table 内のデータへのアクセス
table は、列方向のデータを変数に格納するコンテナーです。table 内のデータにアクセスするために、行列で行と列を指定してインデックスを付けるのと同じように、table でも行と変数を指定してインデックスを付けることができます。構造体のフィールドに名前があるのと同様に、table 変数にも名前があります。table の行も名前をもつことができますが、行名は必須ではありません。table にインデックスを付けるには、位置、名前、またはデータ型のいずれかを使用して行と変数を指定します。結果は配列または table のいずれかになります。
このトピックでは、さまざまな table インデックス構文と各タイプの使用目的について説明します。さらに、それらの table インデックス タイプを適用するさまざまな方法を示す例も紹介します。トピックの最後の表に、インデックス構文、行と変数の指定方法、結果として得られる出力をまとめてあります。
table インデックス構文
使用するインデックスのタイプに応じて、結果は table から抽出された配列か新しい table のいずれかになります。次を使ってインデックスを付けます。
ドット表記。
T.またはvarnameT.(の形式で、1 つの table 変数から配列を抽出します。expression)中かっこ。
T{の形式で、指定した行と変数から配列を抽出します。変数は 1 つの配列に連結できるように、互換性のあるデータ型でなければなりません。rows,vars}小かっこ。
T(の形式で、指定した行と変数のみをもつ table を返します。rows,vars)
次の図は、table インデックスの 3 つのタイプを示しています。
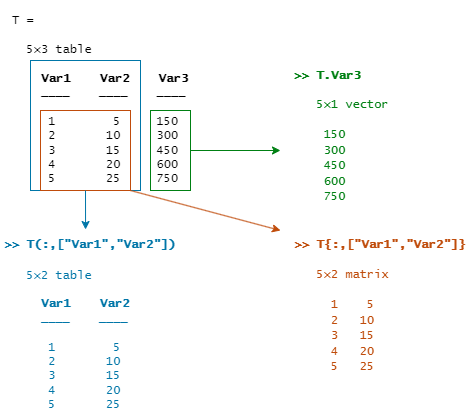
推奨されるインデックス構文
table の内容にアクセスするための推奨される方法は、目的の結果と指定する変数の数によって異なります。以下の構文の例で使用している T は、Var1、Var2、Var3 という名前の変数をもつ table です。(これらの名前は、関数 table を呼び出すときに変数名を指定しない場合の既定の名前です。)
T = table([1;2;3;4;5],[5;10;15;20;25],[150;300;450;600;750])
1 つの table 変数にアクセスするにはドット表記を使用する。変数名を指定するか、変数の名前または位置に一致する式を指定します。
リテラルの変数名を使用する方が式を使用するよりも高速です。たとえば、
T.Var1とT.(1)はどちらもTの最初の変数にアクセスしますが、式を使用する方が遅くなります。X = T.Var1 Y = T.Var1(1:3) Z = T.(1) T.Var1 = T.Var1 .* 10
中かっこを使用して 1 つの変数を指定することもできます。ただし、ドット表記を使用して変数にアクセスする方が中かっこを使用して変数にアクセスするよりも高速です。
複数の table 変数にアクセスするには中かっこを使用する。
X = T{:,["Var1" "Var2"]} Y = T{1:3,["Var1" "Var2"]} T{:,["Var1" "Var2"]} = T{:,["Var1" "Var2"]} .* 10指定した行と変数のみをもつ table を返すには小かっこを使用する。
T2 = T(:,["Var1" "Var2"]) T2 = T(1:3,["Var1" "Var2"]) A = rand(5,1) B = rand(5,1) T(:,["Var1" "Var2"]) = table(A,B)
行と変数の指定によるインデックス付け
数値インデックス、行名と変数名、または変数のデータ型を指定して table にインデックスを付けることができます。
table を作成します。サンプル ファイル patients.mat からデータの配列を読み込みます。その後、関数 table を使用して、それらの配列から table を作成します。入力配列の名前が table 変数の名前になります。行名はオプションです。行名を指定するには、名前と値の引数 RowNames を使用します。
load patients.mat Age Height Weight Smoker LastName T = table(Age,Height,Weight,Smoker,RowNames=LastName)
T=100×4 table
Age Height Weight Smoker
___ ______ ______ ______
Smith 38 71 176 true
Johnson 43 69 163 false
Williams 38 64 131 false
Jones 40 67 133 false
Brown 49 64 119 false
Davis 46 68 142 false
Miller 33 64 142 true
Wilson 40 68 180 false
Moore 28 68 183 false
Taylor 31 66 132 false
Anderson 45 68 128 false
Thomas 42 66 137 false
Jackson 25 71 174 false
White 39 72 202 true
Harris 36 65 129 false
Martin 48 71 181 true
⋮
位置によるインデックス付け
位置を数値インデックスとして指定することで table にインデックスを付けることができます。コロンや end キーワードも使用できます。
たとえば、T の最初の 3 行にインデックスを付けます。この構文は、指定した数の行をもつ table を返すためのコンパクトな方法です。
firstRows = T(1:3,:)
firstRows=3×4 table
Age Height Weight Smoker
___ ______ ______ ______
Smith 38 71 176 true
Johnson 43 69 163 false
Williams 38 64 131 false
T の最初の 2 つの変数と最後の 3 行をもつ table を返します。
lastRows = T(end-2:end,1:2)
lastRows=3×2 table
Age Height
___ ______
Griffin 49 70
Diaz 45 68
Hayes 48 66
変数のデータ型に互換性がある場合は、中かっこを使用して抽出データを配列として返すことができます。
lastRowsAsArray = T{end-2:end,1:2}lastRowsAsArray = 3×2
49 70
45 68
48 66
変数名によるインデックス付け
string 配列を使用して変数名を指定することで table にインデックスを付けることができます。table 変数の名前は、有効な MATLAB® 識別子である必要はありません。スペースや非 ASCII 文字を含めることができ、任意の文字で開始できます。
たとえば、T の最初の 3 行と変数 Height および Weight のみをもつ table を返します。
variablesByName = T(1:3,["Height" "Weight"])
variablesByName=3×2 table
Height Weight
______ ______
Smith 71 176
Johnson 69 163
Williams 64 131
中かっこを使用してデータを配列として返します。
arraysFromVariables = T{1:3,["Height" "Weight"]}arraysFromVariables = 3×2
71 176
69 163
64 131
ドット表記を使用して 1 つの変数にインデックスを付けることもできます。実際、アクセスする変数が 1 つだけの場合はドット表記の方が効率的です。
heightAsArray = T.Height
heightAsArray = 100×1
71
69
64
67
64
68
64
68
68
66
68
66
71
72
65
⋮
ドット表記を使用して、変数 Height の最初の 3 行を配列として返します。
firstHeights = T.Height(1:3)
firstHeights = 3×1
71
69
64
行名によるインデックス付け
table に行名がある場合は、行番号だけでなく、行名でインデックスを付けることができます。たとえば、3 人の特定の患者に対応する T の行を返します。
rowsByName = T(["Griffin" "Diaz" "Hayes"],:)
rowsByName=3×4 table
Age Height Weight Smoker
___ ______ ______ ______
Griffin 49 70 186 false
Diaz 45 68 172 true
Hayes 48 66 177 false
中かっこを使用してデータを配列として返すこともできます。
arraysFromRows = T{["Griffin" "Diaz" "Hayes"],:}arraysFromRows = 3×4
49 70 186 0
45 68 172 1
48 66 177 0
1 つの要素へのインデックス付け
table の 1 つの要素にインデックスを付けるには、1 つの行と 1 つの変数を指定します。中かっこを使用して要素を配列として返します。この場合はスカラー値です。
oneElement = T{"Diaz","Height"}oneElement = 68
その要素を 1 つの行と 1 つの変数をもつ table として返すには、小かっこを使用します。
oneElementTable = T("Diaz","Height")
oneElementTable=table
Height
______
Diaz 68
変数のデータ型によるインデックス付け
同じデータ型をもつ変数を指定して table にインデックスを付けるには、関数 vartype を使用してデータ型添字を作成します。
たとえば、数値の table 変数に対応するデータ型添字を作成します。
numSubscript = vartype("numeric")numSubscript = table vartype subscript: Select table variables matching the type 'numeric' See Access Data in a Table.
T の数値変数のみをもつ table を返します。変数 Smoker は logical 変数であるため含まれません。
onlyNumVariables = T(:,numSubscript)
onlyNumVariables=100×3 table
Age Height Weight
___ ______ ______
Smith 38 71 176
Johnson 43 69 163
Williams 38 64 131
Jones 40 67 133
Brown 49 64 119
Davis 46 68 142
Miller 33 64 142
Wilson 40 68 180
Moore 28 68 183
Taylor 31 66 132
Anderson 45 68 128
Thomas 42 66 137
Jackson 25 71 174
White 39 72 202
Harris 36 65 129
Martin 48 71 181
⋮
table への値の代入
任意のインデックス構文を使用して table に値を代入できます。変数、行、または個々の要素に値を代入することができます。
変数への値の代入
関数 readtable を使用して、停電データをスプレッドシートから table にインポートします。
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
1 つの変数に値を代入するには、ドット表記を使用します。たとえば、変数 Loss を 100 倍にスケーリングします。
outages.Loss = outages.Loss .* 100
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 45898 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 53014 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 28940 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 43481 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 18644 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 23129 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 31186 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 23993 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 28672 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 7338.7 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 15999 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 9591.7 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 25409 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
中かっこを使用して複数の変数にデータを代入することもできます。変数は互換性のあるデータ型でなければなりません。たとえば、Loss と Customers を 1/10,000 倍 にスケーリングします。
outages{:,["Loss" "Customers"]} = outages{:,["Loss" "Customers"]} ./ 10000outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ _______ _________ ________________ _________________
"SouthWest" 2002-02-01 12:18 4.5898 182.02 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 5.3014 21.204 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 2.894 14.294 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 4.3481 34.037 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 1.8644 21.275 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 2.3129 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 3.1186 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 2.3993 4.9434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 2.8672 6.6104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 0.73387 3.6073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 1.5999 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 0.95917 3.6759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 35.517 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 2.5409 92.429 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
行への値の代入
table に 1 つの行を代入するには、1 行の table か cell 配列のいずれかを使用できます。この場合は、1 行の table を作成して代入するよりも cell 配列を使用する方が便利なことがあります。
たとえば、outages の末尾の新しい行にデータを代入します。table の末尾を表示します。
outages(end+1,:) = {"East",datetime("now"),17.3,325,datetime("tomorrow"),"unknown"};
outages(end-2:end,:)ans=3×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ________ _________ ________________ _________________
"SouthEast" 2013-12-20 19:52 0.023096 0.10382 2013-12-20 23:29 "thunder storm"
"SouthEast" 2011-09-14 11:55 0.45042 1.1835 2011-09-14 13:28 "equipment fault"
"East" 2026-01-24 22:19 17.3 325 2026-01-25 00:00 "unknown"
複数の行にデータを代入するには、同じ名前とデータ型をもつ変数が格納された別の table から値を代入します。たとえば、新しい 2 行の table を作成します。
newOutages = table(["West";"North"], ... datetime(2024,1,1:2)', ... [3;4], ... [300;400], ... datetime(2024,1,3:4)',["unknown";"unknown"], ... VariableNames=outages.Properties.VariableNames)
newOutages=2×6 table
Region OutageTime Loss Customers RestorationTime Cause
_______ ___________ ____ _________ _______________ _________
"West" 01-Jan-2024 3 300 03-Jan-2024 "unknown"
"North" 02-Jan-2024 4 400 04-Jan-2024 "unknown"
2 行の table を outages の最初の 2 行に代入します。その後、outages の最初の 4 行を表示します。
outages(1:2,:) = newOutages; outages(1:4,:)
ans=4×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ _________ ________________ _________________
"West" 2024-01-01 00:00 3 300 2024-01-03 00:00 "unknown"
"North" 2024-01-02 00:00 4 400 2024-01-04 00:00 "unknown"
"SouthEast" 2003-02-07 21:15 2.894 14.294 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 4.3481 34.037 2004-04-06 06:10 "equipment fault"
要素への値の代入
table の要素に値を代入するには、中かっこを使用します。たとえば、最初の 2 つに停電の原因を代入します。
outages{1,"Cause"} = "severe storm";
outages{2,"Cause"} = "attack";
outages(1:4,:)ans=4×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ _________ ________________ _________________
"West" 2024-01-01 00:00 3 300 2024-01-03 00:00 "severe storm"
"North" 2024-01-02 00:00 4 400 2024-01-04 00:00 "attack"
"SouthEast" 2003-02-07 21:15 2.894 14.294 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 4.3481 34.037 2004-04-06 06:10 "equipment fault"
値が条件を満たす table の行の検索
値が条件を満たす table の行を検索するには、論理インデックス付けを使用します。対象の値をもつ table 変数を指定し、それらの変数の値が指定した条件を満たす行インデックスの配列を作成します。行インデックスを使用して table にインデックスを付けます。
最初に、停電データをスプレッドシートから table にインポートします。
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
次に、変数が条件を満たす行に一致する行インデックスを作成します。たとえば、地域が West である行のインデックスを作成します。
rows = matches(outages.Region,"West")rows = 1468×1 logical array
0
0
0
1
0
1
1
1
0
0
0
1
0
0
1
⋮
論理インデックスを使用して table にインデックスを付けることができます。West 地域で発生した停電を対象に table の行を表示します。
outages(rows,:)
ans=354×6 table
Region OutageTime Loss Customers RestorationTime Cause
______ ________________ ______ __________ ________________ _________________
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"West" 2004-12-21 18:50 112.05 7.985e+05 2004-12-29 03:46 "winter storm"
"West" 2002-12-16 13:43 70.752 4.8193e+05 2002-12-19 09:38 "winter storm"
"West" 2005-06-29 08:37 601.13 32005 2005-06-29 08:57 "equipment fault"
"West" 2003-04-14 07:11 276.41 1.5647 2003-04-14 08:52 "equipment fault"
"West" 2003-10-21 17:25 235.12 51496 2003-10-21 19:43 "equipment fault"
"West" 2005-10-21 08:33 NaN 52639 2005-11-22 22:10 "fire"
"West" 2003-08-28 23:46 172.01 1.6964e+05 2003-09-03 02:10 "wind"
"West" 2005-03-01 14:39 115.47 82611 2005-03-03 05:58 "equipment fault"
"West" 2005-09-26 06:32 258.18 1.3996e+05 2005-09-26 06:33 "earthquake"
"West" 2003-12-22 03:40 232.26 3.9462e+05 2003-12-24 16:32 "winter storm"
⋮
1 つの論理式を使って複数の条件と照合することができます。たとえば、West 地域または MidWest 地域の 100 万人を超える顧客が影響を受けた停電の行を検索します。
rows = (outages.Customers > 1e6 & (matches(outages.Region,"West") | matches(outages.Region,"MidWest"))); outages(rows,:)
ans=10×6 table
Region OutageTime Loss Customers RestorationTime Cause
_________ ________________ ______ __________ ________________ _________________
"MidWest" 2002-12-10 10:45 14493 3.0879e+06 2002-12-11 18:06 "unknown"
"West" 2007-10-20 20:56 3537.5 1.3637e+06 2007-10-20 22:08 "equipment fault"
"West" 2006-12-28 14:04 804.05 1.5486e+06 2007-01-04 14:26 "severe storm"
"MidWest" 2006-07-16 00:05 1817.9 3.295e+06 2006-07-27 14:42 "severe storm"
"West" 2006-01-01 11:54 734.11 4.26e+06 2006-01-11 01:21 "winter storm"
"MidWest" 2008-09-19 23:31 4801.1 1.2151e+06 2008-10-03 14:04 "severe storm"
"MidWest" 2008-09-07 23:35 NaN 3.972e+06 2008-09-19 17:19 "severe storm"
"West" 2011-07-24 02:54 483.37 1.1212e+06 2011-07-24 12:18 "wind"
"West" 2010-01-24 18:47 348.91 1.8865e+06 2010-01-30 01:43 "severe storm"
"West" 2010-05-17 09:10 8496.6 2.0768e+06 2010-05-18 22:43 "equipment fault"
table インデックス構文の概要
次の表は、すべての table インデックス構文の一覧です。すべてのタイプのインデックスと結果として得られる出力を示しています。行と変数は、位置、名前、またはデータ型によって指定できます。
線形インデックス付けはサポートされていません。中かっこまたは小かっこでインデックスを付ける場合は、行と変数の両方を指定しなければなりません。
変数名と行名には、スペースや非 ASCII 文字など任意の文字を含めることができます。また、英字だけでなく任意の文字で始めることができます。変数名と行名は、有効な MATLAB 識別子 (関数
isvarnameで判定) である必要はありません。行または変数を名前で指定する場合は、
patternオブジェクトを使用して名前を指定できます。たとえば、"Var" + digitsPatternはVarで始まり、任意の桁数で終わるすべての名前と一致します。 (R2022a 以降)
出力 | 構文 | 行 | 変数 | 例 |
|---|---|---|---|---|
1 つの変数から抽出されたデータをもつ配列 |
| 指定なし | 指定値:
|
|
1 つの変数から抽出されたデータの指定した要素をもつ配列 |
| 指定なし インデックス | 指定値:
| 数値インデックスまたは logical インデックスを使用して配列の要素を指定します。 抽出された配列が行列または多次元配列の場合は、複数の数値インデックスを指定できます。
|
指定した行と変数からのデータを連結した配列 |
| 指定値:
| 指定値:
|
|
指定した行と指定したデータ型の変数からのデータを連結した配列 |
| 指定値:
|
|
|
すべての行と変数からのデータを連結した配列 |
| 指定なし | 指定なし |
|
指定した行と変数をもつ table |
| 指定値:
| 指定値:
|
|
指定した行と指定したデータ型の変数をもつ配列 |
| 指定値:
|
|
|
参考
table | readtable | vartype | matches