このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitcnet
ニューラル ネットワーク分類モデルの学習
構文
説明
fitcnet は、全結合のフィードフォワード ニューラル ネットワークなど、分類用のニューラル ネットワークの学習に使用します。全結合のフィードフォワード ネットワークでは、最初の全結合層にネットワーク入力 (予測子データ) からの結合があり、後続の各層に前の層からの結合があります。各全結合層では、入力に重み行列が乗算されてからバイアス ベクトルが加算されます。各全結合層の後には活性化関数が続きます。最終全結合層とそれに続くソフトマックス活性化関数によってネットワークの出力、つまり分類スコア (事後確率) および予測ラベルが生成されます。詳細については、ニューラル ネットワークの構造を参照してください。
Mdl = fitcnet(Tbl,ResponseVarName)Tbl 内の予測子と table 変数 ResponseVarName 内のクラス ラベルを使用して学習させたニューラル ネットワーク分類モデル Mdl を返します。
Mdl = fitcnet(___,Name=Value)LayerSizes や Activations を指定して、全結合層の出力の数や活性化関数を調整できます。
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitcnet(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
ニューラル ネットワーク分類器に学習させ、テスト セットで分類器の性能を評価します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。データ セットの最初の数行をプレビューします。
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating) ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);応答変数 Rating を categorical 変数に変換します。
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
データを学習セットとテスト セットに分割します。観測値の約 80% をニューラル ネットワーク モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。cvpartition を使用してデータを分割します。
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
学習データ creditTrain を関数 fitcnet に渡して、ニューラル ネットワーク分類器に学習させます。
Mdl = fitcnet(creditTrain,"Rating")Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl は学習させた ClassificationNeuralNetwork 分類器です。ドット表記を使用して Mdl のプロパティにアクセスできます。たとえば、Mdl.TrainingHistory と指定すると、ニューラル ネットワーク モデルの学習履歴についての詳細情報を取得できます。
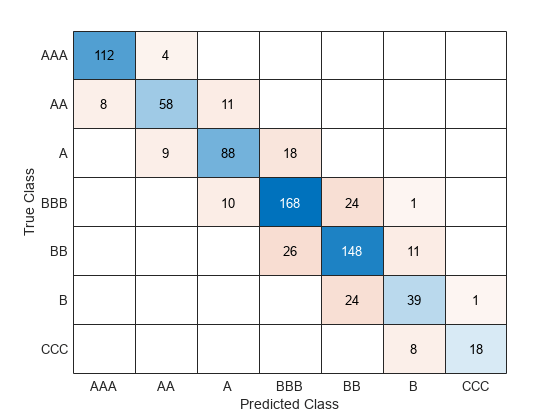
テスト セットの分類誤差を計算して、テスト セットで分類器の性能を評価します。混同行列を使用して結果を可視化します。
testAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
testAccuracy = 0.7977
confusionchart(creditTest.Rating,predict(Mdl,creditTest))
ニューラル ネットワークの全結合層を構成します。
レーダー信号のデータを含む ionosphere データ セットを読み込みます。X に予測子データが格納されており、応答変数の Y にレーダー信号が良好 ("g") か不良 ("b") かを表す値が格納されます。
load ionosphere層化ホールドアウト分割を使用して、データを学習データ (XTrain および YTrain) とテスト データ (XTest および YTest) に分割します。観測値の約 30% をテスト用に予約し、残りの観測値を学習に使用します。
rng("default") % For reproducibility of the partition cvp = cvpartition(Y,"Holdout",0.3); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
ニューラル ネットワーク分類器に学習させます。最初の全結合層の出力数を 35、2 番目の全結合層の出力数を 20 に指定します。既定では、どちらの層でも正規化線形ユニット (ReLU) 活性化関数が使用されます。全結合層の活性化関数は、名前と値の引数 Activations を使用して変更できます。
Mdl = fitcnet(XTrain,YTrain, ... "LayerSizes",[35 20])
Mdl =
ClassificationNeuralNetwork
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 246
LayerSizes: [35 20]
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [47×7 table]
Properties, Methods
Mdl の LayerWeights プロパティと LayerBiases プロパティを使用して、学習させた分類器の全結合層の重みとバイアスにアクセスします。各プロパティの最初の 2 つの要素が最初の 2 つの全結合層の値に対応し、3 番目の要素が分類用のソフトマックス活性化関数をもつ最終全結合層の値に対応します。たとえば、2 番目の全結合層の重みとバイアスを表示します。
Mdl.LayerWeights{2}ans = 20×35
0.0481 0.2501 -0.1535 -0.0934 0.0760 -0.0579 -0.2465 1.0411 0.3712 -1.2007 1.1162 0.4296 0.4045 0.5005 0.8839 0.4624 -0.3154 0.3454 -0.0487 0.2648 0.0732 0.5773 0.4286 0.0881 0.9468 0.2981 0.5534 1.0518 -0.0224 0.6894 0.5527 0.7045 -0.6124 0.2145 -0.0790
-0.9489 -1.8343 0.5510 -0.5751 -0.8726 0.8815 0.0203 -1.6379 2.0315 1.7599 -1.4153 -1.4335 -1.1638 -0.1715 1.1439 -0.7661 1.1230 -1.1982 -0.5409 -0.5821 -0.0627 -0.7038 -0.0817 -1.5773 -1.4671 0.2053 -0.7931 -1.6201 -0.1737 -0.7762 -0.3063 -0.8771 1.5134 -0.4611 -0.0649
-0.1910 0.0246 -0.3511 0.0097 0.3160 -0.0693 0.2270 -0.0783 -0.1626 -0.3478 0.2765 0.4179 0.0727 -0.0314 -0.1798 -0.0583 0.1375 -0.1876 0.2518 0.2137 0.1497 0.0395 0.2859 -0.0905 0.4325 -0.2012 0.0388 -0.1441 -0.1431 -0.0249 -0.2200 0.0860 -0.2076 0.0132 0.1737
-0.0415 -0.0059 -0.0753 -0.1477 -0.1621 -0.1762 0.2164 0.1710 -0.0610 -0.1402 0.1452 0.2890 0.2872 -0.2616 -0.4204 -0.2831 -0.1901 0.0036 0.0781 -0.0826 0.1588 -0.2782 0.2510 -0.1069 -0.2692 0.2306 0.2521 0.0306 0.2524 -0.4218 0.2478 0.2343 -0.1031 0.1037 0.1598
1.1848 1.6142 -0.1352 0.5774 0.5491 0.0103 0.0209 0.7219 -0.8643 -0.5578 1.3595 1.5385 1.0015 0.7416 -0.4342 0.2279 0.5667 1.1589 0.7100 0.1823 0.4171 0.7051 0.0794 1.3267 1.2659 0.3197 0.3947 0.3436 -0.1415 0.6607 1.0071 0.7726 -0.2840 0.8801 0.0848
0.2486 -0.2920 -0.0004 0.2806 0.2987 -0.2709 0.1473 -0.2580 -0.0499 -0.0755 0.2000 0.1535 -0.0285 -0.0520 -0.2523 -0.2505 -0.0437 -0.2323 0.2023 0.2061 -0.1365 0.0744 0.0344 -0.2891 0.2341 -0.1556 0.1459 0.2533 -0.0583 0.0243 -0.2949 -0.1530 0.1546 -0.0340 -0.1562
-0.0516 0.0640 0.1824 -0.0675 -0.2065 -0.0052 -0.1682 -0.1520 0.0060 0.0450 0.0813 -0.0234 0.0657 0.3219 -0.1871 0.0658 -0.2103 0.0060 -0.2831 -0.1811 -0.0988 0.2378 -0.0761 0.1714 -0.1596 -0.0011 0.0609 0.4003 0.3687 -0.2879 0.0910 0.0604 -0.2222 -0.2735 -0.1155
-0.6192 -0.7804 -0.0506 -0.4205 -0.2584 -0.2020 -0.0008 0.0534 1.0185 -0.0307 -0.0539 -0.2020 0.0368 -0.1847 0.0886 -0.4086 -0.4648 -0.3785 0.1542 -0.5176 -0.3207 0.1893 -0.0313 -0.5297 -0.1261 -0.2749 -0.6152 -0.5914 -0.3089 0.2432 -0.3955 -0.1711 0.1710 -0.4477 0.0718
0.5049 -0.1362 -0.2218 0.1637 -0.1282 -0.1008 0.1445 0.4527 -0.4887 0.0503 0.1453 0.1316 -0.3311 -0.1081 -0.7699 0.4062 -0.1105 -0.0855 0.0630 -0.1469 -0.2533 0.3976 0.0418 0.5294 0.3982 0.1027 -0.0973 -0.1282 0.2491 0.0425 0.0533 0.1578 -0.8403 -0.0535 -0.0048
1.1109 -0.0466 0.4044 0.6366 0.1863 0.5660 0.2839 0.8793 -0.5497 0.0057 0.3468 0.0980 0.3364 0.4669 0.1466 0.7883 -0.1743 0.4444 0.4535 0.1521 0.7476 0.2246 0.4473 0.2829 0.8881 0.4666 0.6334 0.3105 0.9571 0.2808 0.6483 0.1180 -0.4558 1.2486 0.2453
-1.8572 -2.6653 -0.2140 -0.3477 -0.8055 0.9079 0.6366 -1.3961 1.7287 0.7673 -1.8550 -1.7492 -1.3679 -0.3315 2.7078 -0.7556 0.0769 -1.5157 -0.4442 -0.6340 0.2048 -1.0457 -0.1914 -1.6244 -1.7866 -0.6572 -1.8200 -1.3674 -0.6874 -1.1299 -0.0000 -1.9709 0.7340 -0.4415 -0.3320
0.2370 0.8540 -0.7814 -0.2181 -0.0569 0.0027 -0.2945 0.1143 -0.6404 -0.4251 0.5823 0.5555 0.4856 0.1239 0.3043 0.1653 -0.2534 0.0117 0.3500 -0.0883 0.4188 0.1499 0.2924 1.0637 0.7403 0.0144 -0.5028 0.9141 -0.1405 -0.3842 0.6864 -0.0071 -0.1437 0.2459 -0.1786
-0.4045 -1.0484 -0.1285 -0.4945 -0.3934 -0.0459 -0.2790 -0.0375 1.5520 -0.5361 0.3359 -0.5839 -0.4385 -0.6225 -1.1123 -0.5139 0.9128 -0.4074 -0.3080 -1.1164 -0.5790 -0.0578 -0.7154 -0.5121 -0.3480 0.3290 -0.2253 0.1340 -0.4615 0.1242 -0.8776 0.3386 -0.0865 -0.2834 0.0347
0.0617 -0.1042 -0.1774 -0.0899 -0.0925 -0.3826 -0.0153 0.1875 0.1134 -0.0190 -0.1245 0.0485 -0.1353 0.0801 -0.6564 -0.2706 -0.3851 -0.0657 -0.0888 -0.3534 -0.0382 -0.1895 -0.1363 -0.4116 -0.2031 -0.1712 -0.1507 -0.1233 -0.3996 -0.0849 -0.2433 -0.1504 -0.1387 -0.1659 0.0534
0.2469 0.8184 -0.7969 0.3706 0.0860 0.6381 -0.3027 0.5547 0.0410 -0.5412 1.4578 1.1429 0.6856 0.3181 0.8661 0.4728 -0.0410 0.8727 0.3093 0.6220 0.2403 0.1572 0.4424 0.4320 0.3807 -0.0664 0.5451 1.1958 -0.0054 -0.0761 0.6085 0.5600 0.2312 0.8952 0.3766
⋮
Mdl.LayerBiases{2}ans = 20×1
0.6147
0.1891
-0.2767
-0.2977
1.3655
0.0347
0.1509
-0.4839
-0.3960
0.9248
-0.5636
0.1190
-0.5285
-0.3493
1.7387
⋮
最終全結合層の出力は 2 つで、応答変数内のクラスごとに 1 つずつとなります。層の出力の数は、層の重みと層のバイアスの最初の次元に対応します。
size(Mdl.LayerWeights{end})ans = 1×2
2 20
size(Mdl.LayerBiases{end})ans = 1×2
2 1
学習させた分類器の性能を推定するには、Mdl のテスト セットの分類誤差を計算します。
testError = loss(Mdl,XTest,YTest, ... "LossFun","classiferror")
testError = 0.0774
accuracy = 1 - testError
accuracy = 0.9226
Mdl でテスト セットの観測値の約 92% が正確に分類されています。
R2025a 以降
Deep Learning Toolbox™ を使用してカスタムのニューラル ネットワーク アーキテクチャを指定します。
レーダー信号のデータを含む ionosphere データ セットを読み込みます。X に予測子データが格納されており、応答変数の Y にレーダー信号が良好 ("g") か不良 ("b") かを表す値が格納されます。
load ionosphere層化ホールドアウト分割を使用して、データを学習データ (XTrain および YTrain) とテスト データ (XTest および YTest) に分割します。観測値の約 30% をテスト用に予約し、残りの観測値を学習に使用します。
rng("default") % For reproducibility of the partition cvp = cvpartition(Y,Holdout=0.3); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
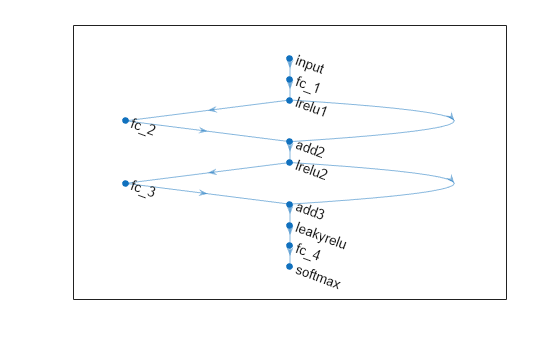
次の特性をもつニューラル ネットワーク アーキテクチャを定義します。
予測子の数と一致する入力サイズをもつ特徴入力層。
3 つの全結合層とそれに続く leaky ReLU 層が直列に接続され、全結合層の出力サイズは 16、2 番目と 3 番目の全結合層の後には加算層がある。
2 番目と 3 番目の全結合層についてのスキップ接続。加算層を使用。
クラスの数と一致する出力サイズをもつ最終全結合層、その後にソフトマックス層。
inputSize = size(XTrain,2);
outputSize = numel(unique(YTrain));
net = dlnetwork;
layers = [
featureInputLayer(inputSize)
fullyConnectedLayer(30)
leakyReluLayer(Name="lrelu1")
fullyConnectedLayer(30)
additionLayer(2,Name="add2")
leakyReluLayer(Name="lrelu2")
fullyConnectedLayer(30)
additionLayer(2,Name="add3")
leakyReluLayer
fullyConnectedLayer(outputSize)
softmaxLayer];
net = addLayers(net,layers);
net = connectLayers(net,"lrelu1","add2/in2");
net = connectLayers(net,"lrelu2","add3/in2");ニューラル ネットワーク アーキテクチャをプロットで可視化します。
figure plot(net)
ニューラル ネットワーク分類器に学習させます。
Mdl = fitcnet(XTrain,YTrain,Network=net,Standardize=true)
Mdl =
ClassificationNeuralNetwork
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 246
LayerSizes: []
Activations: ''
OutputLayerActivation: ''
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [30×5 table]
View network information using dlnetwork.
Properties, Methods
学習させた分類器の性能を推定するには、テスト セットの分類誤差を計算します。
testError = loss(Mdl,XTest,YTest, ... LossFun="classiferror")
testError = 0.0774
学習プロセスの各反復でニューラル ネットワークの検証損失を計算します。検証損失が妥当な値まで小さくなったら、その時点で学習プロセスを早期に停止します。
patients データ セットを読み込みます。データ セットから table を作成します。各行が 1 人の患者に対応し、各列が診断の変数に対応します。変数 Smoker を応答変数として使用し、残りの変数を予測子として使用します。
load patients
tbl = table(Diastolic,Systolic,Gender,Height,Weight,Age,Smoker);層化ホールドアウト分割を使用して、データを学習セット tblTrain と検証セット tblValidation に分割します。観測値の約 30% が検証データ用に予約され、残りの観測値が学習データ セットに使用されます。
rng("default") % For reproducibility of the partition c = cvpartition(tbl.Smoker,"Holdout",0.30); trainingIndices = training(c); validationIndices = test(c); tblTrain = tbl(trainingIndices,:); tblValidation = tbl(validationIndices,:);
学習セットを使用してニューラル ネットワーク分類器に学習させます。tblTrain の列 Smoker を応答変数として指定します。検証セットを使用して各反復でモデルを評価します。名前と値の引数 Verbose を使用して、各反復で学習データを表示するように指定します。既定では、検証クロスエントロピー損失が 6 回連続でそれまでに計算された検証クロスエントロピー損失の最小値以上になると、その時点で学習プロセスが早期に終了します。検証損失が最小値以上になる許容回数を変更するには、名前と値の引数 ValidationPatience を指定します。
Mdl = fitcnet(tblTrain,"Smoker", ... "ValidationData",tblValidation, ... "Verbose",1);
|==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 1| 2.602935| 26.866935| 0.262009| 0.030615| 2.793048| 0| | 2| 1.470816| 42.594723| 0.058323| 0.005396| 1.247046| 0| | 3| 1.299292| 25.854432| 0.034910| 0.001701| 1.507857| 1| | 4| 0.710465| 11.629107| 0.013616| 0.003241| 0.889157| 0| | 5| 0.647783| 2.561740| 0.005753| 0.007162| 0.766728| 0| | 6| 0.645541| 0.681579| 0.001000| 0.000800| 0.776072| 1| | 7| 0.639611| 1.544692| 0.007013| 0.001238| 0.776320| 2| | 8| 0.604189| 5.045676| 0.064190| 0.000329| 0.744919| 0| | 9| 0.565364| 5.851552| 0.068845| 0.000341| 0.694226| 0| | 10| 0.391994| 8.377717| 0.560480| 0.000351| 0.425466| 0| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 11| 0.383843| 0.630246| 0.110270| 0.000827| 0.428487| 1| | 12| 0.369289| 2.404750| 0.084395| 0.000408| 0.405728| 0| | 13| 0.357839| 6.220679| 0.199197| 0.000383| 0.378480| 0| | 14| 0.344974| 2.752717| 0.029013| 0.000389| 0.367279| 0| | 15| 0.333747| 0.711398| 0.074513| 0.001102| 0.348499| 0| | 16| 0.327763| 0.804818| 0.122178| 0.000388| 0.330237| 0| | 17| 0.327702| 0.778169| 0.009810| 0.000315| 0.329095| 0| | 18| 0.327277| 0.020615| 0.004377| 0.000322| 0.329141| 1| | 19| 0.327273| 0.010018| 0.003313| 0.000373| 0.328773| 0| | 20| 0.327268| 0.019497| 0.000805| 0.000536| 0.328831| 1| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 21| 0.327228| 0.113983| 0.005397| 0.001457| 0.329085| 2| | 22| 0.327138| 0.240166| 0.012159| 0.000348| 0.329406| 3| | 23| 0.326865| 0.428912| 0.036841| 0.000323| 0.329952| 4| | 24| 0.325797| 0.255227| 0.139585| 0.000330| 0.331246| 5| | 25| 0.325181| 0.758050| 0.135868| 0.000858| 0.332035| 6| |==========================================================================================|
各反復における学習クロスエントロピー損失と検証クロスエントロピー損失を比較するプロットを作成します。既定では、fitcnet はオブジェクト Mdl の TrainingHistory プロパティに損失の情報を格納します。この情報にドット表記を使用してアクセスできます。
iteration = Mdl.TrainingHistory.Iteration; trainLosses = Mdl.TrainingHistory.TrainingLoss; valLosses = Mdl.TrainingHistory.ValidationLoss; plot(iteration,trainLosses,iteration,valLosses) legend(["Training","Validation"]) xlabel("Iteration") ylabel("Cross-Entropy Loss")

検証損失が最小になる対応する反復を確認します。最終的に返されるモデル Mdl は、この反復で学習させたモデルになります。
[~,minIdx] = min(valLosses); iteration(minIdx)
ans = 19
ニューラル ネットワーク モデルの交差検証損失をさまざまな正則化強度で評価し、モデルの性能が最も高くなる対応する正則化強度を選択します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。データ セットの最初の数行をプレビューします。
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating) ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);応答変数 Rating を categorical 変数に変換します。
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
層化 5 分割交差検証用に cvpartition オブジェクトを作成します。cvp を使用して、各分割におけるそれぞれの格付けの比率がほぼ同じになるようにデータを 5 つの分割に分割します。分割の再現性を得るため、乱数シードを既定値に設定します。
rng("default") cvp = cvpartition(creditrating.Rating,"KFold",5);
さまざまな正則化強度でニューラル ネットワーク分類器の交差検証分類誤差を計算します。1/n に基づく正則化強度を試します。n は観測値の数です。ニューラル ネットワーク モデルに学習させる前にデータを標準化するように指定します。
1/size(creditrating,1)
ans = 2.5432e-04
lambda = (0:0.5:5)*1e-4; cvloss = zeros(length(lambda),1); for i = 1:length(lambda) cvMdl = fitcnet(creditrating,"Rating","Lambda",lambda(i), ... "CVPartition",cvp,"Standardize",true); cvloss(i) = kfoldLoss(cvMdl,"LossFun","classiferror"); end
結果をプロットします。最小の交差検証分類誤差に対応する正則化強度を求めます。
plot(lambda,cvloss) xlabel("Regularization Strength") ylabel("Cross-Validation Loss")

[~,idx] = min(cvloss); bestLambda = lambda(idx)
bestLambda = 5.0000e-05
正則化強度 bestLambda を使用してニューラル ネットワーク分類器に学習させます。
Mdl = fitcnet(creditrating,"Rating","Lambda",bestLambda, ... "Standardize",true)
Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3932
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
OptimizeHyperparameters 引数を使用してニューラル ネットワーク分類器に学習させ、結果の分類器を改善します。この引数を使用すると、fitcnet はベイズ最適化を使用し、問題のある一部のハイパーパラメーターに対して交差検証損失を最小化します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。データ セットの最初の数行をプレビューします。
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating) ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);応答変数 Rating を categorical 変数に変換します。
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
データを学習セットとテスト セットに分割します。観測値の約 80% をニューラル ネットワーク モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。cvpartition を使用してデータを分割します。
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
学習データ creditTrain を関数 fitcnet に渡してニューラル ネットワーク分類器に学習させ、OptimizeHyperparameters 引数を含めます。再現性を得るために、HyperparameterOptimizationOptions 構造体 の AcquisitionFunctionName を "expected-improvement-plus" に設定します。より適切な解を得るために、最適化のステップ数を既定値の 30 ではなく 100 に設定します。fitcnet は、既定の設定ではベイズ最適化を実行します。グリッド探索またはランダム探索を使用するために、HyperparameterOptimizationOptions の Optimizer フィールドを設定します。
rng("default") % For reproducibility Mdl = fitcnet(creditTrain,"Rating","OptimizeHyperparameters","auto", ... "HyperparameterOptimizationOptions", ... struct("AcquisitionFunctionName","expected-improvement-plus", ... "MaxObjectiveEvaluations",100))
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 1 | Best | 0.55944 | 0.6624 | 0.55944 | 0.55944 | none | true | 0.05834 | 3 |
| 2 | Best | 0.21297 | 10.953 | 0.21297 | 0.22674 | relu | true | 5.0811e-08 | [ 1 25] |
| 3 | Accept | 0.74189 | 0.51791 | 0.21297 | 0.21333 | sigmoid | true | 0.57986 | 126 |
| 4 | Accept | 0.4501 | 0.65455 | 0.21297 | 0.21319 | tanh | false | 0.018683 | 10 |
| 5 | Accept | 0.45359 | 7.4426 | 0.21297 | 0.21318 | relu | true | 0.00037859 | [ 44 1 2] |
| 6 | Accept | 0.30896 | 72.623 | 0.21297 | 0.21303 | relu | true | 4.0364e-09 | [175 183] |
| 7 | Accept | 0.21424 | 7.0269 | 0.21297 | 0.21364 | relu | true | 4.1256e-08 | 1 |
| 8 | Accept | 0.74189 | 0.19974 | 0.21297 | 0.21254 | tanh | false | 0.37071 | [ 10 3 3] |
| 9 | Accept | 0.21774 | 10.829 | 0.21297 | 0.21352 | relu | true | 1.6265e-06 | [ 3 5] |
| 10 | Best | 0.21265 | 9.6793 | 0.21265 | 0.21274 | relu | true | 9.6739e-05 | [ 1 3 6] |
| 11 | Accept | 0.74189 | 0.15813 | 0.21265 | 0.21218 | relu | true | 1.4153 | 27 |
| 12 | Best | 0.20947 | 7.8527 | 0.20947 | 0.20948 | relu | true | 4.7245e-07 | [ 2 3 6] |
| 13 | Accept | 0.23268 | 9.5702 | 0.20947 | 0.20952 | tanh | false | 3.4777e-08 | 10 |
| 14 | Accept | 0.22441 | 13.989 | 0.20947 | 0.20952 | tanh | false | 1.4574e-05 | [ 11 2 9] |
| 15 | Accept | 0.26732 | 69.975 | 0.20947 | 0.20954 | tanh | false | 3.6034e-07 | [291 10] |
| 16 | Accept | 0.23427 | 7.0366 | 0.20947 | 0.20954 | relu | false | 3.2585e-09 | 1 |
| 17 | Accept | 0.21488 | 26.038 | 0.20947 | 0.20954 | relu | false | 8.2337e-06 | [ 1 2 93] |
| 18 | Accept | 0.26224 | 47.701 | 0.20947 | 0.20955 | relu | false | 2.4128e-07 | [274 1] |
| 19 | Accept | 0.74189 | 0.20321 | 0.20947 | 0.20955 | relu | false | 0.060533 | [ 8 3] |
| 20 | Accept | 0.43643 | 7.7327 | 0.20947 | 0.20949 | relu | false | 2.558e-07 | [ 1 17 2] |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 21 | Accept | 0.50858 | 4.0815 | 0.20947 | 0.20949 | relu | false | 0.017314 | [ 8 82 93] |
| 22 | Accept | 0.49714 | 8.0331 | 0.20947 | 0.20946 | tanh | false | 0.014033 | [225 17 9] |
| 23 | Accept | 0.28608 | 82.071 | 0.20947 | 0.20947 | relu | false | 1.4036e-07 | [263 14 275] |
| 24 | Accept | 0.26891 | 55.681 | 0.20947 | 0.19753 | relu | false | 2.9418e-05 | [135 11 192] |
| 25 | Accept | 0.25175 | 69.479 | 0.20947 | 0.20948 | relu | true | 3.0659e-06 | [ 5 150 186] |
| 26 | Accept | 0.27018 | 45.668 | 0.20947 | 0.20144 | relu | false | 3.1943e-09 | [261 4] |
| 27 | Accept | 0.22568 | 32.734 | 0.20947 | 0.20943 | relu | true | 1.1294e-06 | [ 9 1 147] |
| 28 | Accept | 0.21392 | 7.9387 | 0.20947 | 0.20941 | tanh | false | 8.9536e-07 | 1 |
| 29 | Accept | 0.21901 | 51.491 | 0.20947 | 0.20937 | tanh | false | 1.2889e-07 | [ 3 2 197] |
| 30 | Accept | 0.21519 | 12.24 | 0.20947 | 0.20934 | relu | false | 0.00035024 | [ 1 36 9] |
| 31 | Accept | 0.2775 | 3.8553 | 0.20947 | 0.20934 | tanh | false | 0.0002159 | [ 1 2] |
| 32 | Accept | 0.21615 | 11.204 | 0.20947 | 0.20932 | relu | false | 4.3753e-05 | [ 1 23 5] |
| 33 | Accept | 0.21647 | 56.854 | 0.20947 | 0.20931 | tanh | false | 3.4689e-09 | [ 1 268 4] |
| 34 | Accept | 0.27463 | 53.603 | 0.20947 | 0.20937 | relu | false | 2.2259e-06 | [286 34] |
| 35 | Accept | 0.3042 | 46.781 | 0.20947 | 0.20933 | relu | true | 1.1227e-07 | 281 |
| 36 | Accept | 0.42912 | 29.189 | 0.20947 | 0.20939 | relu | false | 0.00076968 | [284 2 8] |
| 37 | Accept | 0.21488 | 10.309 | 0.20947 | 0.20939 | tanh | true | 4.0099e-09 | [ 1 3 4] |
| 38 | Accept | 0.21774 | 7.3039 | 0.20947 | 0.20939 | tanh | true | 2.7818e-06 | 1 |
| 39 | Accept | 0.30896 | 99.307 | 0.20947 | 0.20939 | tanh | true | 1.7536e-07 | [292 9 158] |
| 40 | Accept | 0.52066 | 10.635 | 0.20947 | 0.20939 | tanh | true | 0.0096088 | [ 1 161 24] |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 41 | Accept | 0.21392 | 7.3746 | 0.20947 | 0.20939 | tanh | true | 3.5001e-08 | 1 |
| 42 | Accept | 0.21742 | 11.47 | 0.20947 | 0.2094 | sigmoid | false | 3.5109e-09 | [ 1 19] |
| 43 | Accept | 0.25652 | 71.051 | 0.20947 | 0.20939 | sigmoid | false | 1.7677e-07 | [297 2] |
| 44 | Accept | 0.2136 | 81.345 | 0.20947 | 0.20939 | sigmoid | false | 1.0104e-05 | [ 1 95 272] |
| 45 | Accept | 0.21488 | 7.9797 | 0.20947 | 0.20939 | sigmoid | false | 4.9812e-07 | 1 |
| 46 | Accept | 0.74189 | 0.19233 | 0.20947 | 0.20938 | sigmoid | false | 0.014036 | 1 |
| 47 | Accept | 0.2206 | 98.161 | 0.20947 | 0.20948 | sigmoid | false | 1.6413e-07 | [ 4 144 271] |
| 48 | Accept | 0.21551 | 56.403 | 0.20947 | 0.20938 | tanh | true | 5.3046e-08 | [ 1 263] |
| 49 | Accept | 0.21869 | 52.317 | 0.20947 | 0.20931 | relu | false | 0.00012348 | [ 1 20 297] |
| 50 | Accept | 0.24793 | 68.619 | 0.20947 | 0.20931 | sigmoid | false | 3.3564e-09 | [288 1 24] |
| 51 | Accept | 0.24412 | 49.246 | 0.20947 | 0.2093 | sigmoid | false | 4.5434e-06 | [ 50 20 166] |
| 52 | Accept | 0.21488 | 4.5457 | 0.20947 | 0.20931 | none | false | 7.8998e-09 | [ 1 5] |
| 53 | Accept | 0.22028 | 31.073 | 0.20947 | 0.20931 | none | false | 1.5483e-07 | [132 41 15] |
| 54 | Accept | 0.22028 | 37.148 | 0.20947 | 0.20931 | none | false | 5.909e-09 | [271 16] |
| 55 | Accept | 0.21615 | 3.7849 | 0.20947 | 0.20931 | none | false | 5.9842e-06 | 1 |
| 56 | Accept | 0.21456 | 4.6696 | 0.20947 | 0.20931 | none | false | 2.9016e-07 | 1 |
| 57 | Accept | 0.21615 | 39.25 | 0.20947 | 0.20932 | none | false | 0.0002184 | [246 194] |
| 58 | Accept | 0.2206 | 23.229 | 0.20947 | 0.20931 | none | false | 1.1092e-05 | 277 |
| 59 | Accept | 0.3007 | 0.58966 | 0.20947 | 0.2093 | none | false | 0.0048807 | [ 1 3] |
| 60 | Accept | 0.22155 | 1.3952 | 0.20947 | 0.20947 | none | false | 9.8985e-05 | 1 |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 61 | Accept | 0.21996 | 20.233 | 0.20947 | 0.20931 | none | true | 3.1814e-09 | [297 16] |
| 62 | Accept | 0.21488 | 1.8467 | 0.20947 | 0.20947 | none | true | 6.7267e-08 | [ 1 7 13] |
| 63 | Accept | 0.22028 | 63.616 | 0.20947 | 0.20932 | none | true | 3.7479e-07 | [227 157] |
| 64 | Accept | 0.21964 | 81.089 | 0.20947 | 0.20947 | none | true | 3.3729e-08 | [236 263 240] |
| 65 | Accept | 0.226 | 58.8 | 0.20947 | 0.20947 | sigmoid | true | 3.2435e-09 | [ 3 268 16] |
| 66 | Accept | 0.28512 | 62.087 | 0.20947 | 0.20947 | sigmoid | true | 1.6061e-07 | [293 1] |
| 67 | Accept | 0.74189 | 0.39413 | 0.20947 | 0.20947 | none | false | 31.159 | [292 12] |
| 68 | Accept | 0.30833 | 56.986 | 0.20947 | 0.20947 | sigmoid | true | 3.2135e-09 | 285 |
| 69 | Accept | 0.2206 | 4.3217 | 0.20947 | 0.20927 | relu | true | 1.3908e-05 | 1 |
| 70 | Accept | 0.21519 | 47.818 | 0.20947 | 0.20935 | sigmoid | true | 3.634e-08 | [ 1 221 16] |
| 71 | Accept | 0.21488 | 4.2978 | 0.20947 | 0.20935 | none | true | 4.2772e-09 | [ 1 15 116] |
| 72 | Accept | 0.22123 | 35.165 | 0.20947 | 0.20929 | none | false | 1.772e-05 | [ 6 270] |
| 73 | Accept | 0.21488 | 17.014 | 0.20947 | 0.20926 | none | true | 5.6831e-06 | [ 1 123] |
| 74 | Accept | 0.21964 | 16.494 | 0.20947 | 0.20929 | none | true | 1.584e-05 | 278 |
| 75 | Accept | 0.21424 | 10.535 | 0.20947 | 0.20929 | sigmoid | true | 4.1488e-06 | [ 1 18] |
| 76 | Accept | 0.21583 | 15.623 | 0.20947 | 0.2068 | sigmoid | true | 5.3271e-07 | [ 1 4 45] |
| 77 | Accept | 0.23045 | 53.687 | 0.20947 | 0.20933 | sigmoid | true | 2.799e-05 | 295 |
| 78 | Accept | 0.21424 | 49.711 | 0.20947 | 0.20927 | sigmoid | false | 1.5769e-06 | [ 1 290] |
| 79 | Accept | 0.24317 | 23.256 | 0.20947 | 0.20695 | sigmoid | true | 9.9752e-05 | [ 1 2 75] |
| 80 | Accept | 0.74189 | 0.59847 | 0.20947 | 0.20646 | tanh | true | 31.477 | [276 1] |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 81 | Accept | 0.21265 | 8.0742 | 0.20947 | 0.20633 | sigmoid | false | 2.3742e-08 | 1 |
| 82 | Accept | 0.21964 | 10.426 | 0.20947 | 0.20625 | none | true | 2.4884e-06 | [ 28 19] |
| 83 | Accept | 0.22028 | 1.3151 | 0.20947 | 0.2062 | none | true | 7.322e-05 | 1 |
| 84 | Accept | 0.24857 | 61.832 | 0.20947 | 0.20615 | tanh | false | 3.2805e-09 | [246 6] |
| 85 | Accept | 0.26828 | 57.879 | 0.20947 | 0.20612 | tanh | true | 3.3231e-05 | 268 |
| 86 | Accept | 0.2651 | 39.828 | 0.20947 | 0.206 | tanh | true | 2.978e-05 | [ 1 211 1] |
| 87 | Accept | 0.22092 | 9.3782 | 0.20947 | 0.20593 | none | false | 3.4358e-08 | [ 6 10 8] |
| 88 | Accept | 0.21551 | 9.2736 | 0.20947 | 0.20895 | relu | true | 6.6466e-07 | [ 1 8] |
| 89 | Accept | 0.32295 | 8.2648 | 0.20947 | 0.20834 | relu | true | 3.6643e-09 | [ 1 29 4] |
| 90 | Accept | 0.21615 | 10.897 | 0.20947 | 0.20844 | tanh | false | 5.9606e-06 | [ 1 9] |
| 91 | Accept | 0.21933 | 11.781 | 0.20947 | 0.2083 | none | false | 1.1645e-06 | [ 22 50] |
| 92 | Accept | 0.21805 | 25.108 | 0.20947 | 0.20814 | none | true | 0.00017742 | [300 49] |
| 93 | Accept | 0.21901 | 12.868 | 0.20947 | 0.20803 | none | true | 3.8704e-05 | [ 23 9 45] |
| 94 | Accept | 0.21488 | 8.2557 | 0.20947 | 0.20803 | none | true | 5.7435e-07 | [ 1 3 25] |
| 95 | Accept | 0.32517 | 50.563 | 0.20947 | 0.20776 | tanh | true | 3.1834e-09 | 274 |
| 96 | Accept | 0.21488 | 10.904 | 0.20947 | 0.20801 | tanh | true | 4.5154e-07 | [ 1 16] |
| 97 | Accept | 0.21392 | 11.16 | 0.20947 | 0.20803 | none | false | 3.1889e-09 | [ 15 32 1] |
| 98 | Accept | 0.21583 | 20.833 | 0.20947 | 0.20983 | relu | true | 1.8928e-07 | [ 1 61] |
| 99 | Accept | 0.21329 | 7.1721 | 0.20947 | 0.21001 | sigmoid | true | 5.836e-09 | 1 |
| 100 | Accept | 0.21996 | 3.3651 | 0.20947 | 0.21027 | none | true | 1.0486e-08 | 11 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 100 reached.
Total function evaluations: 100
Total elapsed time: 2719.497 seconds
Total objective function evaluation time: 2661.8987
Best observed feasible point:
Activations Standardize Lambda LayerSizes
___________ ___________ __________ ___________
relu true 4.7245e-07 2 3 6
Observed objective function value = 0.20947
Estimated objective function value = 0.21027
Function evaluation time = 7.8527
Best estimated feasible point (according to models):
Activations Standardize Lambda LayerSizes
___________ ___________ __________ ___________
relu true 4.7245e-07 2 3 6
Estimated objective function value = 0.21027
Estimated function evaluation time = 11.1905

Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
LayerSizes: [2 3 6]
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl は学習させた ClassificationNeuralNetwork 分類器です。このモデルは、最適な観測実行可能点ではなく、最適な推定実行可能点に対応します (この区分の詳細については、bestPoint を参照してください)。ドット表記を使用して Mdl のプロパティにアクセスできます。たとえば、Mdl.HyperparameterOptimizationResults と指定すると、ニューラル ネットワーク モデルの最適化についての詳細情報を取得できます。
テスト データ セットで、モデルの分類精度を求めます。混同行列を使用して結果を可視化します。
modelAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
modelAccuracy = 0.8040
confusionchart(creditTest.Rating,predict(Mdl,creditTest))

このモデルでは、真のクラスから 1 単位以内にすべての予測クラスが含まれています。つまり、すべての予測で格付けが 1 つしか離れていません。
OptimizeHyperparameters 引数を使用してニューラル ネットワーク分類器に学習させ、結果の分類器の精度を改善します。関数 hyperparameters を使用して、使用する層数および層のサイズの範囲に既定より大きい値を指定します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。
creditrating = readtable("CreditRating_Historical.dat");変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);応答変数 Rating を categorical 変数に変換します。
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
データを学習セットとテスト セットに分割します。観測値の約 80% をニューラル ネットワーク モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。cvpartition を使用してデータを分割します。
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
Rating 応答を当てはめるこの問題に利用可能なハイパーパラメーターをリストします。
params = hyperparameters("fitcnet",creditTrain,"Rating"); for ii = 1:length(params) disp(ii);disp(params(ii)) end
1
optimizableVariable with properties:
Name: 'NumLayers'
Range: [1 3]
Type: 'integer'
Transform: 'none'
Optimize: 1
2
optimizableVariable with properties:
Name: 'Activations'
Range: {'relu' 'tanh' 'sigmoid' 'none'}
Type: 'categorical'
Transform: 'none'
Optimize: 1
3
optimizableVariable with properties:
Name: 'Standardize'
Range: {'true' 'false'}
Type: 'categorical'
Transform: 'none'
Optimize: 1
4
optimizableVariable with properties:
Name: 'Lambda'
Range: [3.1786e-09 31.7864]
Type: 'real'
Transform: 'log'
Optimize: 1
5
optimizableVariable with properties:
Name: 'LayerWeightsInitializer'
Range: {'glorot' 'he'}
Type: 'categorical'
Transform: 'none'
Optimize: 0
6
optimizableVariable with properties:
Name: 'LayerBiasesInitializer'
Range: {'zeros' 'ones'}
Type: 'categorical'
Transform: 'none'
Optimize: 0
7
optimizableVariable with properties:
Name: 'Layer_1_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 1
8
optimizableVariable with properties:
Name: 'Layer_2_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 1
9
optimizableVariable with properties:
Name: 'Layer_3_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 1
10
optimizableVariable with properties:
Name: 'Layer_4_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 0
11
optimizableVariable with properties:
Name: 'Layer_5_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 0
既定の 1 ~ 3 より多くの層を試すために、NumLayers (最適化可能な変数 1) の範囲を許容される最大サイズ [1 5] に設定します。また、Layer_4_Size および Layer_5_Size (それぞれ最適化可能な変数 10 および 11) を最適化されるように設定します。
params(1).Range = [1 5]; params(10).Optimize = true; params(11).Optimize = true;
すべての層のサイズは、範囲 (最適化可能な変数 7 ~ 11) を既定値 [1 300] ではなく [1 400] に設定します。
for ii = 7:11 params(ii).Range = [1 400]; end
学習データ creditTrain を関数 fitcnet に渡してニューラル ネットワーク分類器に学習させ、params に設定した OptimizeHyperparameters 引数を含めます。再現性を得るために、HyperparameterOptimizationOptions 構造体 の AcquisitionFunctionName を "expected-improvement-plus" に設定します。より適切な解を得るために、最適化のステップ数を既定値の 30 ではなく 100 に設定します。
rng("default") % For reproducibility Mdl = fitcnet(creditTrain,"Rating","OptimizeHyperparameters",params, ... "HyperparameterOptimizationOptions", ... struct("AcquisitionFunctionName","expected-improvement-plus", ... "MaxObjectiveEvaluations",100))
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 1 | Best | 0.74189 | 0.32605 | 0.74189 | 0.74189 | sigmoid | true | 0.68961 | [104 1 5 3 1] |
| 2 | Best | 0.2225 | 79.214 | 0.2225 | 0.24316 | relu | true | 0.00058564 | [ 38 208 162] |
| 3 | Accept | 0.63891 | 15.162 | 0.2225 | 0.22698 | sigmoid | true | 1.9768e-06 | [ 1 25 1 287 7] |
| 4 | Best | 0.21996 | 39.338 | 0.21996 | 0.22345 | none | false | 1.3353e-06 | 320 |
| 5 | Accept | 0.74189 | 0.13266 | 0.21996 | 0.21999 | relu | true | 2.7056 | [ 1 2 1] |
| 6 | Accept | 0.29466 | 110.23 | 0.21996 | 0.22 | relu | true | 1.0503e-06 | [301 31 400] |
| 7 | Accept | 0.68722 | 5.3887 | 0.21996 | 0.21999 | relu | true | 0.0113 | [ 97 5 56] |
| 8 | Accept | 0.29116 | 78.242 | 0.21996 | 0.21998 | relu | true | 7.5665e-05 | [311 93 3] |
| 9 | Accept | 0.3007 | 90.496 | 0.21996 | 0.21999 | relu | true | 5.6564e-08 | [ 29 375 84] |
| 10 | Best | 0.21138 | 84.357 | 0.21138 | 0.21129 | relu | true | 0.0002307 | [ 1 102 350] |
| 11 | Accept | 0.74189 | 0.14744 | 0.21138 | 0.2115 | none | false | 30.105 | 3 |
| 12 | Accept | 0.21392 | 7.445 | 0.21138 | 0.21149 | none | false | 3.2104e-09 | 3 |
| 13 | Accept | 0.21233 | 37.435 | 0.21138 | 0.21151 | none | false | 4.7078e-08 | [292 2] |
| 14 | Accept | 0.21488 | 12.59 | 0.21138 | 0.21156 | none | false | 6.6064e-08 | [ 7 1 227] |
| 15 | Accept | 0.30642 | 138.77 | 0.21138 | 0.21148 | relu | true | 1.5819e-05 | [137 164 319 49] |
| 16 | Accept | 0.74189 | 0.43973 | 0.21138 | 0.21149 | relu | true | 0.54894 | [ 1 392 16] |
| 17 | Accept | 0.22123 | 112.55 | 0.21138 | 0.21153 | relu | true | 2.2254e-05 | [ 2 385 175] |
| 18 | Accept | 0.22028 | 111.52 | 0.21138 | 0.21149 | none | false | 1.5532e-07 | [ 69 72 218 288] |
| 19 | Accept | 0.21933 | 74.082 | 0.21138 | 0.21147 | none | false | 3.8718e-09 | [ 23 172 251] |
| 20 | Accept | 0.21964 | 198.9 | 0.21138 | 0.21121 | none | false | 2.9122e-06 | [ 61 351 305] |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 21 | Accept | 0.21837 | 49.152 | 0.21138 | 0.21121 | none | false | 8.3868e-05 | [379 2 21 17] |
| 22 | Accept | 0.21774 | 11.13 | 0.21138 | 0.21514 | none | false | 3.7014e-05 | [ 1 103] |
| 23 | Accept | 0.21583 | 30.655 | 0.21138 | 0.21511 | none | false | 0.0013675 | [245 11 82 111 25] |
| 24 | Accept | 0.22187 | 47.861 | 0.21138 | 0.2151 | none | false | 0.00035852 | [143 7 2 6 399] |
| 25 | Accept | 0.2206 | 7.3635 | 0.21138 | 0.21151 | none | false | 1.3924e-08 | 4 |
| 26 | Accept | 0.22028 | 72.206 | 0.21138 | 0.21133 | none | false | 0.00029756 | [ 36 322 65 57 5] |
| 27 | Accept | 0.22028 | 24.303 | 0.21138 | 0.21149 | none | true | 3.5432e-09 | [186 7 99] |
| 28 | Accept | 0.28258 | 287.57 | 0.21138 | 0.21641 | relu | true | 0.00015562 | [127 381 376] |
| 29 | Accept | 0.21964 | 29.214 | 0.21138 | 0.21644 | none | true | 1.1567e-07 | [ 24 130 100] |
| 30 | Accept | 0.21615 | 38.832 | 0.21138 | 0.21645 | none | true | 1.3591e-05 | [ 27 2 300] |
| 31 | Accept | 0.25429 | 8.9728 | 0.21138 | 0.21011 | none | true | 0.0011686 | [ 38 21 182 15 1] |
| 32 | Accept | 0.74189 | 0.31341 | 0.21138 | 0.21137 | none | true | 0.21395 | [ 2 90 1 9 98] |
| 33 | Accept | 0.21392 | 9.1485 | 0.21138 | 0.20991 | none | true | 0.00013584 | [ 1 8 2 42] |
| 34 | Accept | 0.21488 | 2.4616 | 0.21138 | 0.20915 | none | true | 1.429e-08 | [ 1 9 2 3] |
| 35 | Accept | 0.21488 | 24.297 | 0.21138 | 0.20837 | none | true | 1.343e-06 | [ 1 267] |
| 36 | Accept | 0.32168 | 26.448 | 0.21138 | 0.20862 | relu | false | 3.5696e-07 | [ 1 2 51 9 75] |
| 37 | Accept | 0.29943 | 2.9924 | 0.21138 | 0.20852 | relu | false | 0.00015229 | 1 |
| 38 | Accept | 0.74189 | 0.94839 | 0.21138 | 0.20881 | relu | false | 0.063654 | [236 110 6] |
| 39 | Accept | 0.28671 | 52.298 | 0.21138 | 0.20818 | relu | false | 8.8086e-06 | [319 13] |
| 40 | Accept | 0.2438 | 29.767 | 0.21138 | 0.20839 | sigmoid | false | 4.5197e-09 | [ 70 10 7] |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 41 | Accept | 0.24189 | 64.101 | 0.21138 | 0.20807 | sigmoid | false | 2.9475e-07 | [ 57 19 163 6] |
| 42 | Accept | 0.22282 | 40.946 | 0.21138 | 0.2078 | sigmoid | false | 5.2093e-05 | [ 1 233] |
| 43 | Accept | 0.74189 | 1.8331 | 0.21138 | 0.20938 | sigmoid | false | 0.0038636 | [337 39 1] |
| 44 | Accept | 0.22155 | 17.147 | 0.21138 | 0.2091 | sigmoid | false | 7.0303e-06 | [ 1 11 34 2] |
| 45 | Accept | 0.21901 | 10.607 | 0.21138 | 0.20932 | tanh | false | 7.6416e-08 | [ 3 4] |
| 46 | Accept | 0.21933 | 33.754 | 0.21138 | 0.20899 | tanh | false | 2.9788e-06 | [ 2 2 67 22] |
| 47 | Accept | 0.22123 | 91.481 | 0.21138 | 0.20872 | tanh | false | 0.00030544 | [368 54] |
| 48 | Accept | 0.74189 | 0.45871 | 0.21138 | 0.20997 | tanh | false | 0.024399 | [ 1 60 26] |
| 49 | Accept | 0.24348 | 153.78 | 0.21138 | 0.21154 | tanh | false | 4.2e-05 | [336 169 2 9 2] |
| 50 | Accept | 0.27781 | 151.87 | 0.21138 | 0.21008 | tanh | false | 4.7612e-07 | [346 204 20] |
| 51 | Accept | 0.21488 | 55.554 | 0.21138 | 0.20963 | tanh | false | 3.4829e-09 | [ 1 232] |
| 52 | Accept | 0.21488 | 156.21 | 0.21138 | 0.20988 | tanh | true | 2.4638e-08 | [ 1 7 68 139 362] |
| 53 | Accept | 0.25842 | 54.398 | 0.21138 | 0.20963 | tanh | true | 8.926e-07 | [ 11 5 209] |
| 54 | Accept | 0.26891 | 66.331 | 0.21138 | 0.2093 | tanh | true | 3.4368e-09 | [247 4 5 17] |
| 55 | Accept | 0.21488 | 151.58 | 0.21138 | 0.20932 | tanh | true | 0.0005921 | [ 1 76 177 312] |
| 56 | Accept | 0.51335 | 11.191 | 0.21138 | 0.20974 | tanh | true | 0.025861 | [398 25] |
| 57 | Accept | 0.2117 | 11.729 | 0.21138 | 0.2091 | tanh | true | 5.6188e-05 | [ 2 1 11] |
| 58 | Accept | 0.28481 | 63.324 | 0.21138 | 0.20906 | relu | false | 3.2827e-09 | [383 13 40] |
| 59 | Accept | 0.2438 | 125.61 | 0.21138 | 0.20878 | tanh | true | 0.0001805 | [346 14 292 2] |
| 60 | Accept | 0.21583 | 8.8331 | 0.21138 | 0.2083 | tanh | false | 1.4495e-08 | 1 |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 61 | Accept | 0.21456 | 40.705 | 0.21138 | 0.20843 | tanh | false | 0.00012835 | [ 1 135] |
| 62 | Accept | 0.29085 | 105.56 | 0.21138 | 0.20768 | sigmoid | false | 1.7946e-05 | [330 94 1] |
| 63 | Accept | 0.21424 | 78.388 | 0.21138 | 0.20729 | sigmoid | false | 4.1216e-08 | [ 1 81 8 284] |
| 64 | Accept | 0.21456 | 103.52 | 0.21138 | 0.20732 | none | true | 0.00016065 | [389 7 221 2 396] |
| 65 | Accept | 0.36332 | 0.83293 | 0.21138 | 0.21536 | none | false | 0.0099272 | [ 1 9 29] |
| 66 | Accept | 0.21678 | 64.484 | 0.21138 | 0.2131 | none | true | 4.2307e-05 | [154 221 4] |
| 67 | Accept | 0.25556 | 97.467 | 0.21138 | 0.20741 | tanh | true | 7.0323e-08 | [ 3 30 384 1] |
| 68 | Accept | 0.22028 | 45.907 | 0.21138 | 0.20745 | none | true | 1.3544e-06 | [363 18] |
| 69 | Accept | 0.21996 | 21.112 | 0.21138 | 0.20744 | none | true | 2.0831e-08 | [350 30] |
| 70 | Accept | 0.21615 | 57.611 | 0.21138 | 0.20721 | tanh | true | 8.562e-06 | [ 1 11 200 4 29] |
| 71 | Accept | 0.29784 | 65.684 | 0.21138 | 0.20755 | sigmoid | true | 3.1815e-09 | 342 |
| 72 | Accept | 0.74189 | 0.14283 | 0.21138 | 0.20695 | tanh | true | 31.449 | 2 |
| 73 | Accept | 0.2225 | 11.234 | 0.21138 | 0.21304 | relu | true | 3.2834e-09 | [ 3 2] |
| 74 | Accept | 0.31278 | 20.754 | 0.21138 | 0.20495 | tanh | false | 1.099e-08 | [ 30 41] |
| 75 | Accept | 0.21392 | 20.019 | 0.21138 | 0.20461 | tanh | false | 3.5172e-07 | [ 1 18 8 29] |
| 76 | Accept | 0.21488 | 44.322 | 0.21138 | 0.21285 | tanh | true | 0.0001681 | [ 1 64 1 83 21] |
| 77 | Accept | 0.30356 | 31.829 | 0.21138 | 0.20648 | tanh | true | 3.2255e-05 | [ 32 25 41 25] |
| 78 | Accept | 0.21488 | 12.306 | 0.21138 | 0.20648 | none | false | 8.7968e-07 | [ 1 15 45 8] |
| 79 | Accept | 0.21265 | 14.523 | 0.21138 | 0.20629 | tanh | true | 3.1927e-09 | [ 1 20 14] |
| 80 | Accept | 0.2136 | 17.849 | 0.21138 | 0.2077 | relu | true | 0.00022487 | [ 1 6 3 38 45] |
|============================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes |
| | result | | runtime | (observed) | (estim.) | | | | |
|============================================================================================================================================|
| 81 | Accept | 0.25175 | 86.445 | 0.21138 | 0.20757 | sigmoid | false | 2.8027e-08 | [372 14 2] |
| 82 | Accept | 0.21488 | 3.9545 | 0.21138 | 0.21286 | none | true | 3.2854e-09 | [ 1 4 98] |
| 83 | Accept | 0.21933 | 6.6782 | 0.21138 | 0.214 | none | true | 7.8092e-05 | [ 32 11] |
| 84 | Accept | 0.21901 | 255.5 | 0.21138 | 0.21402 | none | false | 1.1069e-05 | [246 278 381 6 7] |
| 85 | Accept | 0.21869 | 46.923 | 0.21138 | 0.20835 | none | true | 2.5019e-07 | [380 7 5] |
| 86 | Accept | 0.21424 | 7.6385 | 0.21138 | 0.20716 | relu | true | 2.3756e-06 | 1 |
| 87 | Accept | 0.22155 | 11.623 | 0.21138 | 0.20866 | tanh | true | 0.00031371 | [ 1 13] |
| 88 | Accept | 0.74189 | 0.8902 | 0.21138 | 0.20838 | sigmoid | false | 30.269 | [ 1 214 10 198] |
| 89 | Accept | 0.28353 | 80.644 | 0.21138 | 0.20816 | sigmoid | false | 2.7729e-07 | [ 1 239 1 7 88] |
| 90 | Accept | 0.21424 | 75.378 | 0.21138 | 0.20825 | sigmoid | false | 6.4753e-09 | [ 1 5 40 311] |
| 91 | Accept | 0.21615 | 52.965 | 0.21138 | 0.20845 | tanh | false | 1.1159e-07 | [ 1 13 175] |
| 92 | Accept | 0.21519 | 14.358 | 0.21138 | 0.20859 | none | false | 5.6623e-06 | [ 1 31 27 24] |
| 93 | Accept | 0.21297 | 17.457 | 0.21138 | 0.21432 | tanh | true | 7.9886e-09 | [ 1 7 35] |
| 94 | Accept | 0.21615 | 43.228 | 0.21138 | 0.20911 | none | true | 6.0944e-06 | [ 3 61 11 90 83] |
| 95 | Accept | 0.25683 | 11.12 | 0.21138 | 0.20918 | tanh | false | 2.8053e-05 | [ 1 10 1] |
| 96 | Accept | 0.32676 | 53.385 | 0.21138 | 0.21405 | relu | true | 3.4352e-09 | [315 2 8] |
| 97 | Accept | 0.21933 | 9.813 | 0.21138 | 0.20966 | none | false | 1.5781e-08 | 41 |
| 98 | Accept | 0.34488 | 72.967 | 0.21138 | 0.20338 | relu | true | 3.2814e-09 | [ 1 21 2 75 348] |
| 99 | Accept | 0.21583 | 227.25 | 0.21138 | 0.20342 | none | true | 1.3976e-08 | [ 2 260 237 130 346] |
| 100 | Accept | 0.2136 | 94.144 | 0.21138 | 0.20316 | tanh | false | 3.7209e-07 | [ 1 42 1 2 359] |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 100 reached.
Total function evaluations: 100
Total elapsed time: 5308.1522 seconds
Total objective function evaluation time: 5250.0671
Best observed feasible point:
Activations Standardize Lambda LayerSizes
___________ ___________ _________ _______________
relu true 0.0002307 1 102 350
Observed objective function value = 0.21138
Estimated objective function value = 0.20316
Function evaluation time = 84.3573
Best estimated feasible point (according to models):
Activations Standardize Lambda LayerSizes
___________ ___________ _________ _______________
relu true 0.0002307 1 102 350
Estimated objective function value = 0.20316
Estimated function evaluation time = 73.1472

Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
LayerSizes: [1 102 350]
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
テスト データ セットで、モデルの分類精度を求めます。混同行列を使用して結果を可視化します。
testAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
testAccuracy = 0.8015
confusionchart(creditTest.Rating,predict(Mdl,creditTest))

このモデルでは、真のクラスから 1 単位以内にすべての予測クラスが含まれています。つまり、すべての予測で格付けが 1 つしか離れていません。
入力引数
名前と値の引数
出力引数
詳細
既定のニューラル ネットワーク分類器の層構造は次のとおりです。
| 構造 | 説明 |
|---|---|
|
| 入力 — この層は Tbl または X の予測子データに対応します。 |
最初の全結合層 — この層の出力数は既定では 10 です。
| |
ReLU 活性化関数 — この活性化関数は
| |
最終全結合層 — この層の出力数は K で、K は応答変数内のクラス数です。
| |
ソフトマックス関数 (バイナリ分類とマルチクラス分類の両方) — この活性化関数は 結果は予測分類スコア (または事後確率) に対応します。 | |
| 出力 — この層は予測クラス ラベルに対応します。 |

この層構造のニューラル ネットワーク分類器で予測を返す例については、ニューラル ネットワーク分類器の層の構造を使用した予測を参照してください。
カスタムのニューラル ネットワーク アーキテクチャを指定するには、Network 引数を使用します。 (R2025a 以降)
ヒント
数値予測子は可能であれば常に標準化します (
Standardizeを参照)。標準化を行うと、予測子を測定するスケールの影響を受けなくなります。モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
参照
[1] Glorot, Xavier, and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks.” In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pp. 249–256. 2010.
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.” In Proceedings of the IEEE international conference on computer vision, pp. 1026–1034. 2015.
[3] Nocedal, J. and S. J. Wright. Numerical Optimization, 2nd ed., New York: Springer, 2006.
拡張機能
バージョン履歴
R2021a で導入参考
ClassificationNeuralNetwork | predict | loss | hyperparameters | margin | edge | ClassificationPartitionedModel | CompactClassificationNeuralNetwork | dlnetwork (Deep Learning Toolbox)