parallelplot
平行座標プロットを作成

構文
説明
parallelplot( は、table tbl)tbl から平行座標プロットを作成します。プロット内の各ラインは table 内の 1 行を表し、プロット内の各座標変数は table 内の 1 列に対応します。ソフトウェアは table のすべての列を既定でプロットします。
parallelplot(___, は、1 つ以上の名前と値のペアの引数を使用して追加のオプションを指定します。たとえば、数値を伴う座標のデータ正規化方式を指定できます。プロパティの一覧については、ParallelCoordinatesPlot のプロパティ を参照してください。Name,Value)
parallelplot( は、parent,___)parent で指定された Figure、パネル、またはタブに平行座標プロットを作成します。
p = parallelplot(___)ParallelCoordinatesPlot オブジェクトを返します。作成後にオブジェクトを変更するには、p を使用します。プロパティの一覧については、ParallelCoordinatesPlot のプロパティ を参照してください。
例
医療患者データの table から平行座標プロットを作成します。
patients データセットを読み込み、ワークスペースに読み込んだ変数のサブセットから table を作成します。table を使用して平行座標プロットを作成します。プロット内のラインは個々の患者に対応します。プロットを使用して、データのトレンドを観察します。たとえば、プロットは、喫煙者の血圧値が高くなる傾向があることを示しています (最低血圧と最高血圧の両方)。
load patients
tbl = table(Diastolic,Smoker,Systolic);
p = parallelplot(tbl)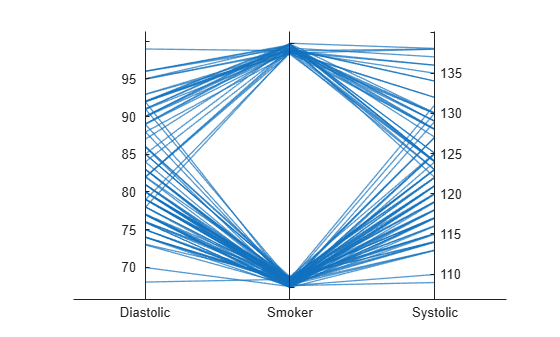
p =
ParallelCoordinatesPlot with properties:
SourceTable: [100×3 table]
CoordinateVariables: {'Diastolic' 'Smoker' 'Systolic'}
GroupVariable: ''
Show all properties
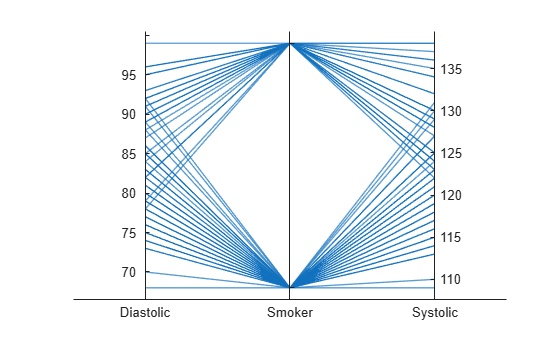
既定では、ソフトウェアはプロット ラインにランダムに微変動を起こし、座標ルーラーに沿って完全にオーバーラップすることがないようにします。プロット ラインをより簡単に区別できるようになるため、このジッターは categorical データを可視化するのに特に役立ちます。たとえば、Smoker 座標ルーラーに沿ってプロット ラインを観察すると、プロット ラインは true または false のいずれかの目盛りで重なっていません。
既定のジッターを無効にするには、Jitter プロパティを 0 に設定します。
p.Jitter = 0;
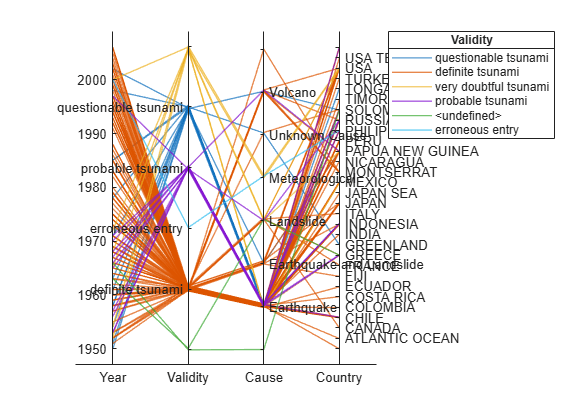
津波データの table から平行座標プロットを作成します。表示する table 変数とその順序を指定し、いずれかの変数に従ってプロット内のラインをグループ化します。
津波データをワークスペースに table として読み取ります。
tsunamis = readtable('tsunamis.xlsx');table 内の変数のサブセットを使用して平行座標プロットを作成します。最初に、プロットでの過密状態を回避するために Figure ウィンドウのサイズを大きくします。次に、変数とその順序を指定するために、名前と値のペアの引数 'CoordinateVariables' を使用します。有効性に従って発生をグループ化するには、名前と値のペアの引数 'GroupVariable' を 'Validity' に設定します。プロット内のラインは個々の津波の発生に対応します。プロットは、Validity 値をもつデータセット内の発生のほとんどが明らかな津波と考えられることを示しています。
figure('Units','normalized','Position',[0.3 0.3 0.45 0.4]) coordvars = {'Year','Validity','Cause','Country'}; p = parallelplot(tsunamis,'CoordinateVariables',coordvars,'GroupVariable','Validity');
医療患者データを含んでいる行列から平行座標プロットを作成します。行列内のいずれかの列にある値をビン化し、ビン化された値を使用してプロット内のラインをグループ化します。
patients データセットを読み込み、Age、Height、および Weight の値から行列を作成します。行列データを使用して平行座標プロットを作成します。プロットの座標変数にラベルを付けます。プロット内のラインは個々の患者に対応します。
load patients
X = [Age Height Weight];
p = parallelplot(X)p =
ParallelCoordinatesPlot with properties:
Data: [100×3 double]
CoordinateData: [1 2 3]
GroupData: []
Show all properties
p.CoordinateTickLabels = {'Age (years)','Height (inches)','Weight (pounds)'};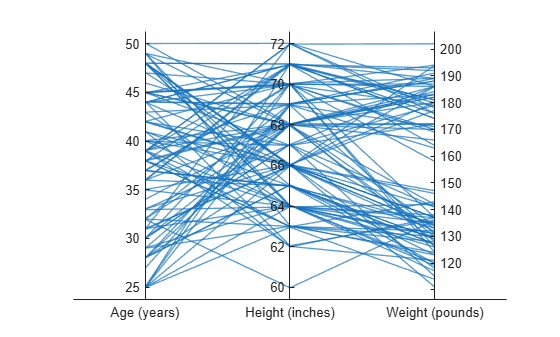
各患者を 3 つのカテゴリ (short、average、または tall) のうちの 1 つにグループ化する新しい categorical 変数を作成します。Height の最小値と最大値が含まれるようにビンのエッジを設定します。
min(Height)
ans = 60
max(Height)
ans = 72
binEdges = [60 64 68 72];
bins = {'short','average','tall'};
groupHeight = discretize(Height,binEdges,'categorical',bins);ここで、groupHeight 値を使用して、平行座標プロットのラインをグループ化します。プロットは、short 患者の方が tall 患者よりも体重が軽い傾向があることを示しています。
p.GroupData = groupHeight;
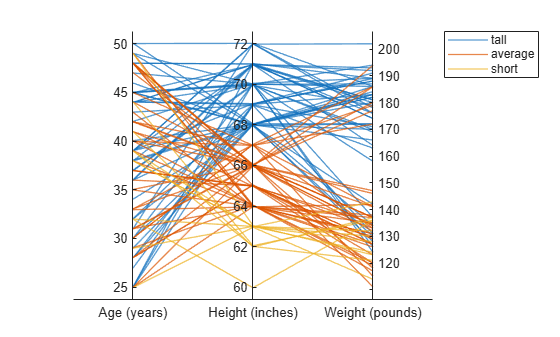
医療患者データが含まれている行列から平行座標プロットを作成します。各プロットで、表示する行列の列を指定し、個別の変数に従ってプロット内のラインをグループ化します。
patients データセットを読み込み、ワークスペースに読み込んだ一部の変数から行列を作成します。
load patients
X = [Age Height Weight];行列 X の列のサブセットを使用して、平行座標プロットを作成します。列とその順序を指定するには、名前と値のペアの引数 'CoordinateData' を使用します。Smoker 値を名前と値のペアの引数 'GroupData' に渡すことで、喫煙状況に従って患者をグループ化します。プロット内のラインは個々の患者に対応します。プロットは、喫煙状況と年齢または体重のいずれかの間に明白な関連がないことを示しています。
coorddata = [1 3]; p = parallelplot(X,'CoordinateData',coorddata,'GroupData',Smoker)
p =
ParallelCoordinatesPlot with properties:
Data: [100×3 double]
CoordinateData: [1 3]
GroupData: [100×1 logical]
Show all properties
p.CoordinateTickLabels = {'Age','Weight'};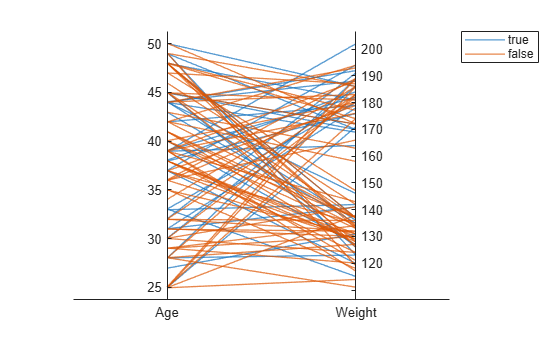
X の列の異なるサブセットを使用して、別の平行座標プロットを作成します。性別に従って患者をグループ化します。プロットは、女性よりも男性の方が背が高く、体重が重いことを示しています。
coorddata2 = [2 3]; p2 = parallelplot(X,'CoordinateData',coorddata2,'GroupData',Gender)
p2 =
ParallelCoordinatesPlot with properties:
Data: [100×3 double]
CoordinateData: [2 3]
GroupData: {100×1 cell}
Show all properties
p2.CoordinateTickLabels = {'Height','Weight'};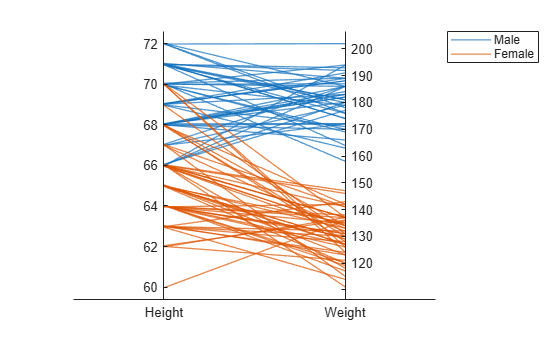
停電データの table から平行座標プロットを作成します。数値の座標変数の正規化方式を変更します。
停電データをワークスペースに table として読み取ります。table の最初の数行を表示します。
outages = readtable('outages.csv');
head(outages) Region OutageTime Loss Customers RestorationTime Cause
_____________ ________________ ______ __________ ________________ ___________________
{'SouthWest'} 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 {'winter storm' }
{'SouthEast'} 2003-01-23 00:49 530.14 2.1204e+05 NaT {'winter storm' }
{'SouthEast'} 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 {'winter storm' }
{'West' } 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 {'equipment fault'}
{'MidWest' } 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 {'severe storm' }
{'West' } 2003-06-18 02:49 0 0 2003-06-18 10:54 {'attack' }
{'West' } 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 {'equipment fault'}
{'West' } 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 {'equipment fault'}
各停電がどれくらい続いたかを示す OutageDuration と呼ばれる新しい変数を作成します。OutageDuration を各停電の継続日数に変換します。新しい変数を outages table に追加し、それを OutageDays と呼びます。
OutageDuration = outages.RestorationTime - outages.OutageTime; outages.OutageDays = days(OutageDuration);
変数 Loss、変数 Customers、変数 OutageDays を使用して、平行座標プロットを作成します。座標変数は数値であるため、名前と値のペアの引数 'DataNormalization' と 'Jitter' を使用して、値をジッターなしで z スコアとしてプロットに表示します。
coordvars = {'Loss','Customers','OutageDays'};
p = parallelplot(outages,'CoordinateVariables',coordvars,'DataNormalization','zscore','Jitter',0);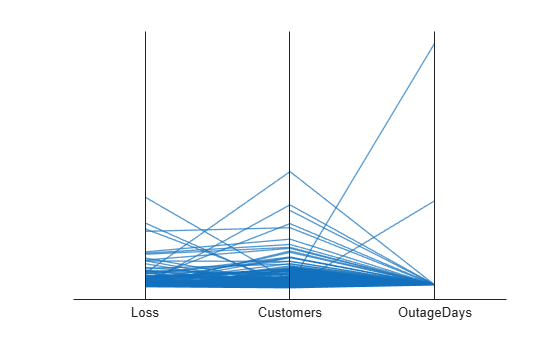
変数 OutageDays には、平均値 OutageDays から少なくとも標準偏差の 30 倍分離れた 1 つの値と、平均値から少なくとも標準偏差の 10 倍分離れたもう 1 つの値が含まれています。プロットの値にカーソルを合わせて、データ ヒントを表示します。各データ ヒントは、プロット内のラインに対応する table 内の行を示しています。
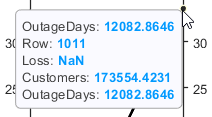
特定された極端な OutageDays 値をもつ行を outages table 内で見つけます。これら 2 つの停電の RestorationTime 値は疑わしいものであることに注意してください。
outliers = outages([1011 269],:)
outliers=2×7 table
Region OutageTime Loss Customers RestorationTime Cause OutageDays
_____________ ________________ ______ __________ ________________ ____________________ __________
{'NorthEast'} 2009-08-20 02:46 NaN 1.7355e+05 2042-09-18 23:31 {'severe storm' } 12083
{'MidWest' } 2008-02-07 06:18 2378.7 0 2019-08-14 16:16 {'energy emergency'} 4206.4
平行座標プロットを作成します。座標変数のいずれかのカテゴリを並べ替えます。
停電に関するデータを table としてワークスペースに読み取ります。
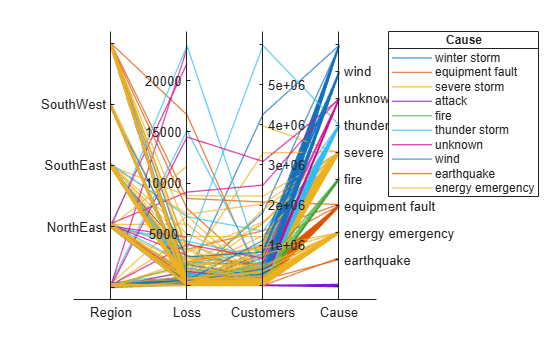
outages = readtable('outages.csv');table 内の列のサブセットを使用して、平行座標プロットを作成します。停電の原因となったイベントに従って、プロット内のラインをグループ化します。
coordvars = [1 3 4 6]; p = parallelplot(outages,'CoordinateVariables',coordvars,'GroupVariable','Cause');
ソース table を更新することで、Cause でのイベントの順序を変更します。最初に、Cause を変数 categorical に変換し、イベントの新しい順序を指定し、関数 reordercats を使用して orderCause と呼ばれる新しい変数を作成します。次に、プロットのソース table において、元の変数 Cause を新しい変数 orderCause で置き換えます。
categoricalCause = categorical(p.SourceTable.Cause);
newOrder = {'attack','earthquake','energy emergency','equipment fault', ...
'fire','severe storm','thunder storm','wind','winter storm','unknown'};
orderCause = reordercats(categoricalCause,newOrder);
p.SourceTable.Cause = orderCause;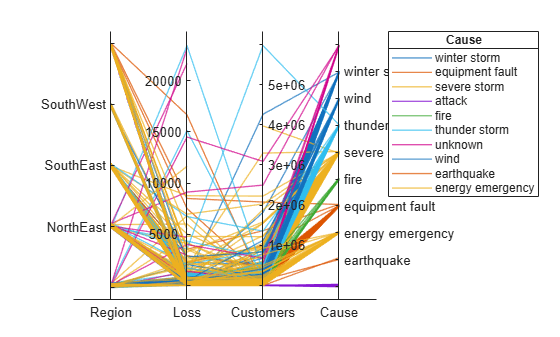
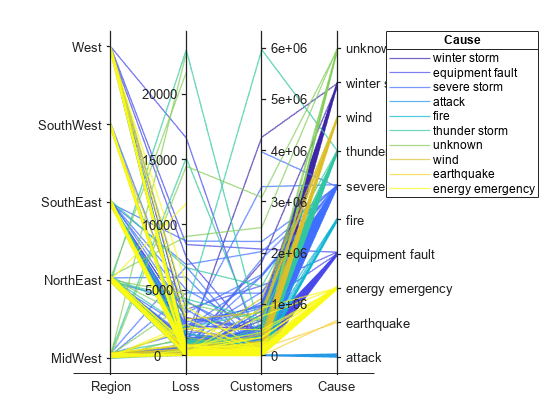
変数 Cause に含まれるカテゴリ数は 7 個より多いため、グループのうちの一部はプロットで同じ色をもちます。すべてのグループに個別の色を割り当てるには、p の Color プロパティを変更します。
p.Color = parula(10);
入力引数
名前と値の引数
オプションの引数のペアを Name1=Value1,...,NameN=ValueN として指定します。ここで、Name は引数名で、Value は対応する値です。名前と値の引数は他の引数の後に指定しなければなりませんが、ペアの順序は重要ではありません。
R2021a より前では、コンマを使用して名前と値をそれぞれ区切り、Name を引用符で囲みます。
例: parallelplot(data,'GroupData',grpdata,'DataNormalization','zscore','Jitter',0) は、grpdata を使用して data の数値データをグループ化し、ジッターなしでデータを z スコアとして表示することを指定します。
プロットのタイトル。文字ベクトル、string 配列、文字ベクトルの cell 配列、または categorical 配列として指定します。既定では、プロットにはタイトルがありません。
複数行のタイトルを作成するには、string 配列または文字ベクトルの cell 配列を指定します。配列の各要素は、テキストの行に対応します。
タイトルを categorical 配列として指定した場合、MATLAB® はカテゴリではなく、配列内の値を使用します。
例: p = parallelplot(__,'Title','My Title Text')
例: p.Title = 'My Title Text'
例: p.Title = {'My','Title'}
数値を使用した座標の正規化方式。次のいずれかのオプションとして指定します。
| 方式 | 説明 |
|---|---|
'range' | 独立した下限と上限をもつ座標ルーラーに沿って生データを表示 |
'none' | 同じ下限と上限をもつ座標ルーラーに沿って生データを表示 |
'zscore' | z スコア (平均は 0、標準偏差は 1) を各座標ルーラーに沿って表示 |
'scale' | 標準偏差によってスケーリングされた値を各座標ルーラーに沿って表示 |
'center' | 平均が 0 になるように中心に置かれたデータを各座標ルーラーに沿って表示 |
'norm' | 2 ノルム値を各座標ルーラーに沿って表示 |
これらの方式の詳細については、normalize を参照してください。
logical ベクトル、datetime 配列、duration 配列、categorical 配列、string 配列、または文字ベクトルの cell 配列である座標変数の場合、関数 parallelplot は正規化方式に関係なく、取り得る一意の値を座標ルーラーに沿って均等に分散します。
例: p = parallelplot(__,'DataNormalization','none')
例: p.DataNormalization = 'zscore'
座標ルーラーに沿ったデータ変位距離。区間 [0,1] 内の数値スカラーとして指定します。Jitter 値により、座標ルーラーに沿ってプロット ラインを true 値から変位させる最大距離が決まります。ここで、変位は一様乱数の量です。Jitter プロパティを 1 に設定する場合、隣接するジッター領域がちょうど触れ合います。実際のデータ値を表示するには、Jitter プロパティを 0 に設定します。
ジッターによってプロット ライン間をより簡単に区別できるため、ある程度のジッターは categorical データを可視化するのに特に役立ちます。ただし、Jitter 値は数値変数を含むすべての座標変数に影響を与えます。
例: p = parallelplot(__,'Jitter',0.5)
例: p.Jitter = 0.2
グループの色。次のいずれかの形式で指定します。
色名、省略名、または 16 進数カラー コードを示す文字ベクトル。16 進数カラー コードはハッシュ記号 (
#) で開始し、0~Fの範囲で 3 桁または 6 桁の 16 進数が続きます。この値は大文字と小文字を区別しません。したがって、カラー コード'#FF8800'、'#ff8800'、'#F80'、および'#f80'は等価です。1 つ以上の色の名前、省略名、または 16 進数カラー コードを示す string 配列または文字ベクトルの cell 配列。
範囲 [0,1] の RGB 値から成る 3 列の行列。3 つの列は R 値、G 値、および B 値を表す。
事前定義されたこれらの色、等価の RGB 3 成分、およびその 16 進数カラー コードから選択します。
| 色名 | 省略名 | RGB 3 成分 | 16 進数カラー コード | 外観 |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan" | "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|








次の表に、ライト テーマとダーク テーマでのプロットの既定のカラー パレットを示します。
| パレット | パレットの色 |
|---|---|
R2025a より前: ほとんどのプロットで、これらの色が既定で使用されます。 |
|
|
|


orderedcolors 関数と rgb2hex 関数を使用すると、これらのパレットの RGB 3 成分および 16 進数カラー コードを取得できます。たとえば、"gem" パレットの RGB 3 成分を取得し、16 進数カラー コードに変換します。
RGB = orderedcolors("gem");
H = rgb2hex(RGB);R2023b より前: RGB = get(groot,"FactoryAxesColorOrder") を使用して、RGB 3 成分を取得します。
R2024a より前: H = compose("#%02X%02X%02X",round(RGB*255)) を使用して、16 進数カラー コードを取得します。
既定では、parallelplot は最大 7 つの固有のグループ色を割り当てます。グループの合計数が指定された色の数を超えると、parallelplot は指定された色を先頭から順番に繰り返し使用します。
例: p = parallelplot(__,'Color',{'blue','black','green'})
例: p.Color = [0 0 1; 0 0.5 0.5; 0.5 0.5 0.5]
例: p.Color = {'#EDB120','#77AC30','#7E2F8E'}
出力引数
詳細
ヒント
ParallelCoordinatesPlotオブジェクトでデータを対話的に調べるには、次のオプションを使用します (一部はライブ エディターで使用できません)。ズーム — スクロール ホイールを使用してズームする。
パン — 平行座標プロットをクリックしてドラッグすることで移動する。
データ ヒント — 平行座標プロットにカーソルを合わせてデータ ヒントを表示する。ソフトウェアによってプロット内の対応するラインが強調表示されます。例については、プロットでのデータ正規化の変更を参照してください。
座標の再配置 — 座標の目盛りラベルをクリックして水平方向にドラッグし、対応する座標ルーラーを別の位置に移動する。例については、平行座標プロットを使用した table データの参照を参照してください。
table から平行座標プロットを作成する場合、データ ヒントをカスタマイズできます。平行座標プロットのデータ ヒントには、すべての行を削除した場合でも、選択した点の値が常に表示されます。
データ ヒントの行を追加または削除するには、プロットの任意の場所を右クリックして [データ ヒントの変更] をポイントします。次に、変数を選択または選択解除します。
複数の行を追加または削除するには、プロット上で右クリックして [データ ヒントの変更] をポイントし、[詳細] を選択します。次に、[>>] をクリックして変数を追加するか、[<<] をクリックして変数を削除します。
バージョン履歴
R2019a で導入