このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
分類学習器アプリでハイパーパラメーターの最適化を使用した分類器の学習
この例では、分類学習器アプリでハイパーパラメーターの最適化を使用して分類サポート ベクター マシン (SVM) モデルのハイパーパラメーターを調整する方法を示します。学習済み最適化可能な SVM のテスト セット性能を、事前設定された最適な SVM モデルと比較します。
MATLAB® コマンド ウィンドウで、
ionosphereデータ セットを読み込み、データが含まれている table を作成します。load ionosphere tbl = array2table(X); tbl.Y = Y;分類学習器を開きます。[アプリ] タブをクリックしてから、[アプリ] セクションの右にある矢印をクリックしてアプリ ギャラリーを開きます。[機械学習および深層学習] グループの [分類学習器] をクリックします。
[学習] タブの [ファイル] セクションで、[新規セッション]、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから
[tbl]を選択します。応答変数と予測子変数が選択されます。既定の応答変数は[Y]です。既定の検証オプションは 5 分割交差検証であり、過適合が防止されます。[テスト] セクションで、[テスト データ セットの確保] チェック ボックスをクリックします。インポートされたデータの
15パーセントをテスト セットとして使用するように指定します。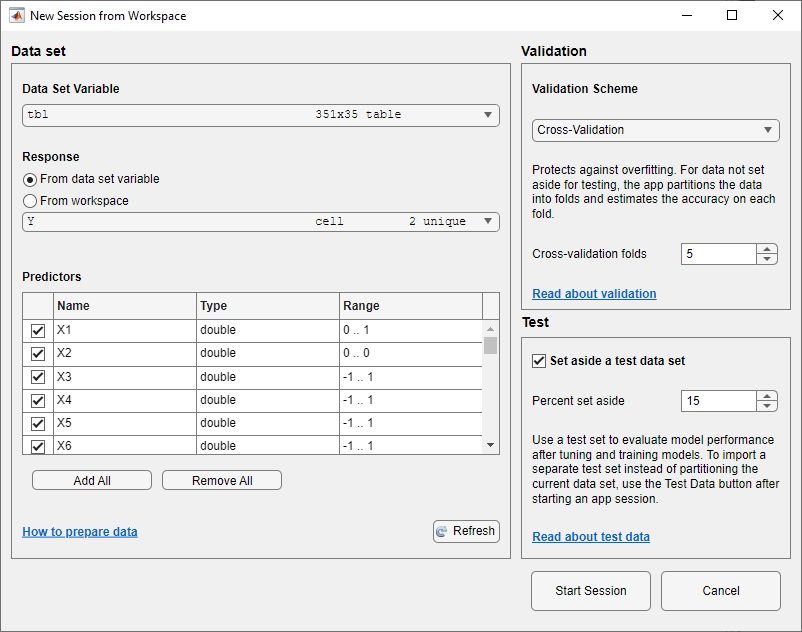
オプションはそのままで続行するため、[セッションの開始] をクリックします。
事前設定されたすべての SVM モデルに学習させます。[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。[サポート ベクター マシン] グループで [すべての SVM] をクリックします。[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。SVM モデル タイプごとに 1 つと既定の複雑な木のモデルの学習が行われ、モデルが [モデル] ペインに表示されます。
メモ
Parallel Computing Toolbox™ がある場合は、[並列の使用] ボタンが既定でオンになります。[すべてを学習] をクリックして [すべてを学習] または [選択を学習] を選択すると、ワーカーの並列プールが開きます。この間、ソフトウェアの対話的な操作はできません。プールが開いた後、モデルの学習を並列で実行しながらアプリの操作を続けることができます。
Parallel Computing Toolbox がない場合は、[すべてを学習] メニューの [バックグラウンド学習を使用] チェック ボックスが既定でオンになります。オプションを選択してモデルに学習させると、バックグラウンド プールが開きます。プールが開いた後、モデルの学習をバックグラウンドで実行しながらアプリの操作を続けることができます。
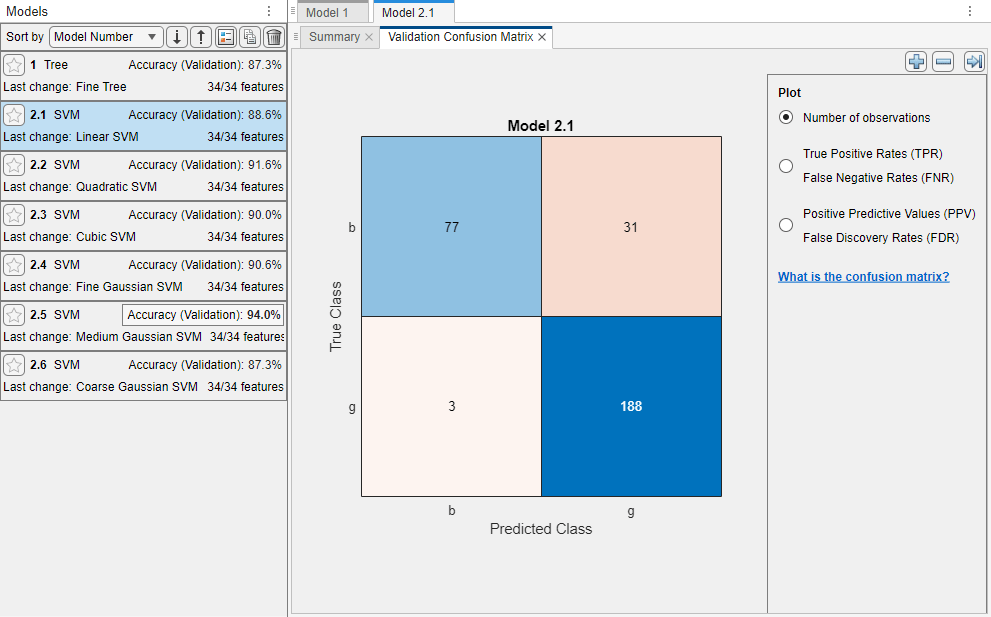
最初の SVM モデル (モデル 2.1) についての検証の混同行列が表示されます。青色の値は正しい分類を示し、赤色の値は誤った分類を示します。左の [モデル] ペインに各モデルの検証精度が表示されます。
メモ
検証により、結果に無作為性が導入されます。実際のモデルの検証結果は、この例に示されている結果と異なる場合があります。
学習させる最適化可能な SVM モデルを選択します。[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。[サポート ベクター マシン] グループで [最適化可能な SVM] をクリックします。
最適化するモデル ハイパーパラメーターを選択します。[概要] タブで、最適化するハイパーパラメーターの [最適化] チェック ボックスを選択できます。既定では、利用可能なハイパーパラメーターのすべてのチェック ボックスが選択されます。この例では、[カーネル関数] および [データの標準化] の [最適化] チェック ボックスをオフにします。カーネル関数に
[ガウス]以外の固定値がある場合は、既定で [カーネル スケール] の [最適化] チェック ボックスがオフにされます。[ガウス]カーネル関数を選択し、[カーネル スケール] の [最適化] チェック ボックスを選択します。
最適化可能なモデルに学習させます。[学習] タブの [学習] セクションで、[すべてを学習] をクリックして [選択を学習] を選択します。
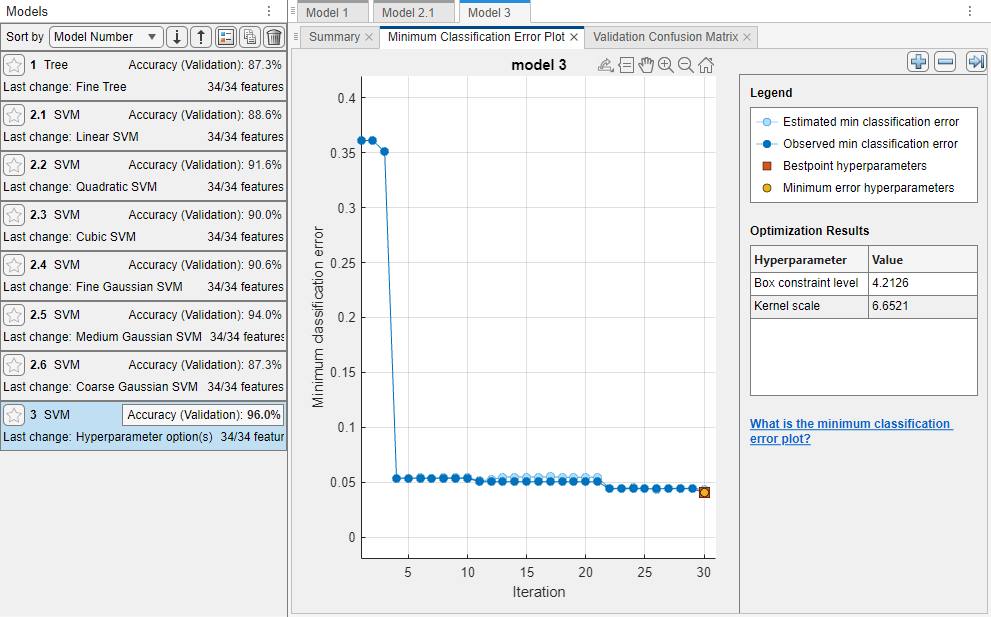
最適化プロセスが実行されると [最小分類誤差のプロット] が表示されます。反復ごとに、ハイパーパラメーター値の異なる組み合わせが試され、その反復までに観測された最小の検証分類誤差をもつプロットが更新され、濃い青で示されます。最適化プロセスが完了すると、最適化された一連のハイパーパラメーターが選択され、赤の四角形で示されます。詳細は、最小分類誤差のプロットを参照してください。
最適化されたハイパーパラメーターはプロットの右の [最適化の結果] セクションとモデルの [概要] タブの [最適化可能な SVM モデルのハイパーパラメーター] セクションの両方に一覧表示されます。
メモ
一般に、最適化の結果に再現性はありません。
学習済みの事前設定された SVM モデルを学習済み最適化可能なモデルと比較します。[モデル] ペインで、最高の [精度 (検証)] が四角で囲まれて強調表示されます。この例では、学習済み最適化可能な SVM モデルが 6 つの事前設定されたモデルよりも優れています。
学習済み最適化可能なモデルに、学習済みの事前設定されたモデルよりも高い精度が必ずあるとは限りません。学習済みの最適化可能なモデルが適切に機能しない場合、より長く最適化を実行してより優れた結果が得られるように試すことができます。[学習] タブの [オプション] セクションで [オプティマイザー] をクリックします。ダイアログ ボックスで [反復] の値を増やします。たとえば、既定値の
30をダブルクリックし、値60を入力します。その後、[保存して適用] をクリックします。オプションは、[モデル] ギャラリーを使用して作成される今後の最適化可能なモデルに適用されます。ハイパーパラメーター調整は過適合モデルになることがよくあるため、最適化された SVM モデルの性能をテスト セットでチェックし、事前設定された最適な SVM モデルの性能と比較します。アプリにデータをインポートしたときにテスト用に確保しておいたデータを使用します。
最初に、[モデル] ペインで [中程度のガウス SVM] モデルと [最適化可能な SVM] モデルの横にある星形アイコンをクリックします。
それぞれのモデルについて、[モデル] ペインでモデルを選択します。[テスト] タブの [テスト] セクションで [選択項目をテスト] をクリックします。残りのデータ、つまり学習データと検証データで学習させたモデルのテスト セットの性能が計算されます。
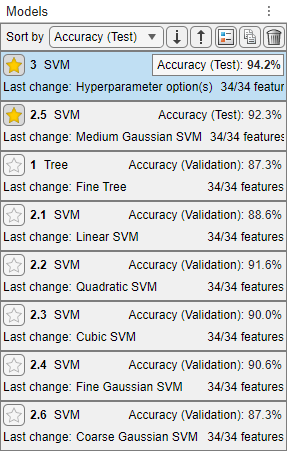
テスト セットの精度に基づいてモデルを並べ替えます。[モデル] ペインで [並べ替え] リストを開き、
[精度 (テスト)]を選択します。この例では、学習済みの最適化可能なモデルが、依然としてテスト セット データで学習済みの事前設定されたモデルよりも優れています。ただし、いずれのモデルのテスト精度も検証精度ほど高くなっていません。
モデルのテスト セット性能を視覚的に比較します。星マークが付いたモデルごとに、[モデル] ペインでモデルを選択します。[テスト] タブの [プロットと結果] セクションで [混同行列 (テスト)] をクリックします。
比較しやすくするためにプロットのレイアウトを再編成します。まず、[モデル 2.5] と [モデル 3] を除くすべてのモデルのプロットと概要のタブを閉じます。次に、[プロットと結果] セクションで [レイアウト] ボタンをクリックし、[モデルの比較] を選択します。プロットの右上にある [プロット オプションを非表示] ボタン
 をクリックして、プロットのスペースを大きくします。
をクリックして、プロットのスペースを大きくします。
元のレイアウトに戻すには、[レイアウト] ボタンをクリックし、[単一モデル (既定)] を選択します。