このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitckernel
ランダムな特徴量拡張を使用したバイナリ ガウス カーネル分類器の当てはめ
構文
説明
fitckernel は、非線形分類用のバイナリ ガウス カーネル分類モデルの学習または交差検証を行います。fitckernel は、大規模な学習セットが含まれているビッグ データ事例に対する方が実用的ですが、メモリに収まる小規模なデータ セットにも適用できます。
fitckernel は、低次元空間のデータを高次元空間にマッピングしてから、正則化された目的関数を最小化することによって高次元空間で線形モデルを当てはめます。高次元空間で線形モデルを取得することは、低次元空間におけるモデルへのガウス カーネルの適用と等価です。使用可能な線形分類モデルには、正則化されたサポート ベクター マシン (SVM) とロジスティック回帰モデルがあります。
インメモリ データのバイナリ分類用の非線形 SVM モデルに学習をさせる方法については、fitcsvm を参照してください。
Mdl = fitckernel(Tbl,ResponseVarName)Tbl に含まれる予測子変数と Tbl.ResponseVarName 内のクラス ラベルを使用して学習させたカーネル分類モデル Mdl を返します。
Mdl = fitckernel(___,Name,Value)
[ は、Mdl,FitInfo,HyperparameterOptimizationResults] = fitckernel(___)OptimizeHyperparameters が指定されている場合に、ハイパーパラメーターの最適化の結果も返します。
[ は、名前と値の引数 Mdl,FitInfo,AggregateOptimizationResults] = fitckernel(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
SVM を使用して、バイナリ カーネル分類モデルに学習をさせます。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphere
[n,p] = size(X)n = 351
p = 34
resp = unique(Y)
resp = 2×1 cell
{'b'}
{'g'}
レーダー反射が不良 ('b') と良好 ('g') のどちらであるかを識別するバイナリ カーネル分類モデルに学習をさせます。当てはめの要約を抽出して、最適化アルゴリズムによりモデルがどの程度適切にデータに当てはめられたかを判断します。
rng('default') % For reproducibility [Mdl,FitInfo] = fitckernel(X,Y)
Mdl =
ClassificationKernel
ResponseName: 'Y'
ClassNames: {'b' 'g'}
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 1
Lambda: 0.0028
BoxConstraint: 1
Properties, Methods
FitInfo = struct with fields:
Solver: 'LBFGS-fast'
LossFunction: 'hinge'
Lambda: 0.0028
BetaTolerance: 1.0000e-04
GradientTolerance: 1.0000e-06
ObjectiveValue: 0.2604
GradientMagnitude: 0.0028
RelativeChangeInBeta: 8.2512e-05
FitTime: 0.1501
History: []
Mdl は ClassificationKernel モデルです。標本内分類誤差を調べるには、Mdl と学習データまたは新しいデータを関数 loss に渡すことができます。または、Mdl と新しい予測子データを関数 predict に渡して、新しい観測値のクラス ラベルを予測することができます。また、Mdl と学習データを関数 resume に渡して学習を続行することもできます。
FitInfo は、最適化情報が格納されている構造体配列です。最適化終了時の結果が満足できるものであるかどうかを判断するには、FitInfo を使用します。
精度を向上させるため、名前と値のペアの引数を使用して、最適化反復の最大回数 ('IterationLimit') を増やしたり、許容誤差の値 ('BetaTolerance' および 'GradientTolerance') を小さくすることができます。このようにすると、FitInfo の ObjectiveValue や RelativeChangeInBeta などの尺度が向上します。名前と値のペアの引数 'OptimizeHyperparameters' を使用してモデル パラメーターを最適化することもできます。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphere rng('default') % For reproducibility
バイナリ カーネル分類モデルを交差検証します。既定では、10 分割交差検証が使用されます。
CVMdl = fitckernel(X,Y,'CrossVal','on')
CVMdl =
ClassificationPartitionedKernel
CrossValidatedModel: 'Kernel'
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Properties, Methods
numel(CVMdl.Trained)
ans = 10
CVMdl は ClassificationPartitionedKernel モデルです。fitckernel は 10 分割交差検証を実施するので、学習分割 (分割内) 観測値に対して学習をさせる 10 個の ClassificationKernel モデルが CVMdl に格納されます。
交差検証分類誤差を推定します。
kfoldLoss(CVMdl)
ans = 0.0940
分類誤差率は約 9% です。
名前と値の引数 OptimizeHyperparameters を使用して、自動的にハイパーパラメーターを最適化します。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphere自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。名前と値の引数 KernelScale、Lambda および Standardize の最適な値を fitckernel で求めるため、OptimizeHyperparameters として 'auto' を指定します。再現性を得るために、乱数シードを設定し、'expected-improvement-plus' の獲得関数を使用します。
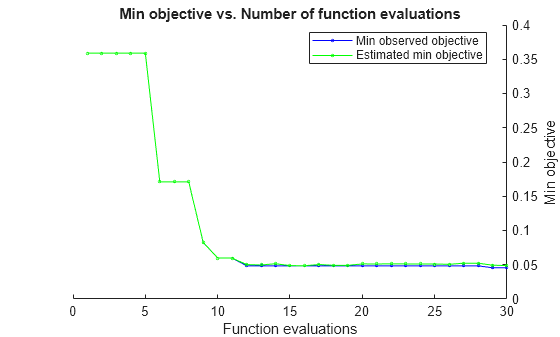
rng('default') [Mdl,FitInfo,HyperparameterOptimizationResults] = fitckernel(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName','expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | KernelScale | Lambda | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.35897 | 0.6358 | 0.35897 | 0.35897 | 3.8653 | 2.7394 | true |
| 2 | Accept | 0.35897 | 0.16825 | 0.35897 | 0.35897 | 429.99 | 0.0006775 | false |
| 3 | Accept | 0.35897 | 0.49772 | 0.35897 | 0.35897 | 0.11801 | 0.025493 | false |
| 4 | Accept | 0.41311 | 0.45936 | 0.35897 | 0.35898 | 0.0010694 | 9.1346e-06 | true |
| 5 | Accept | 0.4245 | 0.45979 | 0.35897 | 0.35898 | 0.0093918 | 2.8526e-06 | false |
| 6 | Best | 0.17094 | 0.3344 | 0.17094 | 0.17102 | 15.285 | 0.0038931 | false |
| 7 | Accept | 0.18234 | 0.33133 | 0.17094 | 0.17099 | 9.9078 | 0.0090818 | false |
| 8 | Accept | 0.35897 | 0.24151 | 0.17094 | 0.17097 | 26.961 | 0.46727 | false |
| 9 | Best | 0.082621 | 0.42815 | 0.082621 | 0.082677 | 7.7184 | 0.0025676 | false |
| 10 | Best | 0.059829 | 0.62298 | 0.059829 | 0.059839 | 5.6125 | 0.0013416 | false |
| 11 | Accept | 0.062678 | 0.63917 | 0.059829 | 0.059793 | 7.3294 | 0.00062394 | false |
| 12 | Best | 0.048433 | 0.91797 | 0.048433 | 0.050198 | 3.7772 | 0.00032964 | false |
| 13 | Accept | 0.051282 | 0.81066 | 0.048433 | 0.049662 | 3.4417 | 0.00077524 | false |
| 14 | Accept | 0.054131 | 0.83012 | 0.048433 | 0.051494 | 4.3694 | 0.00055199 | false |
| 15 | Accept | 0.051282 | 1.0758 | 0.048433 | 0.04872 | 1.7463 | 0.00012886 | false |
| 16 | Accept | 0.048433 | 0.77526 | 0.048433 | 0.048475 | 3.9086 | 3.1147e-05 | false |
| 17 | Accept | 0.054131 | 0.92836 | 0.048433 | 0.050325 | 3.1489 | 9.1315e-05 | false |
| 18 | Accept | 0.051282 | 0.67472 | 0.048433 | 0.049131 | 2.3414 | 4.8238e-06 | false |
| 19 | Accept | 0.062678 | 1.011 | 0.048433 | 0.049062 | 7.2203 | 3.2694e-06 | false |
| 20 | Accept | 0.054131 | 0.65747 | 0.048433 | 0.051225 | 3.5381 | 1.0341e-05 | false |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | KernelScale | Lambda | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.068376 | 0.6221 | 0.048433 | 0.05111 | 1.4267 | 1.7614e-05 | false |
| 22 | Accept | 0.054131 | 0.83028 | 0.048433 | 0.05127 | 3.2173 | 2.9573e-06 | false |
| 23 | Accept | 0.05698 | 0.90311 | 0.048433 | 0.051187 | 2.4241 | 0.0003272 | false |
| 24 | Accept | 0.059829 | 1.2187 | 0.048433 | 0.051097 | 2.5948 | 4.5059e-05 | false |
| 25 | Accept | 0.059829 | 0.83132 | 0.048433 | 0.051018 | 7.2989 | 2.6908e-05 | false |
| 26 | Accept | 0.068376 | 1.1797 | 0.048433 | 0.048938 | 3.9585 | 6.9173e-06 | false |
| 27 | Accept | 0.05698 | 0.97131 | 0.048433 | 0.051222 | 4.2751 | 0.0002231 | false |
| 28 | Accept | 0.062678 | 0.48422 | 0.048433 | 0.051232 | 1.4533 | 2.8533e-06 | false |
| 29 | Accept | 0.051282 | 0.82441 | 0.048433 | 0.051122 | 3.8449 | 0.00059747 | false |
| 30 | Accept | 0.21083 | 1.0222 | 0.048433 | 0.0512 | 45.588 | 3.056e-06 | false |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 28.4592 seconds
Total objective function evaluation time: 21.3871
Best observed feasible point:
KernelScale Lambda Standardize
___________ __________ ___________
3.7772 0.00032964 false
Observed objective function value = 0.048433
Estimated objective function value = 0.05162
Function evaluation time = 0.91797
Best estimated feasible point (according to models):
KernelScale Lambda Standardize
___________ __________ ___________
3.8449 0.00059747 false
Estimated objective function value = 0.0512
Estimated function evaluation time = 0.81669
Mdl =
ClassificationKernel
ResponseName: 'Y'
ClassNames: {'b' 'g'}
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 3.8449
Lambda: 5.9747e-04
BoxConstraint: 4.7684
Properties, Methods
FitInfo = struct with fields:
Solver: 'LBFGS-fast'
LossFunction: 'hinge'
Lambda: 5.9747e-04
BetaTolerance: 1.0000e-04
GradientTolerance: 1.0000e-06
ObjectiveValue: 0.1006
GradientMagnitude: 0.0114
RelativeChangeInBeta: 9.3027e-05
FitTime: 0.1680
History: []
HyperparameterOptimizationResults =
BayesianOptimization with properties:
ObjectiveFcn: @createObjFcn/inMemoryObjFcn
VariableDescriptions: [5×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.0484
XAtMinObjective: [1×3 table]
MinEstimatedObjective: 0.0512
XAtMinEstimatedObjective: [1×3 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 28.4592
NextPoint: [1×3 table]
XTrace: [30×3 table]
ObjectiveTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
ビッグ データの場合、最適化手順に時間がかかる可能性があります。最適化手順を実行するにはデータ セットが大きすぎる場合、データの一部だけを使用してパラメーターの最適化を試すことができます。関数 datasample を使用し、'Replace','false' を指定して、データを非復元抽出します。
入力引数
名前と値の引数
出力引数
詳細
ヒント
モデルに学習させる前に予測子を標準化すると役立つことがあります。
関数
normalizeを使用して、学習データを標準化し、テスト データを学習データと同じスケールになるようにスケーリングできます。あるいは、名前と値の引数
Standardizeを使用して学習前に数値予測子を標準化します。返されるモデルのMuプロパティとSigmaプロパティに、予測子の平均と標準偏差がそれぞれ含まれます。 (R2023b 以降)
モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
fitckernelは、メモリ制限 Broyden-Fletcher-Goldfarb-Shanno (LBFGS) ソルバーとリッジ (L2) 正則化を使用して、正則化された目的関数を最小化します。学習に使用した LBFGS ソルバーのタイプを調べるには、コマンド ウィンドウでFitInfo.Solverと入力します。'LBFGS-fast'— LBFGS ソルバー。'LBFGS-blockwise'— ブロック単位方式を使用する LBFGS ソルバー。変換後の予測子データを保持するためにfitckernelで必要となるメモリがBlockSizeの値より多い場合、この関数はブロック単位方式を使用します。'LBFGS-tall'— ブロック単位方式の tall 配列用 LBFGS ソルバー。
fitckernelがブロック単位方式を使用する場合、各反復で損失と勾配の計算をデータのさまざまな部分に分散させることにより LBFGS が実装されます。また、fitckernelは、データの一部に対してローカルにモデルを当てはめ、平均化で係数を結合することにより、線形係数およびバイアス項の初期推定値を改善します。'Verbose',1が指定された場合、fitckernelは各データ通過についての診断情報を表示し、情報をFitInfoのHistoryフィールドに格納します。fitckernelがブロック単位方式を使用しない場合、初期推定値はゼロになります。'Verbose',1が指定された場合、fitckernelは各反復についての診断情報を表示し、情報をFitInfoのHistoryフィールドに格納します。名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列 (C) が変更なしで格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。モデルの学習用に、事前確率と観測値の重みが更新されて、コスト行列で指定されているペナルティが組み込まれます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。