table の作成とその table へのデータの代入
table は、テキスト ファイルまたはスプレッドシートの表形式データなどの列方向データに適しています。table はデータの列を変数に格納します。table 内の変数は、データ型が異なってもかまいませんが、行数はすべての変数で同じでなければなりません。ただし、table 変数は列ベクトルのみの格納に制限されません。たとえば、テーブル変数には、行数が他のテーブル変数と同じであるかぎり、複数列の行列を含めることができます。
MATLAB® では、いくつかの方法で table を作成し、その table にデータを代入できます。
関数
tableを使用して入力配列から table を作成する。ドット表記を使用して既存の table に変数を追加する。
空の table に変数を代入する。
table を事前に割り当てて後でそのデータを入力する。
関数
array2table、cell2tableまたはstruct2tableを使用して変数を table に変換する。関数
readtableを使用してファイルから table を読み取る。"インポート ツール" を使用して table をインポートする。
どの方法を選択するかは、データの特性とコードでの table の使用方法によって決まります。
入力配列からの table の作成
関数 table を使用して配列から table を作成できます。たとえば、5 名の患者のデータを含む小さい table を作成します。
まず、データの列方向配列を 6 つ作成します。患者数は 5 名であるため、これらの配列には 5 つの行があります (これらの配列のほとんどが 5 行 1 列の列ベクトルですが、BloodPressure は 5 行 2 列の行列です)。
LastName = ["Sanchez";"Johnson";"Zhang";"Diaz";"Brown"]; Age = [38;43;38;40;49]; Smoker = [true;false;true;false;true]; Height = [71;69;64;67;64]; Weight = [176;163;131;133;119]; BloodPressure = [124 93; 109 77; 125 83; 117 75; 122 80];
次に、table patients をデータのコンテナーとして作成します。この関数 table の呼び出しでは、入力引数はワークスペース変数名を patients の変数の名前として使用します。
patients = table(LastName,Age,Smoker,Height,Weight,BloodPressure)
patients=5×6 table
LastName Age Smoker Height Weight BloodPressure
_________ ___ ______ ______ ______ _____________
"Sanchez" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Zhang" 38 true 64 131 125 83
"Diaz" 40 false 67 133 117 75
"Brown" 49 true 64 119 122 80
この table は、6 つの変数があるため 5 行 6 列の table になります。変数 BloodPressure が示すように、table 変数自体は複数の列をもつことができます。この例は、table が行と列ではなく行と変数をもつ理由を示しています。
ドット表記を使用した table への変数の追加
table を作成したら、"ドット表記" を使用していつでも新しい変数を追加できます。ドット表記は table 変数を名前 "T.varname" で参照します。ここで、"T" は table で、"varname" は変数名です。この表記は、構造体のフィールドにアクセスしてデータを代入するために使用する表記と似ています。
たとえば、変数 BMI を patients に追加します。patients.Weight と patients.Height の値を使用してボディマス指数 (BMI) を計算します。BMI 値を新しい table 変数に代入します。
patients.BMI = (patients.Weight*0.453592)./(patients.Height*0.0254).^2
patients=5×7 table
LastName Age Smoker Height Weight BloodPressure BMI
_________ ___ ______ ______ ______ _____________ ______
"Sanchez" 38 true 71 176 124 93 24.547
"Johnson" 43 false 69 163 109 77 24.071
"Zhang" 38 true 64 131 125 83 22.486
"Diaz" 40 false 67 133 117 75 20.831
"Brown" 49 true 64 119 122 80 20.426
空の table への変数の代入
table を作成するもう 1 つの方法は、空の table から始めてその table に変数を代入することです。たとえば、患者データの table を再作成しますが、今回はドット表記を使用して変数を代入します。
まず、table を引数なしで呼び出して、空の table patients2 を作成します。
patients2 = table
patients2 = 0×0 empty table
次に、変数を代入して患者データのコピーを作成します。Name および BP table 変数からわかるように、table 変数の名前は配列名と一致する必要はありません。
patients2.Name = LastName; patients2.Age = Age; patients2.Smoker = Smoker; patients2.Height = Height; patients2.Weight = Weight; patients2.BP = BloodPressure
patients2=5×6 table
Name Age Smoker Height Weight BP
_________ ___ ______ ______ ______ __________
"Sanchez" 38 true 71 176 124 93
"Johnson" 43 false 69 163 109 77
"Zhang" 38 true 64 131 125 83
"Diaz" 40 false 67 133 117 75
"Brown" 49 true 64 119 122 80
table の事前割り当てと行の入力
table に格納するデータのサイズとデータ型がわかっているが、データを後で代入する場合があります。おそらく、一度に数行しか追加しません。その場合は、table にスペースを "事前割り当て" してから空の行に値を代入した方が効率的です。
たとえば、異なる気象計における時間および温度測定値を格納するための table にスペースを事前に割り当てるには、関数 table を使用します。入力配列を指定する代わりに、table 変数のサイズとデータ型を指定します。これらに名前を付けるには、名前と値の引数 VariableNames を指定します。事前割り当てにより、それらのデータ型に適した既定値が table 変数に代入されます。
sz = [4 3]; varTypes = ["double" "datetime" "string"]; varNames = ["Temperature" "Time" "Station"]; temps = table(Size=sz,VariableTypes=varTypes,VariableNames=varNames)
temps=4×3 table
Temperature Time Station
___________ ____ _________
0 NaT <missing>
0 NaT <missing>
0 NaT <missing>
0 NaT <missing>
table に行を代入または追加する方法の 1 つとして、行に cell 配列を代入する方法があります。cell 配列が行ベクトルで、その要素がそれぞれの変数のデータ型と一致する場合は、代入によって cell 配列が table の行に変換されます。ただし、cell 配列を使用して代入できるのは一度に 1 行だけです。値を最初の 2 行に代入します。
temps(1,:) = {75,datetime("now"),"S1"};
temps(2,:) = {68,datetime("now")+1,"S2"}temps=4×3 table
Temperature Time Station
___________ ____________________ _________
75 29-Jan-2026 13:15:59 "S1"
68 30-Jan-2026 13:15:59 "S2"
0 NaT <missing>
0 NaT <missing>
代替方法として、小さい table から大きい table に行を代入できます。この方法では、一度に 1 行以上を代入できます。
temps(3:4,:) = table([63;72],[datetime("now")+2;datetime("now")+3],["S3";"S4"])
temps=4×3 table
Temperature Time Station
___________ ____________________ _______
75 29-Jan-2026 13:15:59 "S1"
68 30-Jan-2026 13:15:59 "S2"
63 31-Jan-2026 13:15:59 "S3"
72 01-Feb-2026 13:15:59 "S4"
いずれかの構文を使用して、table の末尾を越えて行を代入すると、table のサイズを増加できます。必要に応じて、欠損している行は既定値で埋められます。
temps(6,:) = {62,datetime("now")+6,"S6"}temps=6×3 table
Temperature Time Station
___________ ____________________ _________
75 29-Jan-2026 13:15:59 "S1"
68 30-Jan-2026 13:15:59 "S2"
63 31-Jan-2026 13:15:59 "S3"
72 01-Feb-2026 13:15:59 "S4"
0 NaT <missing>
62 04-Feb-2026 13:15:59 "S6"
変数から table への変換
他のデータ型をもつ変数を table に変換できます。cell 配列と構造体は、データ型が異なる配列を格納できる他のタイプのコンテナーです。そのため、cell 配列と構造体を table に変換できます。また、配列を table に変換して、table 変数に配列からの値の列が含まれるようにもできます。これらの種類の変数を変換するには、関数 array2table、cell2table または struct2table を使用します。
たとえば、array2table を使用して配列を table に変換します。配列には列名がないため、table は既定の変数名をもちます。
A = randi(3,3)
A = 3×3
3 3 1
3 2 2
1 1 3
a2t = array2table(A)
a2t=3×3 table
A1 A2 A3
__ __ __
3 3 1
3 2 2
1 1 3
独自の table 変数名を指定するには、名前と値の引数 VariableNames を使用します。
a2t = array2table(A,VariableNames=["First" "Second" "Third"])
a2t=3×3 table
First Second Third
_____ ______ _____
3 3 1
3 2 2
1 1 3
ファイルからの table の読み取り
一般的に、CSV (コンマ区切り値) ファイルや Excel® スプレッドシートなどのファイルには大量の表形式データがあります。このようなデータを table に読み取るには、関数 readtable を使用します。
たとえば、CSV ファイル outages.csv は、MATLAB に同梱されているサンプル ファイルです。このファイルには一連の停電のデータが含まれています。outages.csv の最初の行は列名です。ファイルの残りは、停電ごとのコンマ区切りのデータ値です。最初の数行を以下に示します。
Region,OutageTime,Loss,Customers,RestorationTime,Cause SouthWest,2002-02-01 12:18,458.9772218,1820159.482,2002-02-07 16:50,winter storm SouthEast,2003-01-23 00:49,530.1399497,212035.3001,,winter storm SouthEast,2003-02-07 21:15,289.4035493,142938.6282,2003-02-17 08:14,winter storm West,2004-04-06 05:44,434.8053524,340371.0338,2004-04-06 06:10,equipment fault MidWest,2002-03-16 06:18,186.4367788,212754.055,2002-03-18 23:23,severe storm ...
outages.csv を読み取ってデータを table に格納するには、readtable を使用します。これにより、数値、日付と時刻、および string が適切なデータ型をもつ table 変数に読み取られます。ここで、Loss と Customers は数値配列です。変数 OutageTime および RestorationTime は datetime 配列です。readtable は、入力ファイルのこれらの列内にあるテキストの日付と時刻の形式を認識するためです。残りのテキスト データを string 配列に読み取るには、名前と値の引数 TextType を指定します。
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
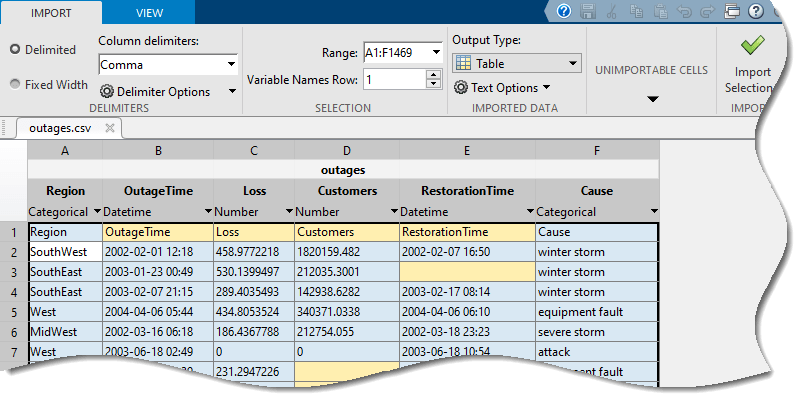
インポート ツールを使用した table のインポート
最後に、"インポート ツール" を使用して、スプレッドシートまたは区切りテキスト ファイルのデータを対話的にプレビューしたり、インポートしたりできます。"インポート ツール" を開くには 2 つの方法があります。
MATLAB ツールストリップ: [ホーム] タブの [変数] セクションで、[データのインポート] をクリックします。
MATLAB コマンド プロンプト: 「
uiimport(filename)」と入力します。ここで、"filename"はテキスト ファイルまたはスプレッドシート ファイルの名前です。
たとえば、outages.csv サンプル ファイルを開くには、uiimport と which を使用してそのファイルのパスを取得します。
uiimport(which("outages.csv"))
"インポート ツール" には、outages.csv の 6 列のプレビューが表示されます。データを table としてインポートするには、以下の手順に従います。
[インポートされた変数] セクションで、型として [table] を選択します。
[選択のインポート] (右上隅付近にある) をクリックします。ワークスペースに
outagesという名前の新しい table が表示されます。
参考
関数
readtable|table|array2table|cell2table|struct2table