0 ~ 50 の整数を含めます。方向は予測子データ内の観測値に対応しなければなりません。したがって、この場合はtimeが列ベクトルでなければなりません。signals—valuesフィールドとdimensionsフィールドが含まれている、入力データを説明する 1 行 1 列の構造体配列。valuesは予測子データの行列、dimensionsは予測子変数の個数です。
将来のレーダー反射用に適切な構造体配列を作成します。
radarReturnInput.time = (0:50)'; radarReturnInput.signals(1).values = ftrX; radarReturnInput.signals(1).dimensions = size(ftrX,2);
ワークスペースから信号データをインポートするには、次を実行します。
[コンフィギュレーション パラメーター] ダイアログ ボックスを開く。[モデル化] タブで、[モデル設定] をクリック。
[データのインポート/エクスポート] ペインで [入力] チェック ボックスをオンにし、隣のテキスト ボックスに「
radarReturnInput」と入力。[ソルバー] ペインの [シミュレーション時間] で、[終了時間] を
radarReturnInput.time(end)に設定。[ソルバーの選択] で、[タイプ] をFixed-stepに、[ソルバー] をdiscrete (no continuous states)に設定。
詳細は、シミュレーションのための信号データの読み込み (Simulink)を参照してください。
モデルをシミュレートします。
sim(SimMdlName);
Inport ブロックでは、観測値を検出すると、その観測値を ClassificationTree Predict ブロックに送ります。シミュレーション データ インスペクター (Simulink)を使用して、Outport ブロックのログ データを表示できます。