このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
ClassificationNeuralNetwork
分類用のニューラル ネットワーク モデル
説明
ClassificationNeuralNetwork オブジェクトは、全結合のフィードフォワード ネットワークなどの分類用学習済みニューラル ネットワークです。全結合のフィードフォワード ネットワークでは、最初の全結合層にネットワーク入力 (予測子データ X) からの結合があり、後続の各層に前の層からの結合があります。各全結合層では、入力に重み行列 (LayerWeights) が乗算されてからバイアス ベクトル (LayerBiases) が加算されます。各全結合層の後には活性化関数 (Activations および OutputLayerActivation) が続きます。最終全結合層とそれに続くソフトマックス活性化関数によってネットワークの出力、つまり分類スコア (事後確率) および予測ラベルが生成されます。詳細については、ニューラル ネットワークの構造を参照してください。
作成
ClassificationNeuralNetwork オブジェクトの作成には fitcnet を使用します。
プロパティ
オブジェクト関数
例
ニューラル ネットワーク分類器に学習させ、テスト セットで分類器の性能を評価します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。データ セットの最初の数行をプレビューします。
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating) ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);応答変数 Rating を categorical 変数に変換します。
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
データを学習セットとテスト セットに分割します。観測値の約 80% をニューラル ネットワーク モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。cvpartition を使用してデータを分割します。
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
学習データ creditTrain を関数 fitcnet に渡して、ニューラル ネットワーク分類器に学習させます。
Mdl = fitcnet(creditTrain,"Rating")Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl は学習させた ClassificationNeuralNetwork 分類器です。ドット表記を使用して Mdl のプロパティにアクセスできます。たとえば、Mdl.TrainingHistory と指定すると、ニューラル ネットワーク モデルの学習履歴についての詳細情報を取得できます。
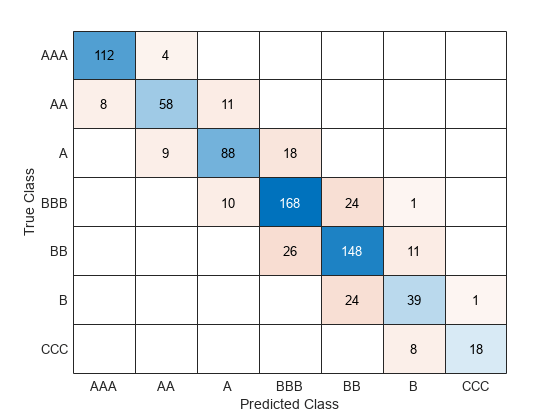
テスト セットの分類誤差を計算して、テスト セットで分類器の性能を評価します。混同行列を使用して結果を可視化します。
testAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
testAccuracy = 0.7977
confusionchart(creditTest.Rating,predict(Mdl,creditTest))
Deep Learning Toolbox™ を使用してカスタムのニューラル ネットワーク アーキテクチャを指定します。
レーダー信号のデータを含む ionosphere データ セットを読み込みます。X に予測子データが格納されており、応答変数の Y にレーダー信号が良好 ("g") か不良 ("b") かを表す値が格納されます。
load ionosphere層化ホールドアウト分割を使用して、データを学習データ (XTrain および YTrain) とテスト データ (XTest および YTest) に分割します。観測値の約 30% をテスト用に予約し、残りの観測値を学習に使用します。
rng("default") % For reproducibility of the partition cvp = cvpartition(Y,Holdout=0.3); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
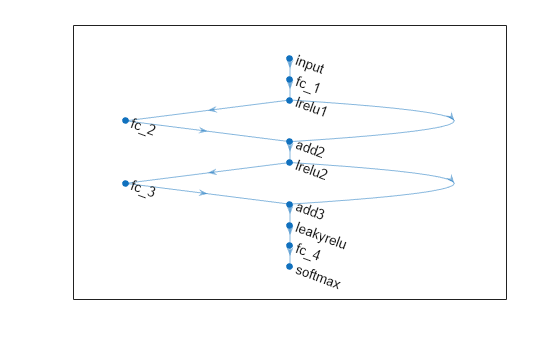
次の特性をもつニューラル ネットワーク アーキテクチャを定義します。
予測子の数と一致する入力サイズをもつ特徴入力層。
3 つの全結合層とそれに続く leaky ReLU 層が直列に接続され、全結合層の出力サイズは 16、2 番目と 3 番目の全結合層の後には加算層がある。
2 番目と 3 番目の全結合層についてのスキップ接続。加算層を使用。
クラスの数と一致する出力サイズをもつ最終全結合層、その後にソフトマックス層。
inputSize = size(XTrain,2);
outputSize = numel(unique(YTrain));
net = dlnetwork;
layers = [
featureInputLayer(inputSize)
fullyConnectedLayer(30)
leakyReluLayer(Name="lrelu1")
fullyConnectedLayer(30)
additionLayer(2,Name="add2")
leakyReluLayer(Name="lrelu2")
fullyConnectedLayer(30)
additionLayer(2,Name="add3")
leakyReluLayer
fullyConnectedLayer(outputSize)
softmaxLayer];
net = addLayers(net,layers);
net = connectLayers(net,"lrelu1","add2/in2");
net = connectLayers(net,"lrelu2","add3/in2");ニューラル ネットワーク アーキテクチャをプロットで可視化します。
figure plot(net)
ニューラル ネットワーク分類器に学習させます。
Mdl = fitcnet(XTrain,YTrain,Network=net,Standardize=true)
Mdl =
ClassificationNeuralNetwork
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 246
LayerSizes: []
Activations: ''
OutputLayerActivation: ''
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [30×5 table]
View network information using dlnetwork.
Properties, Methods
学習させた分類器の性能を推定するには、テスト セットの分類誤差を計算します。
testError = loss(Mdl,XTest,YTest, ... LossFun="classiferror")
testError = 0.0774
拡張機能
バージョン履歴
R2021a で導入参考
fitcnet | predict | loss | margin | edge | ClassificationPartitionedModel | CompactClassificationNeuralNetwork | dlnetwork (Deep Learning Toolbox)