このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
分類器のオプションの選択
分類器のタイプの選択
分類学習器を使用すると、データに対して、選択した各種の分類モデルに自動的に学習をさせることができます。自動化された学習を使用してモデル タイプの選択を素早く試してから、有望なモデルを対話的に探すことができます。まず、次のオプションを試します。

| 最初に使用する分類器のオプション | 説明 |
|---|---|
| すべてのクイック学習 | このオプションを最初に試します。選択したデータ セットに対して利用可能なモデル タイプのすべてを学習させ、通常は高速に当てはめます。 |
| すべての線形 | このオプションは、データ内のクラス間に線形境界があると予想される場合に試します。このオプションでは、線形 SVM、効率的な線形 SVM、効率的なロジスティック回帰、および線形判別のモデルのみが当てはめられます。バイナリ クラスのデータに対してはバイナリ GLM (一般化線形モデル) ロジスティック回帰モデルも当てはめられます。 |
| すべて | このオプションは、使用可能なすべての最適化不可能なモデル タイプに学習させる場合に使用します。前に学習させたモデルであるかどうかに関係なく、すべてのタイプに学習をさせます。時間がかかる可能性があります。 |
自動化された分類器の学習を参照してください。
一度に 1 つずつの分類器を調べる場合、または必要な分類器のタイプが既にわかっている場合、個々のモデルを選択するか、同じタイプのグループに学習をさせることができます。利用可能なすべての分類器のオプションを表示するには、[学習] タブで [モデル] セクションにある矢印をクリックして分類器のリストを展開します。[モデル] ギャラリーの最適化不可能なモデル オプションは、種々の設定が事前に行われている開始点であり、さまざまな分類問題に適しています。最適化可能なモデル オプションを使用してモデル ハイパーパラメーターを自動的に調整する場合は、分類学習器アプリのハイパーパラメーターの最適化を参照してください。
問題に最適な分類器のタイプを選択するための詳細については、各種の教師あり学習アルゴリズムの一般的な特徴とそのそれぞれでバイナリまたはマルチクラスのデータに対して呼び出される MATLAB® 関数を示した表を参照してください。最終的なアルゴリズムを選択するための指針として、この表を使用してください。速度、柔軟性および解釈可能性に関するトレードオフに基づいて判断してください。最適な分類器のタイプは、データによって異なります。
ヒント
過適合を回避するには、十分な精度が得られる柔軟性が低いモデルを探してください。たとえば、高速で解釈が容易な決定木や判別分析などの単純なモデルを探します。応答を予測するにはモデルの精度が不十分である場合は、柔軟性が高い他の分類器 (アンサンブルなど) を選択します。柔軟性の制御については、各分類器のタイプの詳細を参照してください。
分類器のタイプの特徴
| 分類器 | 解釈可能性 | 関数 |
|---|---|---|
| 決定木 | 容易 | fitctree |
| 判別分析 | 容易 | fitcdiscr |
| ロジスティック回帰分類器 | 容易 | fitglm (バイナリ GLM の場合)、fitclinear、fitcecoc (マルチクラスの場合) |
| 単純ベイズ分類器 | 容易 | fitcnb |
| 線形 SVM の場合は容易 他のすべてのカーネル タイプの場合は困難 | fitcsvm、fitcecoc (マルチクラスの場合) | |
| 効率的に学習させた線形分類器 | 容易 | fitclinear、fitcecoc (マルチクラスの場合) |
| 最近傍分類器 | 困難 | fitcknn |
| カーネル近似の分類器 | 困難 | fitckernel、fitcecoc (マルチクラスの場合) |
| アンサンブル分類器 | 困難 | fitcensemble |
| ニューラル ネットワーク分類器 | 困難 | fitcnet |
分類学習器で各分類器の説明を表示するには、詳細表示に切り替えます。

ヒント
分類器のタイプ (決定木など) を選択したら、各分類器による学習を試してください。[モデル] ギャラリーの最適化不可能なオプションは、さまざまな設定による開始点となります。すべてを試して、使用するデータに最適なモデルを生成するのはどのオプションであるか確認してください。
ワークフローの指示については、分類学習器アプリにおける分類モデルの学習を参照してください。
カテゴリカル予測子のサポート
分類学習器では、選択されているデータをサポートする使用可能な分類器タイプが [モデル] ギャラリーに表示されます。
| 分類器 | すべての予測子が数値 | すべての予測子がカテゴリカル | 一部が categorical、一部が数値 |
|---|---|---|---|
| 決定木 | あり | あり | あり |
| 判別分析 | あり | なし | なし |
| ロジスティック回帰 | あり | あり | あり |
| 単純ベイズ | あり | あり | あり |
| SVM | あり | あり | あり |
| 効率的に学習させた線形 | あり | あり | あり |
| 最近傍点 | ユークリッド距離のみ | ハミング距離のみ | なし |
| カーネル近似 | あり | あり | あり |
| アンサンブル | あり | あり。ただし、部分空間判別を除く | あり。ただし、部分空間判別を除く |
| ニューラル ネットワーク | あり | あり | あり |
決定木
決定木は、解釈が容易で、当てはめや予測が高速で、メモリ使用量が少ないのですが、予測精度は低くなる可能性があります。過適合を防止するには、より単純なツリーを成長させるようにします。深さは、[最大分割数] の設定で制御します。
ヒント
[最大分割数] の設定によっては、モデルの柔軟性が向上します。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| 粗い木 | 容易 | 低 少ない葉でクラスを粗く区分 (最大分割数は 4)。 |
| 中程度の木 | 容易 | 中 中程度の数の葉でクラスを細かく区分 (最大分割数は 20)。 |
| 複雑な木 | 容易 | 高 多くの葉でクラスを非常に細かく区分 (最大分割数は 100)。 |
ヒント
[モデル] ギャラリーで [すべての木] をクリックして、最適化不可能な決定木の各オプションを試してください。すべてを試して、使用するデータに最適なモデルを生成するのはどの設定であるかを調べます。[モデル] ペインで最適なモデルを選択します。モデルを改善するには、特徴選択を試してから詳細なオプションを変更します。
データに対する応答を予測するように分類木を学習させます。応答を予測するには、ツリーのルート (開始) ノードから葉ノードの方向に意思決定を行います。葉ノードには応答が含まれています。Statistics and Machine Learning Toolbox™ のツリーは二分木です。予測の各段階では、1 つの予測子 (変数) について値のチェックが行われます。たとえば、次の図は単純な分類木を示しています。

このツリーでは、2 つの予測子 x1 と x2 に基づいて分類を予測します。予測は最上位のノードから始まります。各決定では、予測子の値をチェックして、どの分岐に進むかを決定します。分岐が葉ノードに達すると、データは 0 または 1 のタイプに分類されます。
モデルをアプリからエクスポートして次のように入力すると、決定木モデルを可視化できます。
view(trainedModel.ClassificationTree,"Mode","graph")
fisheriris のデータで学習させた複雑な木の例を示しています。
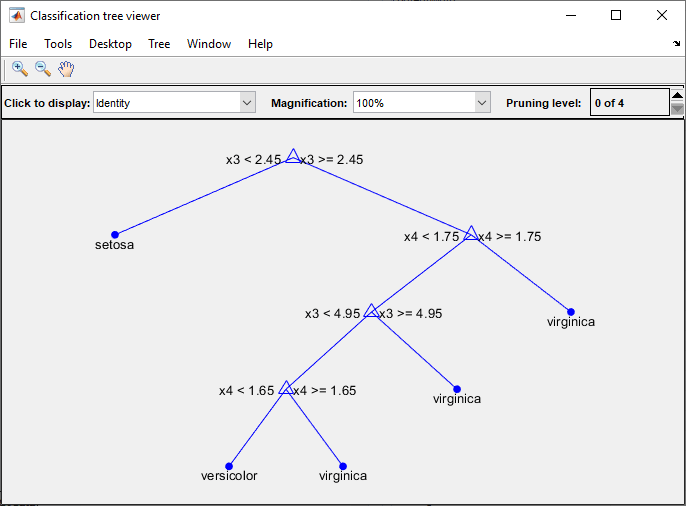
ヒント
たとえば、分類学習器アプリを使用した決定木の学習を参照してください。
木モデルのハイパーパラメーターのオプション
分類学習器では、分類木に関数 fitctree を使用します。次のオプションを設定できます。
最大分割数
最大分割数または分岐点の最大数を指定して、ツリーの深さを制御します。決定木を成長させるときは、単純さと予測力を考慮してください。分割数を変更するには、ボタンをクリックするか、正の整数値を [最大分割数] ボックスに入力します。
通常、葉の数が多い複雑な木では学習データに対する精度が高くなります。しかし、独立したテスト セットに対しては同等の精度にならない場合があります。リーフが多いツリーは過学習になる傾向があるので、多くの場合、検証精度は学習 (再代入) 精度よりはるかに低くなります。
対照的に、粗い木では学習精度が高くなりません。しかし、代表的なテスト セットの精度に学習精度が近づく可能性があるという点で、粗い木の方がロバストになる可能性があります。また、粗い木は解釈が容易です。
分割条件
どのような場合にノードを分割するかを決定する条件を指定します。3 つの設定をそれぞれ試して、使用するデータに対してモデルの性能が向上するかどうかを確認してください。
分割条件のオプションは、
[ジニ多様性指数]、[Twoing 規則]、[最大逸脱度減少量](クロス エントロピー) です。分類木では、1 つのクラスのみが含まれている純粋なノードに最適化しようとします。ジニ多様性指数 (既定) と最大逸脱度の条件では、ノードの純粋さを評価します。Twoing 規則は、ノードの分割方法を決定する別の計測であり、Twoing 規則の式を最大化してノードの純粋さを向上させます。
これらの分割条件の詳細については、
ClassificationTreeの詳細を参照してください。[代理決定分岐] ― 欠損データがある場合のみ
決定分岐に代理を使用するよう指定します。データに欠損値が含まれている場合、代理分岐を使用すると予測の精度が向上します。
[代理決定分岐] を
[オン]に設定した場合、分類木では最大 10 個の代理分岐が各枝ノードで探索されます。この数を変更するには、ボタンをクリックするか、[ノードごとの最大代理数] ボックスに正の整数値を入力します。[代理決定分岐] を
[すべて検索]に設定した場合、分類木ではすべての代理分岐が各枝ノードで探索されます。[すべて検索]に設定すると、時間とメモリが大量に使用される可能性があります。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
判別分析
判別分析は一般的な分類アルゴリズムであり、高速かつ精度が高く、解釈が容易なので、はじめに試してみてください。判別分析は、幅広いデータセットに適しています。
判別分析では、異なるクラスは異なるガウス分布に基づいてデータを生成すると仮定します。分類器を学習させるため、近似関数で各クラスについてガウス分布のパラメーターを推定します。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| 線形判別 | 容易 | 低 クラス間に線形の境界を作成。 |
| 2 次判別 | 容易 | 低 クラス間に非線形の境界を作成 (楕円、放物線または双曲線)。 |
判別モデルのハイパーパラメーターのオプション
分類学習器では、判別分析に関数 fitcdiscr を使用します。線形判別と 2 次判別の両方について、[共分散の構造] オプションを変更できます。予測子の分散がゼロである場合または予測子の共分散行列のいずれかが特異である場合、既定の [フル] 共分散構造を使用すると学習に失敗する可能性があります。学習に失敗する場合は、代わりに [対角] 共分散構造を選択してください。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
ロジスティック回帰分類器
ロジスティック回帰は解釈が容易なので、試すべき分類アルゴリズムとして一般的です。これらの分類器では、クラスの確率を予測子の線形結合の関数としてモデル化します。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
バイナリ GLM ロジスティック回帰 R2023a より前: 以前のロジスティック回帰 | 容易 | 低 パラメーターを変更してモデルの柔軟性を制御することはできません。 |
| 効率的なロジスティック回帰 | 容易 | 中 ソルバー、lambda、およびベータ許容誤差についてのハイパーパラメーターの設定を変更できます。 |
分類学習器のバイナリ GLM ロジスティック回帰では、関数 fitglm を使用します。効率的なロジスティック回帰では、バイナリ クラスのデータには関数 fitclinear を使用し、マルチクラスのデータには関数 fitcecoc を使用します。fitclinear および fitcecoc では、多少の精度は犠牲にして学習計算の時間を短縮する手法が使用されます。多くの予測子や多くの観測値を含むデータで学習させるときは、効率的なロジスティック回帰の使用を検討してください。
ロジスティック回帰のハイパーパラメーターのオプション
バイナリ GLM 分類器については、ハイパーパラメーターのオプションは設定できません。効率的なロジスティック回帰分類器に対して設定できるハイパーパラメーターのオプションの詳細については、効率的に学習させた線形分類器のハイパーパラメーターのオプションを参照してください。
単純ベイズ分類器
単純ベイズ分類器は、解釈が容易であり、マルチクラス分類に役立ちます。単純ベイズ アルゴリズムはベイズの定理を利用しており、与えられたクラスに対して予測子が条件付きで独立していると仮定します。この独立性の仮定がデータ内の予測子に対して有効である場合、これらの分類器を使用します。ただし、このアルゴリズムは独立性の仮定が有効ではない場合でも十分に機能するようです。
カーネル単純ベイズ分類器の場合、カーネル平滑化タイプは [カーネル タイプ] の設定で、カーネル平滑化の密度サポートは [サポート] の設定で制御できます。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| ガウス単純ベイズ | 容易 | 低 パラメーターを変更してモデルの柔軟性を制御することはできません。 |
| カーネル単純ベイズ | 容易 | 中 [カーネル タイプ] と [サポート] の設定を変更すると、分類器が予測子の分布をモデル化する方法を制御できます。 |
分類学習器の単純ベイズは、関数 fitcnb を使用します。
単純ベイズ モデルのハイパーパラメーターのオプション
カーネル単純ベイズ分類器の場合、以下のオプションを設定できます。
カーネル タイプ — カーネル平滑化タイプを指定します。これらの各オプションの設定を試して、使用しているデータに対してモデルの性能が向上するかどうかを確認してください。
カーネル タイプのオプションは、
[ガウス]、[ボックス]、[Epanechnikov]、[三角形]です。サポート — カーネル平滑化の密度サポートを指定します。これらの各オプションの設定を試して、使用しているデータに対してモデルの性能が向上するかどうかを確認してください。
サポートのオプションは、
[制限なし](すべて実数値) または[正](すべて正の実数値) です。データの標準化 — 数値予測子を標準化するかどうかを指定します。予測子ごとにスケールが大きく異なる場合、標準化を行うと当てはめを向上させることができます。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
モデルを学習させる次のステップについては、分類学習器アプリにおける分類モデルの学習を参照してください。
サポート ベクター マシン
分類学習器では、データに 2 つ以上のクラスがある場合に SVM を学習させることができます。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| 線形 SVM | 容易 | 低 クラス間で単純な線形分離を実行。 |
| 2 次 SVM | 困難 | 中 |
| 3 次 SVM | 困難 | 中 |
| 細かいガウス SVM | 困難 | 高 — カーネル スケールの設定によっては低下。 カーネル スケールを sqrt(P)/4 に設定してクラスを細かく区分。 |
| 中程度のガウス SVM | 困難 | 中 カーネル スケールを sqrt(P) に設定して中程度に区分。 |
| 粗いガウス SVM | 困難 | 低 カーネル スケールを sqrt(P)*4 に設定してクラスを粗く区分 (P は予測子の個数)。 |
ヒント
[モデル] ギャラリーに表示される最適化不可能なサポート ベクター マシンの各オプションで学習を試してください。すべてを試して、使用するデータに最適なモデルを生成するのはどの設定であるかを調べます。[モデル] ペインで最適なモデルを選択します。モデルを改善するには、特徴選択を試してから詳細なオプションを変更します。
SVM では、あるクラスのデータ点を別のクラスのデータ点から分離する最適な超平面を探索することによりデータを分類します。SVM の "最適な" 超平面とは、2 つのクラス間に最大の "マージン" をもつ超平面のことです。マージンとは、内部にデータ点のない、超平面に平行するスラブ平面の最大幅を意味します。
"サポート ベクター" は分離超平面に最も近いデータ点です。これらの点はスラブの境界上にあります。次の図は、これらの定義を示しています。+ はタイプ 1 のデータ点、- はタイプ -1 のデータ点を示しています。

SVM では、ソフト マージン (すべてではないが多くのデータ点を分離する超平面) も使用できます。
SVM モデルのハイパーパラメーターのオプション
クラスの数が正確に 2 つである場合、分類学習器は関数 fitcsvm を使用して分類器を学習させます。2 つより多いクラスがある場合は関数 fitcecoc を使用して、マルチクラスの分類問題を一連のバイナリ分類による部分問題に縮小し、部分問題ごとに 1 つの SVM 学習器を使用します。バイナリおよびマルチクラス タイプの分類器のコードを確認するには、学習済みの分類器からコードを生成します。
次のオプションをアプリで設定できます。
カーネル関数
分類器を計算するためのカーネル関数を指定します。
線形カーネル (解釈が最も容易)
ガウスまたは放射基底関数 (RBF) カーネル
2 次
3 次
ボックス制約レベル
ラグランジュ乗数として許容できる値をボックス (境界がある領域) 内に収めるためのボックス制約を指定します。
SVM 分類器を調整するには、ボックス制約レベルを大きくすることを試してください。ボタンをクリックするか、正のスカラー値を [ボックス制約レベル] ボックスに入力します。ボックス制約レベルを大きくすると、サポート ベクターの数を減らすことができますが、学習時間が長くなる可能性があります。
ボックス制約パラメーターは、主問題の方程式では C として知られるソフト マージン ペナルティであり、双対問題の方程式ではハードな "ボックス" 制約です。
カーネル スケール モード
必要な場合はカーネル スケーリングを手動で指定します。
[カーネル スケール モード] を
[自動]に設定した場合、ヒューリスティック手法を使用してスケール値が選択されます。ヒューリスティック手法では副標本抽出を使用します。そのため、結果を再現するには、分類器の学習の前にrngを使用して乱数シードを設定します。[カーネル スケール モード] を
[手動]に設定した場合、値を指定できます。ボタンをクリックするか、正のスカラー値を [手動カーネル スケール] ボックスに入力します。予測子行列のすべての要素がカーネル スケールの値で除算されます。その後、適切なカーネル ノルムが適用され、グラム行列が計算されます。ヒント
カーネル スケールの設定によっては、モデルの柔軟性が低下します。
マルチクラス コーディング
クラスが 3 つ以上あるデータのみに対応しています。この手法では、マルチクラスの分類問題を一連のバイナリ分類による部分問題に縮小し、部分問題ごとに 1 つの SVM 学習器を使用します。
[1 対 1]では、クラスの各ペアについて 1 つの学習器を学習させます。この手法は、あるクラスをもう 1 つのクラスと区別する学習をします。[1 対他]では、1 つの学習器をクラスごとに学習させます。この手法は、あるクラスを他のすべてのクラスと区別することを学習をします。データの標準化
各座標距離をスケーリングするかどうかを指定します。予測子ごとにスケールが大きく異なる場合、標準化を行うと当てはめを向上させることができます。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
効率的に学習させた線形分類器
効率的に学習させた線形分類器では、多少の精度は犠牲にして学習計算の時間を短縮する手法が使用されます。ロジスティック回帰とサポート ベクター マシン (SVM) の効率的に学習させたモデルを使用できます。多くの予測子や多くの観測値を含むデータで学習させるときは、既存のバイナリ GLM ロジスティック回帰または線形 SVM の事前設定されたモデルの代わりに、効率的に学習させた線形分類器の使用を検討してください。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| 効率的なロジスティック回帰 | 容易 | 中 ソルバー、lambda、およびベータ許容誤差についてのハイパーパラメーターの設定を変更できます。 |
| 効率的な線形 SVM | 容易 | 中 ソルバー、lambda、およびベータ許容誤差についてのハイパーパラメーターの設定を変更できます。 |
効率的に学習させた線形分類器のハイパーパラメーターのオプション
効率的に学習させた線形分類器では、バイナリ クラスのデータには関数 fitclinear を使用し、マルチクラスのデータには関数 fitcecoc を使用します。次のオプションを設定できます。
ソルバー
目的関数の最小化手法を指定します。[自動] 設定では [BFGS] ソルバーが使用されます。モデルに 100 を超える予測子がある場合は、[自動] 設定で、効率的なロジスティック回帰には [SGD] ソルバー、効率的な線形 SVM には [双対 SGD] ソルバーが使用されます。効率的なロジスティック回帰分類器には [双対 SGD] ソルバー設定は使用できないことに注意してください。ソルバーの詳細については、
Solverを参照してください。正則化 — 複雑度ペナルティのタイプとして、LASSO (L1) ペナルティまたはリッジ (L2) ペナルティのいずれかを指定します。他のハイパーパラメーターの値に応じて、利用可能な正則化のオプションには
[LASSO]、[リッジ]、[自動]があります。このオプションを
[自動]に設定すると、モデルで SpaRSA ソルバーを使用している場合は LASSO ペナルティ、それ以外の場合はリッジ ペナルティが選択されます。詳細については、Regularizationを参照してください。正則化強度 (Lambda)
正則化強度パラメーターを指定します。[自動] 設定では、lambda が 1/n と等しい値に設定されます。ここで、n は学習標本内の観測値の数 (交差検証を使用する場合は分割内観測値の数) です。正則化強度の詳細については、
Lambdaを参照してください。係数の相対許容誤差 (ベータ許容誤差)
線形係数とバイアス項の相対許容誤差を指定します。これは、最適化が終了するタイミングに影響します。既定値は 0.0001 です。ベータ許容誤差の詳細については、
BetaToleranceを参照してください。マルチクラス コーディング — マルチクラス問題を一連のバイナリ部分問題に縮小し、部分問題ごとに 1 つの線形学習器を使用する手法を指定します。この値はクラスの数が 2 つより多いデータに対してのみ適用されます。
[1 対 1]では、クラスの各ペアについて 1 つの学習器を学習させます。この手法では、あるクラスをもう 1 つの別のクラスと区別して学習させます。[1 対他]では、1 つの学習器をクラスごとに学習させます。この手法では、あるクラスを他のすべてのクラスと区別して学習させます。
詳細については、
Codingを参照してください。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
最近傍分類器
一般に最近傍分類器は、低次元では予測精度が高くなりますが、高次元では低くなる可能性があります。メモリ使用量が多く、解釈は容易ではありません。
ヒント
[近傍の数] の設定によってはモデルの柔軟性が低下します。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| 細かい KNN | 困難 | クラスを細かく区分。近傍数を 1 に設定。 |
| 中程度の KNN | 困難 | クラスを中程度に区分。近傍数を 10 に設定。 |
| 粗い KNN | 困難 | クラスを粗く区分。近傍数を 100 に設定。 |
| コサイン KNN | 困難 | コサイン距離計量を使用してクラスを中程度に区分。近傍数を 10 に設定。 |
| 3 次 KNN | 困難 | 3 次距離計量を使用してクラスを中程度に区分。近傍数を 10 に設定。 |
| 重み付き KNN | 困難 | 距離の重み付けを使用してクラスを中程度に区分。近傍数を 10 に設定。 |
ヒント
[モデル] ギャラリーに表示される最適化不可能な最近傍の各オプションで学習を試してください。すべてを試して、使用するデータに最適なモデルを生成するのはどの設定であるかを調べます。[モデル] ペインで最適なモデルを選択します。モデルを改善するには、[特徴選択] を試してから (任意で) [詳細設定] オプションを変更します。
k 最近傍分類とは何でしょう。学習データセット内の点 (または近傍) に対する距離に基づいてクエリ点を分類することは、新しい点を分類する方法としてシンプルでありながら効率的です。距離は、さまざまな基準を使用して決定できます。k 最近傍 (kNN) 探索では、n 個の点から構成される集合 X と距離関数が与えられると、1 つのクエリ点または一連の点に対して最も近い k 個の点を X から探索できます。kNN に基づくアルゴリズムは、ベンチマーク機械学習規則として幅広く使用されています。

KNN モデルのハイパーパラメーターのオプション
分類学習器では、最近傍分類器に関数 fitcknn を使用します。次のオプションを設定できます。
近傍の数
予測時に各点を分類するため、最近傍の数を指定します。近傍の数を変更して、細かい分類器 (小さい数) または粗い分類器 (大きい数) を指定します。たとえば、細かい KNN が使用する近傍は 1 つ、粗い KNN が使用する近傍は 100 のようにします。近傍が多いと、当てはめるのに時間がかかることがあります。
距離計量
さまざまな基準を使用して、点に対する距離を決定できます。定義については、クラス
ClassificationKNNを参照してください。距離重み付け
距離に重みを付ける関数を指定します。
[イコール](重みなし)、[逆数](重みは 1/距離) または[逆 2 乗](重みは 1/距離2) を選択できます。データの標準化
各座標距離をスケーリングするかどうかを指定します。予測子ごとにスケールが大きく異なる場合、標準化を行うと当てはめを向上させることができます。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
カーネル近似の分類器
分類学習器では、カーネル近似の分類器を使用して多数の観測値を含むデータの非線形分類を実行できます。大規模なインメモリ データに対しては、ガウス カーネルによる SVM 分類器に比べ、カーネル分類器の方が学習と予測が高速になる傾向があります。
ガウス カーネル分類モデルは、低次元空間の予測子を高次元空間にマッピングしてから、変換された予測子に高次元空間で線形モデルを当てはめます。拡張空間に SVM 線形モデルを当てはめるかロジスティック回帰線形モデルを当てはめるかを選択します。
ヒント
[モデル] ギャラリーの [すべてのカーネル] をクリックして事前設定済みのカーネル近似の各オプションを試し、使用しているデータに最適なモデルが生成されるのはどの設定であるかを調べます。最適なモデルを [モデル] ペインで選択し、特徴選択の使用と一部の詳細オプションの変更によりモデルの改善を試します。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| SVM カーネル | 困難 | 中 — [カーネル スケール] の設定を小さくすると向上 |
| ロジスティック回帰カーネル | 困難 | 中 — [カーネル スケール] の設定を小さくすると向上 |
カーネル モデルのハイパーパラメーターのオプション
クラスの数が正確に 2 つである場合、分類学習器は関数 fitckernel を使用してカーネル分類器を学習させます。2 つより多いクラスがある場合は関数 fitcecoc を使用して、マルチクラスの分類問題を一連のバイナリ分類による部分問題に縮小し、部分問題ごとに 1 つのカーネル学習器を使用します。
次のオプションを設定できます。
学習器 — 拡張空間に当てはめる線形分類モデルのタイプを指定します。
SVMまたはLogistic Regressionのいずれかになります。SVM カーネル分類器ではモデルの当てはめでヒンジ損失関数を使用するのに対し、ロジスティック回帰カーネル分類器では逸脱度 (ロジスティック) 損失を使用します。拡張次元数 — 拡張空間内の次元数を指定します。
このオプションを
[自動]に設定した場合、次元数が2.^ceil(min(log2(p)+5,15))に設定されます。pは予測子の個数です。このオプションを
[手動]に設定した場合、ボタンをクリックするかボックスに正のスカラー値を入力して値を指定できます。
正則化強度 (Lambda) — リッジ (L2) 正則化ペナルティ項を指定します。SVM 学習器を使用する場合、ボックス制約 C と正則化項の強度 λ には C = 1/(λn) という関係があります。n は観測値の個数です。
このオプションを
[自動]に設定した場合、正則化強度が 1/n に設定されます。n は観測値の個数です。このオプションを
[手動]に設定した場合、ボタンをクリックするかボックスに正のスカラー値を入力して値を指定できます。
カーネル スケール — カーネル スケーリングを指定します。この値を使用して、ランダムな特徴量拡張用のランダムな基底が取得されます。詳細については、ランダムな特徴量拡張を参照してください。
このオプションを
[自動]に設定した場合、ヒューリスティック手法を使用してスケール値が選択されます。ヒューリスティック手法では副標本抽出を使用します。そのため、結果を再現するには、分類器の学習の前にrngを使用して乱数シードを設定します。このオプションを
[手動]に設定した場合、ボタンをクリックするかボックスに正のスカラー値を入力して値を指定できます。
マルチクラス コーディング — マルチクラス問題を一連のバイナリ部分問題に縮小し、部分問題ごとに 1 つのカーネル学習器を使用する手法を指定します。この値はクラスの数が 2 つより多いデータに対してのみ適用されます。
[1 対 1]では、クラスの各ペアについて 1 つの学習器を学習させます。この手法では、あるクラスをもう 1 つの別のクラスと区別して学習させます。[1 対他]では、1 つの学習器をクラスごとに学習させます。この手法では、あるクラスを他のすべてのクラスと区別して学習させます。
データの標準化 — 数値予測子を標準化するかどうかを指定します。予測子ごとにスケールが大きく異なる場合、標準化を行うと当てはめを向上させることができます。
反復制限 — 学習反復の最大数を指定します。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
アンサンブル分類器
アンサンブル分類器では、複数の弱学習器の結果を融合して 1 つの高品質のアンサンブル モデルにします。精度はアルゴリズムの選択によって変化します。
ヒント
[学習器の数] の設定によってはモデルの柔軟性が向上します。
複数の学習器が必要になることが多いので、どのアンサンブル分類器も当てはめが低速になる傾向があります。
| 分類器のタイプ | 解釈可能性 | アンサンブル法 | モデルの柔軟性 |
|---|---|---|---|
| ブースティング木 | 困難 | [AdaBoost] と [決定木] の学習器 | 中から高 ― [学習器の数] または [最大分割数] の設定によっては増加。
ヒント 通常はブースティング木の方がバギング木より良好な結果が得られますが、パラメーターの調整とより多くの学習器が必要になる可能性があります。
|
| バギング木 | 困難 | ランダム フォレスト[バギング] と [決定木] の学習器 | 高 ― [学習器の数] の設定によっては増加。
ヒント はじめにこの分類器を試してください。
|
| 部分空間判別 | 困難 | [部分空間] と [判別] の学習器 | 中 ― [学習器の数] の設定によっては増加。 良好 (予測子が多い場合) |
| 部分空間 KNN | 困難 | [部分空間] と [最近傍] の学習器 | 中 ― [学習器の数] の設定によっては増加。 良好 (予測子が多い場合) |
| RUSBoost 木 | 困難 | [RUSBoost] と [決定木] の学習器 | 中 ― [学習器の数] または [最大分割数] の設定によっては増加。 データに歪みがある場合に良好 (1 クラスに多数の観測値がある場合) |
| GentleBoost または LogitBoost — [モデル タイプ] ギャラリーでは選択不可。 2 クラスのデータがある場合に手動で選択。 | 困難 | [GentleBoost] または [LogitBoost] と [決定木] の学習器。[ブースティング木] を選択して [GentleBoost] 法に変更。 | 中 ― [学習器の数] または [最大分割数] の設定によっては増加。 バイナリ分類の場合のみ |
バギング木では、Breiman の 'random forest' アルゴリズムを使用します。参考資料は、Breiman, L. の『Random Forests.Machine Learning 45, pp. 5-32, 2001』を参照してください。
ヒント
はじめにバギング木を試してください。通常はブースティング木の方が良好な結果を得られますが、多くのパラメーター値を調整する必要があるので時間がかかります。
[モデル] ギャラリーに表示される最適化不可能なアンサンブル分類器の各オプションで学習を試してください。すべてを試して、使用するデータに最適なモデルを生成するのはどの設定であるかを調べます。[モデル] ペインで最適なモデルを選択します。モデルを改善するには、特徴選択と PCA を試し、(必要な場合は) 一部の詳細オプションの変更を試してください。
ブースティング アンサンブル法の場合、深い木または多数の浅い木によって詳細を得ることができます。単独の木による分類器の場合と同じように、深い木は過適合の原因になる可能性があります。データの当てはめと木の複雑さのトレードオフを決定するために、アンサンブルにおいて最適な木の深さの選択を試す必要があります。[学習器の数] と [最大分割数] の設定を使用してください。
アンサンブル モデルのハイパーパラメーターのオプション
分類学習器では、アンサンブル分類器に関数 fitcensemble を使用します。次のオプションを設定できます。
[アンサンブル法] と [学習器の種類] を選択する基準については、アンサンブル分類器の表を参照してください。はじめに事前設定を試してください。
最大分割数
ブースティング アンサンブル法の場合、木学習器の深さを制御するには、最大分割数または分岐点を指定します。分岐が多くなると、過適合になる傾向があります。単純な木は、ロバストで解釈が容易になる可能性があります。アンサンブル内の木の深さとしてどのようなものが最適であるかを調べてください。
学習器の数
学習器の数を変更してモデルが向上するか確認してください。学習器を増やすと精度が向上しますが、当てはめに時間がかかる可能性があります。数十個の学習器から開始し、性能を検査してください。高い予測力をもつアンサンブルにするには、数百の学習器が必要になる可能性があります。
学習率
縮小学習率を指定します。学習率を 1 未満に設定すると、アンサンブルでは学習反復数を増加させる必要がありますが、多くの場合に精度が向上します。一般的な選択肢は 0.1 です。
部分空間の次元
部分空間アンサンブル用に、各学習器でサンプリングする予測子の数を指定します。各学習器について予測子のランダムなサブセットが選択されます。異なる学習器で選択されるサブセット間に関係性はありません。
サンプリングする予測子の数
木学習器の各分割についてランダムに選択する予測子の数を指定します。
このオプションを
[すべて選択]に設定した場合、使用可能なすべての予測子が使用されます。このオプションを
[範囲を設定]に設定した場合、ボタンをクリックするかボックスに正の整数値を入力して値を指定できます。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。
ニューラル ネットワーク分類器
一般にニューラル ネットワーク モデルは予測精度が高く、マルチクラス分類に使用できますが、解釈は容易ではありません。
ニューラル ネットワーク内の全結合層のサイズと数によっては、モデルの柔軟性が向上します。
ヒント
[モデル] ギャラリーの [すべてのニューラル ネットワーク] をクリックして事前設定済みのニューラル ネットワークの各オプションを試し、使用しているデータに最適なモデルが生成されるのはどの設定であるかを調べます。最適なモデルを [モデル] ペインで選択し、特徴選択の使用と一部の詳細オプションの変更によりモデルの改善を試します。
| 分類器のタイプ | 解釈可能性 | モデルの柔軟性 |
|---|---|---|
| ナロー ニューラル ネットワーク | 困難 | 中 — [最初の層のサイズ] の設定に応じて向上 |
| ミディアム ニューラル ネットワーク | 困難 | 中 — [最初の層のサイズ] の設定に応じて向上 |
| ワイド ニューラル ネットワーク | 困難 | 中 — [最初の層のサイズ] の設定に応じて向上 |
| 2 層ニューラル ネットワーク | 困難 | 中 — [最初の層のサイズ] および [2 番目の層のサイズ] の設定に応じて向上 |
| 3 層ニューラル ネットワーク | 困難 | 中 — [最初の層のサイズ]、[2 番目の層のサイズ]、および [3 番目の層のサイズ] の設定に応じて向上 |
各モデルは分類用の全結合のフィードフォワード ニューラル ネットワークです。ニューラル ネットワークの最初の全結合層にはネットワーク入力 (予測子データ) からの結合があり、後続の各層には前の層からの結合があります。各全結合層では、入力に重み行列が乗算されてからバイアス ベクトルが加算されます。各全結合層の後には活性化関数が続きます。最終全結合層とそれに続くソフトマックス活性化関数によってネットワークの出力、つまり分類スコア (事後確率) および予測ラベルが生成されます。詳細については、ニューラル ネットワークの構造を参照してください。
ニューラル ネットワーク モデルのハイパーパラメーターのオプション
分類学習器では、ニューラル ネットワーク分類器に関数 fitcnet を使用します。次のオプションを設定できます。
全結合層の数 — 分類用の最終全結合層を除く、ニューラル ネットワーク内の全結合層の数を指定します。最大 3 つの全結合層を選択できます。
最初の層のサイズ、2 番目の層のサイズ、3 番目の層のサイズ — 最終全結合層を除く、各全結合層のサイズを指定します。複数の全結合層をもつニューラル ネットワークを作成するように選択した場合は、サイズを小さくした層を指定することを検討してください。
活性化 — 最終全結合層を除く、すべての全結合層の活性化関数を指定します。最終全結合層の活性化関数は常にソフトマックスです。
ReLU、Tanh、None、Sigmoidのいずれかの活性化関数を選択します。反復制限 — 学習反復の最大数を指定します。
正則化強度 (Lambda) — リッジ (L2) 正則化ペナルティ項を指定します。
データの標準化 — 数値予測子を標準化するかどうかを指定します。予測子ごとにスケールが大きく異なる場合、標準化を行うと当てはめを向上させることができます。データを標準化することを強く推奨します。
あるいは、ハイパーパラメーターの最適化を使用して、いくつかのモデル オプションを自動的に選択することもできます。分類学習器アプリのハイパーパラメーターの最適化 を参照してください。