margin
ニューラル ネットワーク分類器の分類マージン
構文
説明
例
ニューラル ネットワーク分類器のテスト セットの分類マージンを計算します。
patients データ セットを読み込みます。データ セットから table を作成します。各行が 1 人の患者に対応し、各列が診断の変数に対応します。変数 Smoker を応答変数として使用し、残りの変数を予測子として使用します。
load patients
tbl = table(Diastolic,Systolic,Gender,Height,Weight,Age,Smoker);層化ホールドアウト分割を使用して、データを学習セット tblTrain とテスト セット tblTest に分割します。観測値の約 30% がテスト データ セット用に予約され、残りの観測値が学習データ セットに使用されます。
rng("default") % For reproducibility of the partition c = cvpartition(tbl.Smoker,"Holdout",0.30); trainingIndices = training(c); testIndices = test(c); tblTrain = tbl(trainingIndices,:); tblTest = tbl(testIndices,:);
学習セットを使用してニューラル ネットワーク分類器に学習させます。tblTrain の列 Smoker を応答変数として指定します。数値予測子を標準化するための指定を行います。
Mdl = fitcnet(tblTrain,"Smoker", ... "Standardize",true);
テスト セットの分類マージンを計算します。テスト セットに含まれる観測値は 30 個だけであるため、棒グラフを使用してマージンを表示します。
m = margin(Mdl,tblTest,"Smoker"); bar(m) xlabel("Observation") ylabel("Margin") title("Test Set Margins")
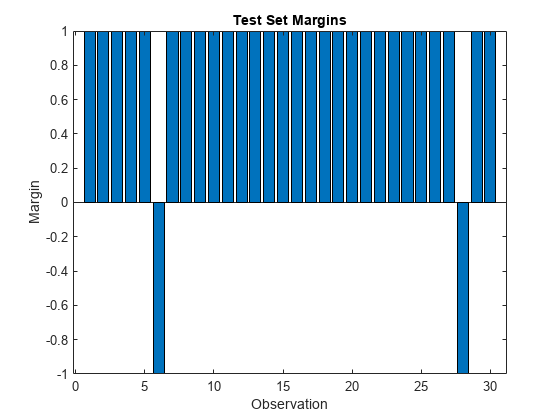
負のマージンは 6 番目と 28 番目の観測値だけであり、モデルの性能が全体的に高いことを示しています。
テスト セットの分類マージン、エッジ、誤差、予測を比較することにより、特徴選択を実行します。すべての予測子を使用して学習させたモデルのテスト セット メトリクスを予測子のサブセットのみを使用して学習させたモデルのテスト セット メトリクスと比較します。
標本ファイル fisheriris.csv を読み込みます。これには、アヤメについてのがく片の長さ、がく片の幅、花弁の長さ、花弁の幅、種の種類などのデータが格納されています。ファイルを table に読み込みます。
fishertable = readtable('fisheriris.csv');層化ホールドアウト分割を使用して、データを学習セット trainTbl とテスト セット testTbl に分割します。観測値の約 30% がテスト データ セット用に予約され、残りの観測値が学習データ セットに使用されます。
rng("default") c = cvpartition(fishertable.Species,"Holdout",0.3); trainTbl = fishertable(training(c),:); testTbl = fishertable(test(c),:);
学習セット内のすべての予測子を使用して 1 つのニューラル ネットワーク分類器に学習させ、PetalWidth を除くすべての予測子を使用してもう 1 つの分類器に学習させます。両方のモデルについて、Species を応答変数として指定し、予測子を標準化します。
allMdl = fitcnet(trainTbl,"Species","Standardize",true); subsetMdl = fitcnet(trainTbl,"Species ~ SepalLength + SepalWidth + PetalLength", ... "Standardize",true);
2 つのモデルのテスト セットの分類マージンを計算します。テスト セットに含まれる観測値は 45 個だけであるため、棒グラフを使用してマージンを表示します。
各観測値の分類マージンは、真のクラスの分類スコアと偽のクラスの最大スコアの差を表します。ニューラル ネットワーク分類器から返される分類スコアは事後確率であるため、マージンの値が 1 に近いほど信頼度が高い分類であることを示し、負のマージンの値は誤分類を示します。
tiledlayout(2,1) % Top axes ax1 = nexttile; allMargins = margin(allMdl,testTbl); bar(ax1,allMargins) xlabel(ax1,"Observation") ylabel(ax1,"Margin") title(ax1,"All Predictors") % Bottom axes ax2 = nexttile; subsetMargins = margin(subsetMdl,testTbl); bar(ax2,subsetMargins) xlabel(ax2,"Observation") ylabel(ax2,"Margin") title(ax2,"Subset of Predictors")
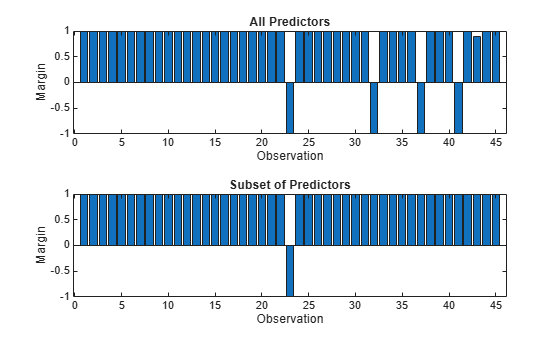
2 つのモデルのテスト セットの分類エッジ (分類マージンの平均) を比較します。
allEdge = edge(allMdl,testTbl)
allEdge = 0.8198
subsetEdge = edge(subsetMdl,testTbl)
subsetEdge = 0.9556
テスト セットの分類マージンと分類エッジからは、予測子のサブセットで学習させたモデルの方がすべての予測子で学習させたモデルよりも性能が優れていると考えられます。
2 つのモデルのテスト セットの分類誤差を比較します。
allError = loss(allMdl,testTbl); allAccuracy = 1-allError
allAccuracy = 0.9111
subsetError = loss(subsetMdl,testTbl); subsetAccuracy = 1-subsetError
subsetAccuracy = 0.9778
この場合も、予測子のサブセットのみを使用して学習させたモデルの方がすべての予測子を使用して学習させたモデルよりも性能が優れていることがわかります。
混同行列を使用してテスト セットの分類結果を可視化します。
allLabels = predict(allMdl,testTbl);
figure
confusionchart(testTbl.Species,allLabels)
title("All Predictors")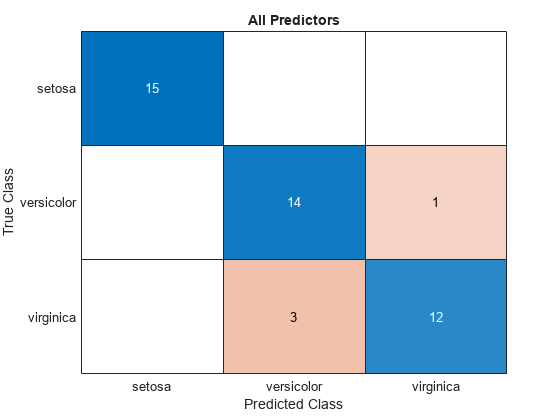
subsetLabels = predict(subsetMdl,testTbl);
figure
confusionchart(testTbl.Species,subsetLabels)
title("Subset of Predictors")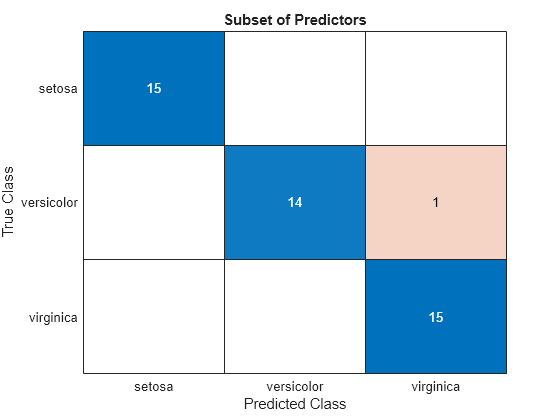
すべての予測子を使用して学習させたモデルには、テスト セットの観測値の誤分類が 4 件あります。予測子のサブセットを使用して学習させたモデルでは、テスト セットの観測値の誤分類は 1 件だけです。
2 つのモデルのテスト セットの性能から、PetalWidth を除くすべての予測子を使用して学習させたモデルを使用することを検討します。