分類学習器アプリの使用による特徴選択と特徴変換
散布図における特徴量の調査
分類学習器では、異なる予測子のペアを散布図にプロットすることにより、クラスを十分に分類する予測子を特定します。このプロットは、どの特徴量を追加または除外するかを調べるために役立ちます。学習データと誤分類点を散布図で可視化できます。
分類器に学習をさせる前は、データが散布図に表示されます。分類器に学習をさせた後では、モデルの予測結果が散布図に表示されます。プロットをデータのみに切り替えるには、[プロット] のコントロールで [データ] を選択します。
[予測子] の [X] と [Y] のリストを使用して、プロットする特徴量を選択します。
クラスを十分に分離する予測子を探します。たとえば、
fisheririsのデータをプロットすると、がく片の長さとがく片の幅によりクラスの 1 つ (setosa) が十分に分離されることがわかります。他の 2 つのクラスを分離できるかどうかを調べるには、別の予測子をプロットする必要があります。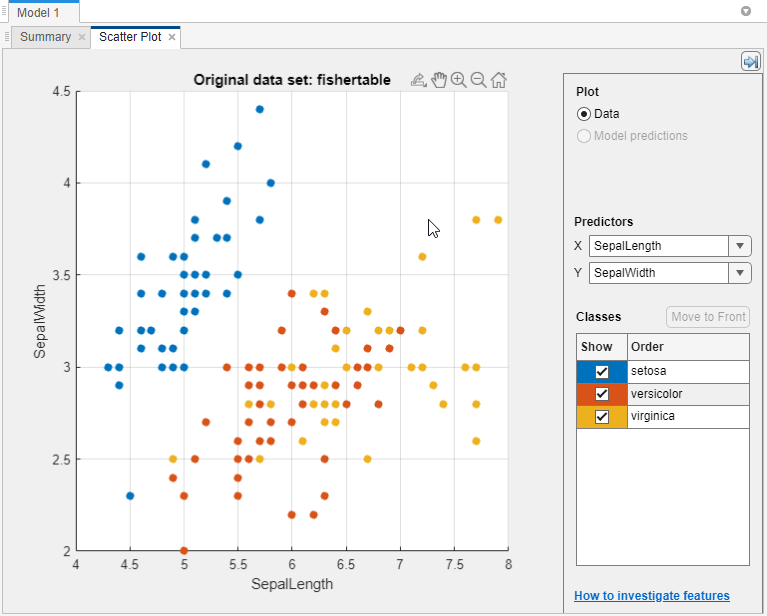
特定のクラスを表示または非表示にするには、[表示] のチェック ボックスを使用します。
プロットしたクラスのスタックの順番を変更するには、[クラス] でクラスを選択してから [最前面へ移動] をクリックします。
詳細を調べるには、ズームインやズームアウト、およびプロットの移動を行います。ズームまたは移動は、散布図上にマウスを移動させ、プロットの右上隅に表示されるツール バーの対応するボタンをクリックすることで有効になります。
クラスの分離に役立たない予測子を識別した場合は、[特徴選択] を使用してその予測子を削除し、最も有用な予測子のみが含まれている分類器に学習をさせます。含める特徴量の選択を参照してください。
分類器に学習をさせた後では、モデルの予測結果が散布図に表示されます。正しい結果または正しくない結果を表示または非表示にし、結果をクラスごとに可視化することができます。分類器の結果のプロットを参照してください。
アプリで作成した散布図を Figure にエクスポートできます。分類学習器アプリのプロットのエクスポートを参照してください。
含める特徴量の選択
分類学習器では、モデルに含めるさまざまな特徴量 (予測子) を指定できます。予測力が低い特徴量を削除するとモデルが向上するか確認してください。データの収集が高価または困難な場合、一部の予測子がなくても十分に機能するモデルが好ましい可能性があります。
さまざまな特徴ランク付けアルゴリズムを使用して、含める重要な予測子を判別できます。アプリで特徴ランク付けアルゴリズムを選択すると、特徴量の重要度スコアに応じて並べ替えられたプロットが表示されます。スコアが高いほど (Inf も含む)、特徴量の重要度が高いことを示します。さらに、ランク付けされた特徴とそのスコアの表もアプリに表示されます。
分類学習器で特徴ランク付けアルゴリズムを使用するには、[学習] タブの [オプション] セクションで [特徴選択] をクリックします。アプリで [既定の特徴選択] タブが開き、特徴ランク付けアルゴリズムを選択できます。
| 特徴ランク付けアルゴリズム | サポートされているデータ型 | 説明 |
|---|---|---|
| MRMR | categorical 特徴量および連続的特徴量 | Minimum Redundancy Maximum Relevance (MRMR) アルゴリズムを使用して逐次的に特徴量をランク付けします。 詳細については、 |
| Chi2 | categorical 特徴量および連続的特徴量 | 個々のカイ二乗検定を使用して各予測子変数が応答変数から独立しているかどうかを調べた後、カイ二乗検定統計量の p 値を使用して特徴量をランク付けします。スコアは –log(p) に対応します。 詳細については、 |
| ReliefF | すべての categorical 特徴量またはすべての連続的特徴量のいずれか。以下のいずれかに該当する場合、ReliefF はサポートされません。
| ReliefFアルゴリズムで 10 個の最近傍を使用して特徴量をランク付けします。ReliefF を選択すると、アプリでは、実際の予測子の値ではなく予測子の z スコア値 ( 詳細については、 |
| ANOVA | categorical 特徴量および連続的特徴量 | クラス別にグループされた各予測子変数に対して 1 因子分散分析を実行した後、p 値を使用して特徴量をランク付けします。それぞれの予測子変数について、アプリは、応答クラス別にグループ化された予測子の値が、平均が同じである複数の母集団から抽出されたという仮説を、母集団の平均はすべて同じではないという対立仮説に対して検定します。スコアは –log(p) に対応します。 詳細については、 |
| Kruskal Wallis | categorical 特徴量および連続的特徴量 | クラスカル・ワリス検定で返される p 値を使用して特徴量をランク付けします。それぞれの予測子変数について、アプリは、応答クラス別にグループ化された予測子の値が、中央値が同じである複数の母集団から抽出されたという仮説を、母集団の中央値はすべて同じではないという対立仮説に対して検定します。スコアは –log(p) に対応します。 詳細については、 |
最も高ランクの特徴を選択するか特徴を個別に選択するかを選択します。
検証メトリクスのバイアスを回避するには、[最も高ランクの特徴を選択] を選択します。たとえば、交差検証方式を使用する場合は、学習分割ごとに、モデルの学習前にアプリが特徴選択を行います。異なる分割では、最高ランクの特徴として異なる予測子を選択できます。
モデルの学習に特定の特徴量を含めるには、[特徴を個別に選択] を選択します。交差検証方式を使用する場合、アプリはすべての学習分割で同じ特徴を使用します。
特徴の選択が完了したら、[保存して適用] をクリックします。選択内容は [モデル] ペインのすべてのドラフト モデルに影響し、[学習] タブの [モデル] セクションのギャラリーを使用して作成する新しいドラフト モデルに適用されます。
単一のドラフト モデルの特徴を選択するには、モデルの概要を開いて編集します。[モデル] ペインでモデルをクリックし、(必要に応じて) モデルの [概要] タブをクリックします。[概要] タブには、編集可能な [特徴選択] セクションが含まれています。
モデルに学習させた後、モデルの [概要] タブの [特徴選択] セクションに、完全なモデル (つまり、学習データと検証データを使用して学習させたモデル) の学習に使用された特徴のリストが表示されます。分類学習器が特徴選択をデータに適用する方法についてさらに学ぶには、学習済みの分類器についてコードを生成します。詳細については、新しいデータでモデルに学習をさせる MATLAB コードの生成を参照してください。
アプリで作成した特徴ランク付けプロットを Figure にエクスポートできます。分類学習器アプリのプロットのエクスポートを参照してください。
特徴選択を使用する例については、分類学習器アプリを使用した決定木の学習を参照してください。
分類学習器における PCA による特徴量の変換
主成分分析 (PCA) を使用すると、予測子空間の次元を減らすことができます。次元を減らすと、過適合の防止に役立つ分類モデルを分類学習器で作成できます。PCA は、冗長な次元を削除するために予測子を線形的に変換して、主成分と呼ばれる新しい一連の変数を生成します。
[学習] タブの [オプション] セクションで [PCA] を選択します。
[既定の PCA オプション] ダイアログ ボックスで、[主成分分析を有効化] チェック ボックスを選択して [保存して適用] をクリックします。
アプリにより、[モデル] ペインの既存のすべてのドラフト モデルに変更が適用され、[学習] タブの [モデル] セクションのギャラリーを使用して作成する新しいドラフト モデルにも適用されます。
次に [すべてを学習] ボタンを使用してモデルに学習させるとき、分類器に学習させる前に、選択した特徴量が関数
pcaによって変換されます。既定の設定では、PCA は分散の 95% を説明する成分のみを保持します。説明する分散の比率は、[既定の PCA オプション] ダイアログ ボックスの [説明分散] の値を選択して変更できます。値を大きくすると過適合のリスクが生じますが、値を小さくすると有用な次元が削除されるリスクが生じます。
PCA の成分数を手動で制限するには、[成分の削除基準] リストで
[成分数の指定]を選択します。[数値成分の数] の値を選択します。成分数を数値予測子の数より多くすることはできません。カテゴリカル予測子には PCA は適用されません。
学習済みモデルの PCA のオプションは、[概要] タブの [PCA] セクションで確認できます。[モデル] ペインで学習済みモデルをクリックし、(必要に応じて) モデルの [概要] タブをクリックします。以下に例を示します。
PCA is keeping enough components to explain 95% variance. After training, 2 components were kept. Explained variance per component (in order): 92.5%, 5.3%, 1.7%, 0.5%
分類学習器が PCA をデータに適用する方法についてさらに学ぶには、学習済みの分類器についてコードを生成します。PCA についての詳細は、関数 pca を参照してください。
平行座標プロットにおける特徴量の調査
追加または除外する特徴量を調べるには、平行座標プロットを使用します。高次元データを単一のプロットで可視化して 2 次元パターンを調べることができます。このプロットは、特徴量間の関係を理解し、クラスの分離に有用な予測子を識別するのに役立ちます。平行座標プロットでは、学習データと誤分類点を可視化できます。分類器の結果をプロットすると、誤分類点が破線になります。
[学習] タブの [プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [平行座標] をクリックします。
プロットの X 目盛りラベルをドラッグして予測子の順序を変更します。順序を変更すると、クラスを十分に分離する予測子を識別するために役立てることができます。
プロットする予測子を指定するには、[予測子] チェック ボックスを使用します。一度にプロットする予測子の数を少なくすることをお勧めします。データに多数の予測子が含まれている場合、既定の設定では最初の 10 個の予測子がプロットに表示されます。
これらの予測子のスケールが大きく異なる場合は、見やすくなるようにデータをスケーリングします。[スケーリング] リストのさまざまなオプションを試してください。
[なし]では、同じ下限と上限をもつ座標ルーラーに沿って生データが表示されます。[範囲]では、個別の下限と上限をもつ座標ルーラーに沿って生データが表示されます。[Z スコア]では、それぞれの座標ルーラーに沿って z スコア (平均値 0、標準偏差 1) が表示されます。[ゼロ平均]では、それぞれの座標ルーラーに沿って平均値が 0 になるようにセンタリングされたデータが表示されます。[単位分散]では、それぞれの座標ルーラーに沿って標準偏差でスケーリングされた値が表示されます。[L2 ノルム]では、それぞれの座標ルーラーに沿って L2 ノルム値が表示されます。
クラスの分離に役立たない予測子を識別した場合は、[特徴選択] を使用してその予測子を削除し、最も有用な予測子のみが含まれている分類器を学習させます。含める特徴量の選択を参照してください。
fisheriris のデータのプロットは、花弁の長さおよび花弁の幅がクラスの分離に最適な特徴であることを示します。

詳細については、parallelplot を参照してください。
アプリで作成した平行座標プロットを Figure にエクスポートできます。分類学習器アプリのプロットのエクスポートを参照してください。