fsrmrmr
構文
説明
fsrmrmr は、回帰問題用の重要な予測子を識別するために MRMR アルゴリズムを使用して特徴量 (予測子) をランク付けします。
分類用に MRMR に基づく特徴量のランク付けを実行するには、fscmrmr を参照してください。
idx = fsrmrmr(Tbl,ResponseVarName)idx を返します。table Tbl には予測子変数と応答変数が含まれ、ResponseVarName に応答値が格納されます。idx を使用して、回帰問題のための重要な予測子を選択できます。
idx = fsrmrmr(___,Name=Value)
例
モデル から 1000 個の観測値をシミュレートします。
は、標準正規の要素の 1000 行 10 列の行列です。
"e" は、平均が 0、標準偏差が 0.3 のランダムな正規誤差のベクトルです。
rng("default") % For reproducibility X = randn(1000,10); Y = X(:,4) + 2*X(:,7) + 0.3*randn(1000,1);
重要度に基づいて予測子をランク付けします。
idx = fsrmrmr(X,Y);
上位 2 つの最も重要な予測子を選択します。
idx(1:2)
ans = 1×2
7 4
関数により、X の 7 列目と 4 列目が Y の最も重要な予測子として識別されます。
carbig データ セットを読み込み、さまざまな変数が含まれている table を作成します。応答変数 MPG を table の最後の変数として含めます。
load carbig cartable = table(Acceleration,Cylinders,Displacement, ... Horsepower,Model_Year,Weight,Origin,MPG);
重要度に基づいて予測子をランク付けします。応答変数を指定します。
[idx,scores] = fsrmrmr(cartable,"MPG");メモ: fsrmrmr が table 内の変数のサブセットを予測子として使用する場合、関数は予測子のサブセットのみにインデックスを作成します。関数でランク付けされない変数 (応答変数も含む) は、返されるインデックスでカウントされません。
予測子の重要度スコアの棒グラフを作成します。予測子の名前を x 軸の目盛りラベルに使用します。
bar(scores(idx)) xlabel("Predictor rank") ylabel("Predictor importance score") predictorNames = cartable.Properties.VariableNames(1:end-1); xticklabels(strrep(predictorNames(idx),"_","\_")) xtickangle(45)
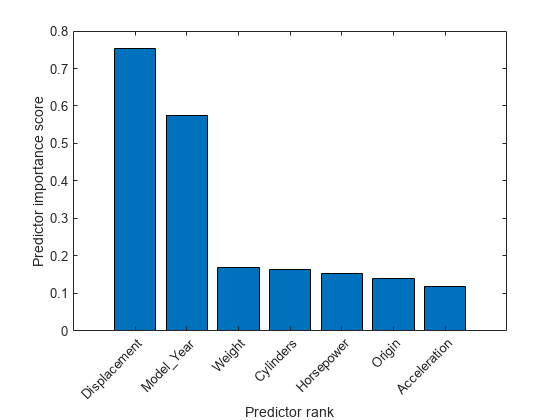
最も重要な予測子の 2 番目と 3 番目の間のスコアの下落は大きいですが、3 番目の予測子の後は比較的小さい下落になっています。重要度スコアの下落は、特徴選択の信頼度を表します。したがって、最も重要な予測子の選択においては、大きな下落は、ソフトウェアが確実に 2 番目の最も重要な予測子を選択していることを示します。小さな下落は、予測子の重要度の差が有意ではないことを示します。
上位 2 つの最も重要な予測子を選択します。
idx(1:2)
ans = 1×2
3 5
cartable の 3 列目が MPG の最も重要な予測子です。cartable の 5 列目が MPG の 2 番目に最も重要な予測子です。
回帰モデルの性能を改善するために、genrfeatures を使用して新しい特徴量を生成し、fsrmrmr を使用して最も重要な予測子を選択します。元の特徴量だけを使用して学習させたモデルのテスト セット性能と最も重要な生成された特徴量を使用して学習させたモデルの性能を比較します。
停電のデータをワークスペースに table として読み込みます。欠損値がある観測値を削除し、table の最初の数行を表示します。
outages = readtable("outages.csv");
Tbl = rmmissing(outages);
head(Tbl) Region OutageTime Loss Customers RestorationTime Cause
_____________ ________________ ______ __________ ________________ ___________________
{'SouthWest'} 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 {'winter storm' }
{'SouthEast'} 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 {'winter storm' }
{'West' } 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 {'equipment fault'}
{'MidWest' } 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 {'severe storm' }
{'West' } 2003-06-18 02:49 0 0 2003-06-18 10:54 {'attack' }
{'NorthEast'} 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 {'fire' }
{'MidWest' } 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 {'equipment fault'}
{'SouthEast'} 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 {'equipment fault'}
変数の中には、OutageTime や RestorationTime など、fitrensemble のような回帰モデル学習関数でサポートされないデータ型の変数も含まれています。
cvpartitionを使用して、データ セットを学習セットとテスト セットに分割します。観測値の約 70% を学習データとして使用し、それ以外の約 30% をテスト データとして使用します。
rng("default") % For reproducibility of the data partition c = cvpartition(length(Tbl.Loss),"Holdout",0.30); trainTbl = Tbl(training(c),:); testTbl = Tbl(test(c),:);
関数 isoutlier を使用して、学習データから Customers の外れ値を特定して削除します。
[customersIdx,customersL,customersU] = isoutlier(trainTbl.Customers); trainTbl(customersIdx,:) = [];
学習データの計算で使用したのと同じ下限および上限のしきい値を使用して、テスト データから Customers の外れ値を削除します。
testTbl(testTbl.Customers < customersL | testTbl.Customers > customersU,:) = [];
trainTbl 内の予測子から、バギング アンサンブルの学習に使用できる特徴量を 35 個生成します。応答として変数 Loss を指定し、特徴選択手法として MRMR を指定します。
[Transformer,newTrainTbl] = genrfeatures(trainTbl,"Loss",35, ... TargetLearner="bag",FeatureSelectionMethod="mrmr");
返される table newTrainTbl には、各種の設計された特徴量が含まれます。newTrainTbl の最初の 3 列は関数 fitrensemble を使用して回帰モデルの学習に使用できる trainTbl の元の特徴量で、newTrainTbl の残りの列は応答変数 Loss です。
originalIdx = 1:3; head(newTrainTbl(:,[originalIdx end]))
c(Region) Customers c(Cause) Loss
_________ __________ _______________ ______
SouthEast 1.4294e+05 winter storm 289.4
West 3.4037e+05 equipment fault 434.81
MidWest 2.1275e+05 severe storm 186.44
West 0 attack 0
MidWest 66104 equipment fault 286.72
SouthEast 36073 equipment fault 73.387
SouthEast 1.0698e+05 winter storm 46.918
NorthEast 1.0444e+05 winter storm 255.45
newTrainTbl の予測子をランク付けします。応答変数を指定します。
[idx,scores] = fsrmrmr(newTrainTbl,"Loss");メモ: fsrmrmr が table 内の変数のサブセットを予測子として使用する場合、関数はサブセットのみにインデックスを作成します。関数でランク付けされない変数 (応答変数も含む) は、返されるインデックスでカウントされません。
予測子の重要度スコアの棒グラフを作成します。
bar(scores(idx)) xlabel("Predictor rank") ylabel("Predictor importance score")
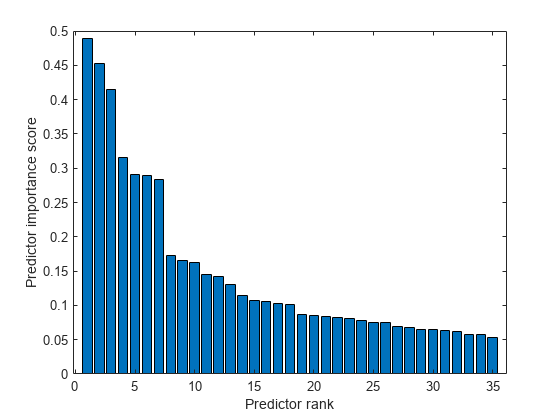
7 番目と 8 番目の最も重要な予測子のスコア間に大きなギャップがあるため、7 個の最も重要な特徴量を選択してバギング アンサンブル モデルに学習させます。
importantIdx = idx(1:7); fsMdl = fitrensemble(newTrainTbl(:,importantIdx),newTrainTbl.Loss, ... Method="Bag");
比較のために、モデルの学習に使用できる 3 つの元の予測子を使用して別のバギング アンサンブル モデルに学習させます。
originalMdl = fitrensemble(newTrainTbl(:,originalIdx),newTrainTbl.Loss, ... Method="Bag");
テスト データ セットを変換します。
newTestTbl = transform(Transformer,testTbl);
2 つの回帰モデルのテストの平均二乗誤差 (MSE) を計算します。
fsMSE = loss(fsMdl,newTestTbl(:,importantIdx), ...
newTestTbl.Loss)fsMSE = 1.0867e+06
originalMSE = loss(originalMdl,newTestTbl(:,originalIdx), ...
newTestTbl.Loss)originalMSE = 1.0961e+06
fsMSE が originalMSE より小さくなっており、最も重要な生成された特徴量で学習させたバギング アンサンブルの方が元の特徴量で学習させたバギング アンサンブルよりも性能がわずかに高くなっていることを示しています。
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
参照
[1] Ding, C., and H. Peng. "Minimum redundancy feature selection from microarray gene expression data." Journal of Bioinformatics and Computational Biology. Vol. 3, Number 2, 2005, pp. 185–205.
[2] Darbellay, G. A., and I. Vajda. "Estimation of the information by an adaptive partitioning of the observation space." IEEE Transactions on Information Theory. Vol. 45, Number 4, 1999, pp. 1315–1321.
バージョン履歴
R2022a で導入