分類学習器アプリのハイパーパラメーターの最適化
決定木やサポート ベクター マシン (SVM) など、学習させる特定のモデルのタイプを選択した後、別の詳細オプションを選択してモデルを調整できます。たとえば、決定木または SVM のボックス制約に対する最大分割数を変更できます。これらのオプションの一部はモデルの内部パラメーターまたはハイパーパラメーターであり、その性能に大きく影響します。これらのオプションを手動で選択するのではなく、分類学習器アプリ内でハイパーパラメーターの最適化を使用してハイパーパラメーター値の選択を自動化できます。特定のモデル タイプに対し、モデルの分類誤差を最小化しようとする最適化法を使用してさまざまなハイパーパラメーター値の組み合わせが試され、最適化されたハイパーパラメーターをもつモデルが返されます。結果のモデルは他の学習済みモデルと同じように使用できます。
メモ
ハイパーパラメーターの最適化によってモデルが過適合になることがあるため、分類学習器アプリにデータをインポートする前にテスト データ セットを別途作成することを推奨します。最適化可能なモデルに学習させた後、テスト データ セットで性能を確認できます。たとえば、分類学習器アプリでハイパーパラメーターの最適化を使用した分類器の学習を参照してください。
分類学習器でハイパーパラメーターの最適化を実行するには、以下の手順に従います。
モデル タイプを選択し、最適化するハイパーパラメーターを決定します。最適化するハイパーパラメーターの選択 を参照してください。
メモ
ハイパーパラメーターの最適化はバイナリ GLM ロジスティック回帰モデルではサポートされません。
(オプション) 最適化が実行される方法を指定します。詳細は、最適化オプションを参照してください。
モデルに学習させます。最小分類誤差のプロットを使用して最適化の結果を追跡します。
学習済みモデルを検査します。最適化の結果 を参照してください。
最適化するハイパーパラメーターの選択
分類学習器アプリで、[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。ギャラリーにはハイパーパラメーターの最適化を使用して学習させることができる最適化可能なモデルが含まれます。
最適化可能なモデルを選択した後、最適化するハイパーパラメーターを選択できます。モデルの [概要] タブの [モデルのハイパーパラメーター] セクションで、最適化するハイパーパラメーターの [最適化] チェック ボックスを選択します。[値] で、最適化すべきでないハイパーパラメーターまたは最適化不可能なハイパーパラメーターに対して固定値を指定します。
次の表では、モデルのタイプごとに最適化できるハイパーパラメーターと、各ハイパーパラメーターの検索範囲について説明します。これには固定値を指定できる追加ハイパーパラメーターも含まれています。
| モデル | 最適化可能なハイパーパラメーター | 追加ハイパーパラメーター | メモ: |
|---|---|---|---|
| 最適化可能なツリー |
|
| 詳細は、木モデルのハイパーパラメーターのオプションを参照してください。 |
| 最適化可能な判別 |
|
詳細は、判別モデルのハイパーパラメーターのオプションを参照してください。 | |
| 最適化可能な単純ベイズ |
|
|
詳細は、単純ベイズ モデルのハイパーパラメーターのオプションを参照してください。 |
| 最適化可能な SVM |
|
詳細は、SVM モデルのハイパーパラメーターのオプションを参照してください。 | |
| 最適化できる効率的な線形 |
|
| 詳細については、効率的に学習させた線形分類器のハイパーパラメーターのオプションを参照してください。 |
| 最適化可能な KNN |
| 詳細は、KNN モデルのハイパーパラメーターのオプションを参照してください。 | |
| 最適化可能なカーネル |
|
| 詳細については、カーネル モデルのハイパーパラメーターのオプションを参照してください。 |
| 最適化可能なアンサンブル |
|
|
詳細は、アンサンブル モデルのハイパーパラメーターのオプションを参照してください。 |
| 最適化可能なニューラル ネットワーク |
|
| 詳細については、ニューラル ネットワーク モデルのハイパーパラメーターのオプションを参照してください。 |
最適化オプション
既定では、分類学習器アプリはベイズ最適化を使用してハイパーパラメーター調整を実行します。ベイズ最適化 (一般に、最適化) の目的は、目的関数を最小化する点を見つけることです。アプリのハイパーパラメーター調整のコンテキストにおいて、点は一連のハイパーパラメーター値であり、目的関数は損失関数または分類誤差です。ベイズ最適化の基本の詳細については、ベイズ最適化のワークフローを参照してください。
ハイパーパラメーター調整が実行される方法を指定できます。たとえば、最適化手法をグリッド探索または学習時間の制限に変更できます。[学習] タブの [オプション] セクションで [オプティマイザー] をクリックします。ダイアログ ボックスが開き、ここで最適化オプションを選択できます。
選択したら、[保存して適用] をクリックします。選択内容は [モデル] ペインのすべての最適化可能なドラフト モデルに影響し、[学習] タブの [モデル] セクションのギャラリーを使用して作成する新しい最適化可能なモデルに適用されます。
単一の最適化可能なモデルの最適化オプションを指定するには、モデルに学習させる前にモデルの概要を開いて編集します。[モデル] ペインでモデルをクリックします。モデルの [概要] タブには、編集可能な [オプティマイザー] セクションが含まれています。
次の表では、使用可能な最適化オプションとそれらの既定値について説明します。
| オプション | 説明 |
|---|---|
| オプティマイザー | オプティマイザーの値は次のとおりです。
|
| 獲得関数 | ハイパーパラメーター調整に対してベイズ最適化が実行される場合、獲得関数を使用して次に試すハイパーパラメーター値のセットが決定されます。 獲得関数の値は次のとおりです。
これらの獲得関数がベイズ最適化のコンテキストでどのように機能するかの詳細については、獲得関数のタイプを参照してください。 |
| 反復 | 各反復は、試行されるハイパーパラメーター値の組み合わせに対応します。ベイズ最適化または、ランダム探索を使用する場合は、反復回数を設定する正の整数を指定します。既定値は グリッド探索を使用すると、[反復] の値は無視され、グリッド全体の点ごとに損失が評価されます。学習時間制限を設定して最適化プロセスを途中で停止できます。 |
| 学習時間制限 | 学習時間制限を設定するには、このオプションを選択し、[最大学習時間 (秒単位)] オプションを設定します。既定では、学習時間制限はありません。 |
| 最大学習時間 (秒単位) | 学習時間制限 (秒単位) を正の実数として設定します。既定値は 300 です。この制限は反復評価を中断させないため、実行時間が学習時間制限を超える可能性があります。 |
| グリッド分割数 | グリッド探索を使用する場合、数値ハイパーパラメーターごとに試行される値の数として正の整数を設定します。この値は categorical ハイパーパラメーターに対して無視されます。既定値は 10 です。 |
最小分類誤差のプロット
ハイパーパラメーターで最適化するモデルを指定し、追加の最適化オプションを設定した後 (オプション)、最適化可能なモデルに学習させます。[学習] タブの [学習] セクションで、[すべてを学習] をクリックして [選択を学習] を選択します。[最小分類誤差のプロット] が作成され、最適化が実行されると更新されます。
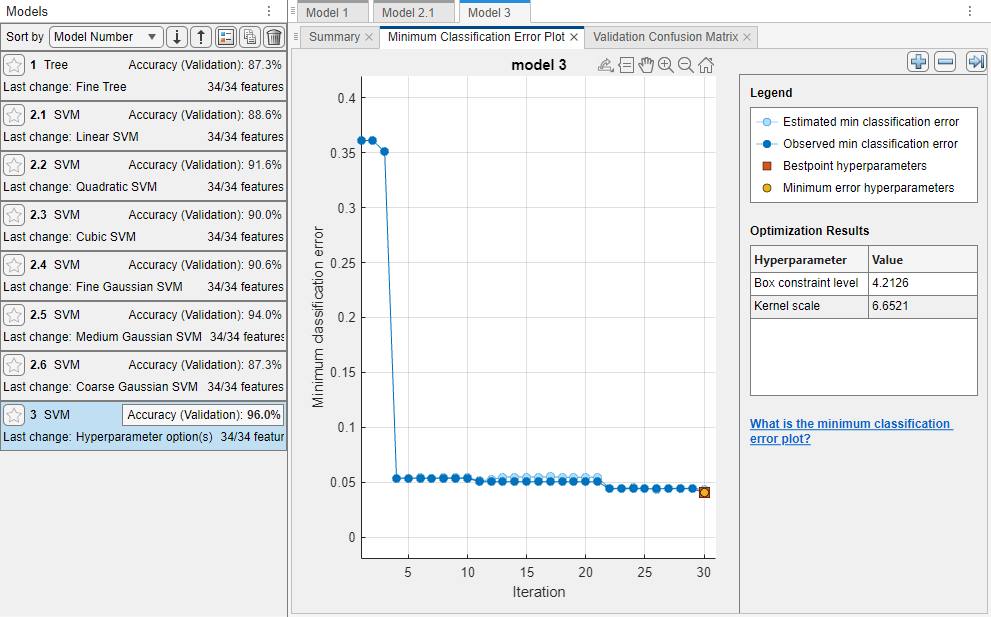
最小分類誤差のプロットには以下の情報が表示されます。
推定された最小分類誤差 – 薄い青の各点は、最適化プロセスで計算された最小分類誤差の推定値に対応し、それまで試行されたすべてのハイパーパラメーター値のセット (現在の反復を含む) が考慮されます。詳細については、
BayesianOptimizationオブジェクトのEstimatedObjectiveMinimumTraceプロパティを参照してください。グリッド探索またはランダム探索を使用してハイパーパラメーターの最適化を実行する場合、これらの薄い青の点は表示されません。
観測された最小分類誤差 – 濃い青の各点は、それまでに最適化プロセスで計算された、観測された最小分類誤差に対応します。たとえば、3 回目の反復では、濃い青の点は 1 回目、2 回目、および 3 回目の反復で観測された分類誤差に対応します。
最良点ハイパーパラメーター – 赤色の正方形は最適化されたハイパーパラメーターに対応する反復を示します。[最適化の結果] の下でプロットの右上に一覧表示されている最適化されたハイパーパラメーターの値を見つけることができます。
最適化されたハイパーパラメーターが常に観測された最小値分類誤差を提供するとは限りません。このアプリがベイズ最適化を使用してハイパーパラメーター調整を実行すると (簡単な紹介については、最適化オプションを参照)、分類誤差を最小化するセットではなく、分類誤差の目的関数モデルの信頼区間の上限を最小化するハイパーパラメーター値のセットが選択されます。詳細については、
bestPointの名前と値の引数"Criterion","min-visited-upper-confidence-interval"を参照してください。最小誤差ハイパーパラメーター – 黄色の点は、観測された分類誤差が最小になるハイパーパラメーターに対応する反復を示しています。
詳細については、
bestPointの名前と値の引数"Criterion","min-observed"を参照してください。
プロットで欠損している点は NaN 最小分類誤差値に対応します。
最適化の結果
アプリがモデルのハイパーパラメーターの調整を終了すると、最適化されたハイパーパラメーターの値 ([最良点ハイパーパラメーター]) で学習されたモデルが返されます。モデル メトリクスはプロットとして表示され、エクスポートされたモデルはハイパーパラメーターの固定値をもつ、この学習済みモデルに対応します。
モデル化するベイズ最適化を使用してハイパーパラメーター調整を実行し、学習済みの最適化可能なモデルを構造体としてワークスペースにエクスポートすると、構造体の HyperParameterOptimizationResult フィールドには BayesianOptimization オブジェクトが格納されます。オブジェクトには、各最適化反復の結果と、アプリで実行された最適化のうち最も適した最終結果が含まれています。
学習済み最適化可能なモデルの最適化結果を調べるには、[モデル] ペインでモデルを選択し、モデルの [概要] タブを確認します。

モデルの [概要] タブには以下のセクションが含まれています。
学習結果 – 最適化可能なモデルの性能を示します。[概要] タブと [モデル] ペインでのモデル メトリクスの表示を参照してください。
モデルのハイパーパラメーター – 最適化可能なモデルのタイプを表示し、ハイパーパラメーターの固定値をすべて一覧表示します
最適化されたハイパーパラメーター – 最適化されたハイパーパラメーターの値を一覧表示します
ハイパーパラメーターの検索範囲 – 最適化されたハイパーパラメーターの検索範囲を表示します
オプティマイザー – 選択したオプティマイザーのオプションを示します
学習済み最適化可能なモデルから MATLAB® コードを生成すると、生成されたコードはモデルの最適化されたハイパーパラメーターの固定値を使用して新しいデータで学習します。生成されたコードに最適化プロセスは含まれません。近似関数の使用時にベイズ最適化を実行する方法の詳細については、近似関数を使用したベイズ最適化を参照してください。