このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
ClassificationSVM
1 クラスおよびバイナリ分類用のサポート ベクター マシン (SVM)
説明
ClassificationSVM は 1 クラスおよび 2 クラス学習用のサポート ベクター マシン (SVM) 分類器です。学習済みの ClassificationSVM 分類器には、学習データ、パラメーター値、事前確率、サポート ベクターおよびアルゴリズムの実装情報が格納されます。これらの分類器を使用して、スコアから事後確率に変換する関数の当てはめ (fitPosterior を参照) や新しいデータに対するラベルの予測 (predict を参照) などのタスクを実行できます。
作成
ClassificationSVM オブジェクトの作成には fitcsvm を使用します。
プロパティ
オブジェクト関数
compact | 機械学習モデルのサイズの縮小 |
compareHoldout | 新しいデータを使用して 2 つの分類モデルの精度を比較 |
crossval | 機械学習モデルの交差検証 |
discardSupportVectors | 線形サポート ベクター マシン (SVM) 分類器のサポート ベクターを破棄 |
edge | サポート ベクター マシン (SVM) 分類器の分類エッジを計算 |
fitPosterior | サポート ベクター マシン (SVM) 分類器の事後確率の当てはめ |
gather | GPU からの Statistics and Machine Learning Toolbox オブジェクトのプロパティの収集 |
incrementalLearner | バイナリ分類サポート ベクター マシン (SVM) モデルのインクリメンタル学習器への変換 |
lime | Local Interpretable Model-agnostic Explanations (LIME) |
loss | サポート ベクター マシン (SVM) 分類器の分類誤差を計算 |
margin | サポート ベクター マシン (SVM) 分類器の分類マージンを計算 |
partialDependence | 部分依存の計算 |
plotPartialDependence | 部分依存プロット (PDP) および個別条件付き期待値 (ICE) プロットの作成 |
predict | サポート ベクター マシン (SVM) 分類器を使用して観測値を分類 |
resubEdge | 再代入分類エッジ |
resubLoss | 再代入分類損失 |
resubMargin | 再代入分類マージン |
resubPredict | 学習済み分類器を使用した学習データの分類 |
resume | サポート ベクター マシン (SVM) 分類器の学習を再開 |
shapley | シャープレイ値 |
testckfold | 交差検証の反復により 2 つの分類モデルの精度を比較 |
例
フィッシャーのアヤメのデータ セットを読み込みます。がく片の長さと幅および観測済みのすべての setosa 種のアヤメを削除します。
load fisheriris inds = ~strcmp(species,'setosa'); X = meas(inds,3:4); y = species(inds);
処理済みのデータ セットを使用して SVM 分類器に学習させます。
SVMModel = fitcsvm(X,y)
SVMModel =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 100
Alpha: [24×1 double]
Bias: -14.4149
KernelParameters: [1×1 struct]
BoxConstraints: [100×1 double]
ConvergenceInfo: [1×1 struct]
IsSupportVector: [100×1 logical]
Solver: 'SMO'
Properties, Methods
SVMModel は学習させた ClassificationSVM 分類器です。SVMModel のプロパティを表示します。たとえば、クラスの順序を確認するには、ドット表記を使用します。
classOrder = SVMModel.ClassNames
classOrder = 2×1 cell
{'versicolor'}
{'virginica' }
最初のクラス ('versicolor') は陰性のクラスで、2 番目のクラス ('virginica') は陽性のクラスです。'ClassNames' 名前と値のペアの引数を使用すると、学習中にクラスの順序を変更できます。
データの散布図をプロットし、サポート ベクターを円で囲みます。
sv = SVMModel.SupportVectors; figure gscatter(X(:,1),X(:,2),y) hold on plot(sv(:,1),sv(:,2),'ko','MarkerSize',10) legend('versicolor','virginica','Support Vector') hold off
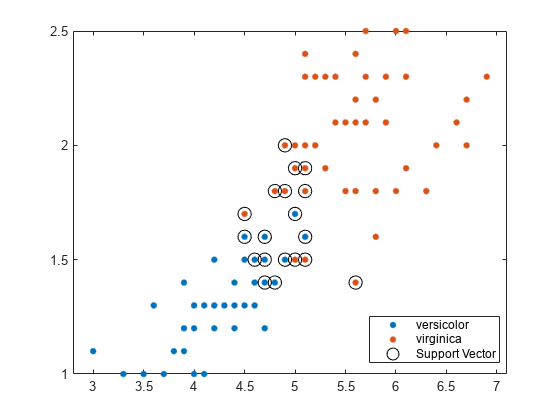
サポート ベクターは、推定されたクラス境界の上または外側で発生する観測値です。
名前と値のペアの引数 'BoxConstraint' を使用して学習時のボックス制約を設定すると、境界 (および結果的にサポート ベクターの個数) を調整できます。
ionosphere データ セットを読み込みます。
load ionosphereSVM 分類器の学習と交差検証を行います。予測子データを標準化し、クラスの順序を指定します。
rng(1); % For reproducibility CVSVMModel = fitcsvm(X,Y,'Standardize',true,... 'ClassNames',{'b','g'},'CrossVal','on')
CVSVMModel =
ClassificationPartitionedModel
CrossValidatedModel: 'SVM'
PredictorNames: {'x1' 'x2' 'x3' 'x4' 'x5' 'x6' 'x7' 'x8' 'x9' 'x10' 'x11' 'x12' 'x13' 'x14' 'x15' 'x16' 'x17' 'x18' 'x19' 'x20' 'x21' 'x22' 'x23' 'x24' 'x25' 'x26' 'x27' 'x28' 'x29' 'x30' 'x31' 'x32' 'x33' 'x34'}
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Properties, Methods
CVSVMModel は ClassificationPartitionedModel 交差検証 SVM 分類器です。既定では、10 分割交差検証が実行されます。
あるいは、学習済みの ClassificationSVM 分類器を crossval に渡すことにより、この分類器を交差検証できます。
ドット表記を使用して、学習させた分割のいずれかを検査します。
CVSVMModel.Trained{1}ans =
CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Alpha: [78×1 double]
Bias: -0.2210
KernelParameters: [1×1 struct]
Mu: [0.8888 0 0.6320 0.0406 0.5931 0.1205 0.5361 0.1286 0.5083 0.1879 0.4779 0.1567 0.3924 0.0875 0.3360 0.0789 0.3839 9.6066e-05 0.3562 -0.0308 0.3398 -0.0073 0.3590 -0.0628 0.4064 -0.0664 0.5535 -0.0749 0.3835 … ] (1×34 double)
Sigma: [0.3149 0 0.5033 0.4441 0.5255 0.4663 0.4987 0.5205 0.5040 0.4780 0.5649 0.4896 0.6293 0.4924 0.6606 0.4535 0.6133 0.4878 0.6250 0.5140 0.6075 0.5150 0.6068 0.5222 0.5729 0.5103 0.5061 0.5478 0.5712 0.5032 … ] (1×34 double)
SupportVectors: [78×34 double]
SupportVectorLabels: [78×1 double]
Properties, Methods
各分割は、データの 90% で学習済みの CompactClassificationSVM 分類器です。
汎化誤差を推定します。
genError = kfoldLoss(CVSVMModel)
genError = 0.1168
平均すると汎化誤差は約 12% です。
詳細
アルゴリズム
SVM バイナリ分類アルゴリズムの数学的定式化については、バイナリ分類のサポート ベクター マシンとサポート ベクター マシンについてを参照してください。
NaN、<undefined>、空の文字ベクトル ('')、空の string ("")、および<missing>値は、欠損値を示します。fitcsvmは、欠損応答に対応するデータ行全体を削除します。fitcsvmは、重みの合計を計算するときに (以下の項目を参照)、欠損している予測子が 1 つ以上ある観測値に対応する重みを無視します。これにより、平衡なクラスの問題で不平衡な事前確率が発生する可能性があります。したがって、観測値のボックス制約がBoxConstraintに等しくならない可能性があります。名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列 (C) が変更なしで格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。モデルの学習用に、事前確率と観測値の重みが更新されて、コスト行列で指定されているペナルティが組み込まれます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。名前と値の引数
CostおよびPriorは 2 クラス学習用であることに注意してください。1 クラス学習の場合、Costプロパティには0、Priorプロパティには1が格納されます。2 クラス学習の場合、
fitcsvmは学習データの各観測値にボックス制約を割り当てます。観測値 j のボックス制約の式は、次のようになります。ここで、C0 は初期のボックス制約 (名前と値の引数
BoxConstraintを参照)、wj* は観測値 j のCostとPriorで調整された観測値の重みです。観測値の重みの詳細については、誤分類コスト行列に応じた事前確率と観測値の重みの調整を参照してください。Standardizeをtrueとして指定し、名前と値の引数Cost、Prior、またはWeightsを設定した場合、fitcsvmは対応する加重平均および加重標準偏差を使用して予測子を標準化します。つまり、fitcsvmは、以下を使用して予測子 j (xj) を標準化します。ここで、xjk は予測子 j (列) の観測値 k (行) であり、次のようになります。
pは学習データで予期される外れ値の比率であり、'OutlierFraction',pを設定したと仮定します。1 クラス学習では、バイアス項の学習により、学習データの観測値のうち 100
p% が負のスコアをもつようになります。2 クラス学習では "ロバスト学習" が行われます。この方式では、最適化アルゴリズムが収束すると、観測値のうち 100
p% の削除が試行されます。削除された観測値は、勾配の大きいものに対応します。
予測子データにカテゴリカル変数が含まれている場合、一般にこれらの変数について完全なダミー エンコードが使用されます。各カテゴリカル変数の各レベルについて、1 つずつダミー変数が作成されます。
PredictorNamesプロパティには、元の予測子変数名のそれぞれについて 1 つずつ要素が格納されます。たとえば、3 つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、PredictorNamesは元の予測子変数名が含まれている 1 行 3 列の文字ベクトルの cell 配列になります。ExpandedPredictorNamesプロパティには、ダミー変数を含む予測子変数のそれぞれについて 1 つずつ要素が格納されます。たとえば、3 つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、ExpandedPredictorNamesは予測子変数および新しいダミー変数の名前が含まれている 1 行 5 列の文字ベクトルの cell 配列になります。同様に、
Betaプロパティには、ダミー変数を含む各予測子について 1 つずつベータ係数が格納されます。SupportVectorsプロパティには、ダミー変数を含むサポート ベクターの予測子の値が格納されます。たとえば、m 個のサポート ベクターと 3 つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、SupportVectorsは n 行 5 列の行列になります。Xプロパティには、はじめに入力されたときの状態で学習データが格納され、ダミー変数は含まれません。入力が table の場合、Xには予測子として使用した列のみが格納されます。
table で予測子を指定した場合、いずれかの変数に順序付きのカテゴリが含まれていると、これらの変数について順序付きエンコードが使用されます。
k 個の順序付きレベルが変数に含まれている場合、k – 1 個のダミー変数が作成されます。j 番目のダミー変数は、j までのレベルについては –1、j + 1 から k までのレベルについては +1 になります。
ExpandedPredictorNamesプロパティに格納されるダミー変数の名前は 1 番目のレベルを示し、値は +1 になります。レベル 2, 3, ..., k の名前を含む k – 1 個の追加予測子名がダミー変数について格納されます。
どのソルバーも L1 ソフト マージン最小化を実装します。
1 クラス学習の場合、次の条件を満たすラグランジュ乗数 α1,...,αn が推定されます。
参照
[2] Scholkopf, B., J. C. Platt, J. C. Shawe-Taylor, A. J. Smola, and R. C. Williamson. “Estimating the Support of a High-Dimensional Distribution.” Neural Comput., Vol. 13, Number 7, 2001, pp. 1443–1471.