fscmrmr
Minimum Redundancy Maximum Relevance (MRMR) アルゴリズムを使用した分類用の特徴量のランク付け
構文
説明
fscmrmr は、分類問題用の重要な予測子を識別するために MRMR アルゴリズムを使用して特徴量 (予測子) をランク付けします。
回帰用に MRMR に基づく特徴量のランク付けを実行するには、fsrmrmr を参照してください。
idx = fscmrmr(Tbl,ResponseVarName)idx を返します。table Tbl には予測子変数と応答変数が含まれ、ResponseVarName にクラス ラベルが格納されます。idx を使用して、分類問題用の重要な予測子を選択できます。
idx = fscmrmr(___,Name,Value)
例
標本データを読み込みます。
load ionosphere重要度に基づいて予測子をランク付けします。
[idx,scores] = fscmrmr(X,Y);
予測子の重要度スコアの棒グラフを作成します。
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score')
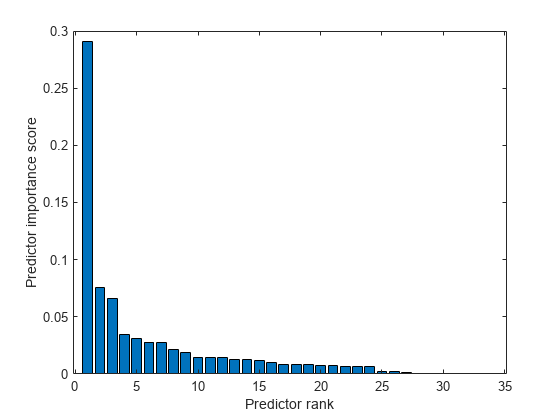
最も重要な予測子の 1 番目と 2 番目の間のスコアの下落は大きいですが、6 番目の予測子の後は比較的小さいです。重要度スコアの下落は、特徴選択の信頼度を表します。したがって、大きな下落は、ソフトウェアが確実に最も重要な予測子を選択していることを示します。小さな下落は、予測子の重要度の差が有意ではないことを示します。
上位 5 つの最も重要な予測子を選択します。X におけるこれらの予測子の列を求めます。
idx(1:5)
ans = 1×5
5 4 1 7 24
X の 5 列目が、Y の最も重要な予測子です。
fscmrmr を使用して重要な予測子を検出します。次に、testckfold を使用して、完全分類モデル (すべての予測子を使用する) と上位 5 つの重要な予測子を使用する次元削減されたモデルの精度を比較します。
census1994 データ セットを読み込みます。
load census1994census1994 内の table adultdata には、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データが含まれています。table の最初の 3 行を表示します。
head(adultdata,3)
age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
fscmrmr の出力引数には、関数によってランク付けされた変数のみが含まれます。table を関数に渡す前に、出力引数の順序が table の順序と一致するように、応答変数と重みなどのランク付けを行わない変数をテ table の最後に移動します。
table adultdata では、3 番目の列 fnlwgt はサンプルの重みで、最後の列 salary は応答変数です。関数 movevars を使用して fnlwgt を salary の左側に移動します。
adultdata = movevars(adultdata,'fnlwgt','before','salary'); head(adultdata,3)
age workClass education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country fnlwgt salary
___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______
39 State-gov Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States 77516 <=50K
50 Self-emp-not-inc Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States 83311 <=50K
38 Private HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States 2.1565e+05 <=50K
adultdata の予測子をランク付けします。列 salary を応答変数として指定します。
[idx,scores] = fscmrmr(adultdata,'salary','Weights','fnlwgt');
予測子の重要度スコアの棒グラフを作成します。予測子の名前を x 軸の目盛りラベルに使用します。
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score') xticklabels(strrep(adultdata.Properties.VariableNames(idx),'_','\_')) xtickangle(45)
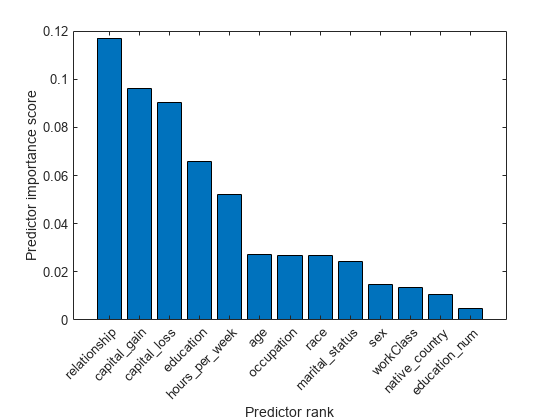
上位 5 つの重要な予測子は、relationship、capital_loss、capital_gain、education および hours_per_week です。
すべての予測子を使用して学習した分類木の精度を、上位 5 つの重要な予測子を使用して学習した分類木の精度と比較します。
既定のオプションを使用して、分類木テンプレートを作成します。
C = templateTree;
すべての予測子を含むように table tbl1 を定義し、上位 5 つの重要な予測子を含むように table tbl2 を定義します。
tbl1 = adultdata(:,adultdata.Properties.VariableNames(idx(1:13))); tbl2 = adultdata(:,adultdata.Properties.VariableNames(idx(1:5)));
分類木テンプレートと 2 つの table を関数testckfoldに渡します。関数は、反復交差検証により 2 つのモデルの精度を比較します。'Alternative','greater' を指定して、すべての予測子を使用するモデルの精度は、5 つの予測子を使用するモデルの精度と同程度であるという帰無仮説を検定します。'Test' が '5x2t' (5 行 2 列のペア t 検定) または '10x10t' (10 行 10 列の反復交差検証 t 検定) である場合、'greater' オプションを使用できます。
[h,p] = testckfold(C,C,tbl1,tbl2,adultdata.salary,'Weights',adultdata.fnlwgt,'Alternative','greater','Test','5x2t')
h = logical
0
p = 0.9970
h が 0 であり、p 値がほぼ 1 であるということは、帰無仮説が棄却できなかったことを示します。5 つの予測子を使用するモデルを使用しても、すべての予測子を使用するモデルと比較して、精度が失われる結果にはなりません。
これで、選択した予測子を使用して分類木を学習させます。
mdl = fitctree(adultdata,'salary ~ relationship + capital_loss + capital_gain + education + hours_per_week', ... 'Weights',adultdata.fnlwgt)
mdl =
ClassificationTree
PredictorNames: {'education' 'relationship' 'capital_gain' 'capital_loss' 'hours_per_week'}
ResponseName: 'salary'
CategoricalPredictors: [1 2]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
Properties, Methods
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
参照
[1] Ding, C., and H. Peng. "Minimum redundancy feature selection from microarray gene expression data." Journal of Bioinformatics and Computational Biology. Vol. 3, Number 2, 2005, pp. 185–205.
[2] Darbellay, G. A., and I. Vajda. "Estimation of the information by an adaptive partitioning of the observation space." IEEE Transactions on Information Theory. Vol. 45, Number 4, 1999, pp. 1315–1321.