update
コード生成用にモデル パラメーターを更新
説明
コーダー コンフィギュアラー オブジェクトを使用して、機械学習モデルの関数 predict および update に対する C/C++ コードを生成します。learnerCoderConfigurer およびそのオブジェクト関数 generateCode を使用してこのオブジェクトを作成します。これにより、生成されたコードのモデル パラメーターは、コードの再生成を必要としない、関数 update を使用した更新が可能になります。この機能により、新しいデータや設定でモデルに再学習をさせるときに、C/C++ コードの再生成、再展開および再確認に必要な作業が低減されます。
次のフロー チャートは、コーダー コンフィギュアラーを使用するコード生成のワークフローを示します。強調表示されているステップで update を使用します。
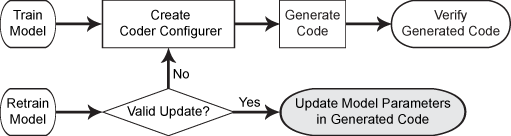
コードを生成しない場合、関数 update を使用する必要はありません。MATLAB® でモデルに再学習をさせると、返されるモデルには修正されたパラメーターが既に含まれています。
updatedMdl = update(Mdl,params)params の新しいパラメーターが含まれている更新されたバージョンの Mdl を返します。
モデルに再学習をさせた後で、関数 validatedUpdateInputs を使用して、再学習済みモデルの修正されたパラメーターを検出し、修正されたパラメーターの値がパラメーターのコーダー属性を満たすかどうかを検証します。validatedUpdateInputs の出力である検証されたパラメーターを入力 params として使用して、モデル パラメーターを更新します。
例
データ セットの一部を使用して SVM モデルに学習させ、モデルについてコーダー コンフィギュアラーを作成します。コーダー コンフィギュアラーのプロパティを使用して、SVM モデル パラメーターのコーダー属性を指定します。コーダー コンフィギュアラーのオブジェクト関数を使用して、新しい予測子データについてラベルを予測する C コードを生成します。その後、データ セット全体を使用してモデルに再学習をさせ、コードを再生成せずに、生成されたコードのパラメーターを更新します。
モデルの学習
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphere最初の 50 個の観測値と自動カーネル スケールのガウス カーネル関数を使用してバイナリ SVM 分類モデルに学習させます。
Mdl = fitcsvm(X(1:50,:),Y(1:50), ... 'KernelFunction','gaussian','KernelScale','auto');
Mdl は、ClassificationSVM オブジェクトです。
コーダー コンフィギュアラーの作成
learnerCoderConfigurer を使用して、ClassificationSVM モデルについてコーダー コンフィギュアラーを作成します。予測子データ X を行列の形式で指定します。関数 learnerCoderConfigurer では table の形式の予測子データはサポートされないことに注意してください。関数 learnerCoderConfigurer は、入力 X を使用して、関数 predict の入力のコーダー属性を設定します。また、生成されるコードが予測ラベルおよびスコアを返すようにするため、出力の個数を 2 に設定します。
configurer = learnerCoderConfigurer(Mdl,X(1:50,:),'NumOutputs',2);configurer は、ClassificationSVM オブジェクトのコーダー コンフィギュアラーである ClassificationSVMCoderConfigurer オブジェクトです。
パラメーターのコーダー属性の指定
生成されたコードのパラメーターをモデルの再学習後に更新できるようにするため、SVM 分類モデルのパラメーターのコーダー属性を指定します。この例では、生成されたコードに渡す予測子データのコーダー属性と、SVM モデルのサポート ベクターのコーダー属性を指定します。
はじめに、生成されたコードが任意の個数の観測値を受け入れるように、X のコーダー属性を指定します。属性 SizeVector および VariableDimensions を変更します。属性 SizeVector は、予測子データのサイズの上限を指定し、属性 VariableDimensions は、予測子データの各次元が可変サイズと固定サイズのどちらであるかを指定します。
configurer.X.SizeVector = [Inf 34]; configurer.X.VariableDimensions = [true false];
1 番目の次元のサイズは、観測値の個数です。このケースでは、サイズの上限が Inf であり、サイズが可変、つまり X の観測値の個数が任意であることを指定します。この指定は、コードを生成するときに観測値の個数が不明である場合に便利です。
2 番目の次元のサイズは、予測子変数の個数です。この値は、機械学習モデルに対し固定でなければなりません。X には 34 個の予測子が含まれているので、属性 SizeVector の値は 34、属性 VariableDimensions の値は false でなければなりません。
新しいデータまたは異なる設定を使用して SVM モデルに再学習をさせた場合、サポート ベクターの個数が変化する可能性があります。したがって、生成されたコードのサポート ベクターを更新できるように SupportVectors のコーダー属性を指定します。
configurer.SupportVectors.SizeVector = [250 34];
SizeVector attribute for Alpha has been modified to satisfy configuration constraints. SizeVector attribute for SupportVectorLabels has been modified to satisfy configuration constraints.
configurer.SupportVectors.VariableDimensions = [true false];
VariableDimensions attribute for Alpha has been modified to satisfy configuration constraints. VariableDimensions attribute for SupportVectorLabels has been modified to satisfy configuration constraints.
SupportVectors のコーダー属性が変更されると、Alpha および SupportVectorLabels のコーダー属性が構成の制約を満たすように変更されます。あるパラメーターのコーダー属性の変更によって構成の制約を満たすために他の従属パラメーターの変更が必要になる場合、従属パラメーターのコーダー属性は変更されます。
コードの生成
C/C++ コードを生成するには、適切に設定されている C/C++ コンパイラにアクセスできなければなりません。MATLAB Coder は、サポートされているインストール済みのコンパイラを探して使用します。mex -setup を使用すると、既定のコンパイラを表示および変更できます。詳細は、既定のコンパイラの変更を参照してください。
generateCodeを使用して、SVM 分類モデル (Mdl) の関数 predict および update について、既定の設定でコードを生成します。
generateCode(configurer)
generateCode creates these files in output folder: 'initialize.m', 'predict.m', 'update.m', 'ClassificationSVMModel.mat' Code generation successful.
generateCode は、コードを生成するために必要な MATLAB ファイルを生成します。これには、Mdl の関数 predict および update にそれぞれ対応する 2 つのエントリポイント関数 predict.m および update.m が含まれます。次に generateCode は、2 つのエントリポイント関数に対して ClassificationSVMModel という名前の MEX 関数を codegen\mex\ClassificationSVMModel フォルダー内に作成し、この MEX 関数を現在のフォルダーにコピーします。
生成されたコードの確認
予測子データを渡して、Mdl の関数 predict と MEX 関数の関数 predict が同じラベルを返すかどうかを確認します。複数のエントリポイントがある MEX 関数内のエントリポイント関数を呼び出すため、1 番目の入力引数として関数名を指定します。
[label,score] = predict(Mdl,X);
[label_mex,score_mex] = ClassificationSVMModel('predict',X);isequal を使用して、label と label_mex を比較します。
isequal(label,label_mex)
ans = logical
1
すべての入力が等しい場合、isequal は logical 1 (true) を返します。この比較により、同じラベルを Mdl の関数 predict と MEX 関数の関数 predict が返すことを確認します。
score と比較すると、score_mex には丸めによる差が含まれている場合があります。このような場合は、小さい誤差を許容して score_mex と score を比較します。
find(abs(score-score_mex) > 1e-8)
ans = 0×1 empty double column vector
この比較により、許容誤差 1e–8 内で score と score_mex が等しいことを確認します。
モデルの再学習と生成コード内のパラメーターの更新
データ セット全体を使用してモデルに再学習をさせます。
retrainedMdl = fitcsvm(X,Y, ... 'KernelFunction','gaussian','KernelScale','auto');
validatedUpdateInputs を使用して、更新するパラメーターを抽出します。この関数は、retrainedMdl 内の修正されたモデル パラメーターを判別し、修正されたパラメーター値がパラメーターのコーダー属性を満たすかどうかを検証します。
params = validatedUpdateInputs(configurer,retrainedMdl);
生成されたコード内のパラメーターを更新します。
ClassificationSVMModel('update',params)生成されたコードの確認
retrainedMdl の関数 predict の出力と、更新した MEX 関数の関数 predict の出力を比較します。
[label,score] = predict(retrainedMdl,X);
[label_mex,score_mex] = ClassificationSVMModel('predict',X);
isequal(label,label_mex)ans = logical
1
find(abs(score-score_mex) > 1e-8)
ans = 0×1 empty double column vector
この比較により、labels と labels_mex が等しく、スコアの値が許容誤差内で等しいことを確認します。
SVM バイナリ学習器を使用する誤り訂正出力符号 (ECOC) モデルに学習をさせ、このモデルのコーダー コンフィギュアラーを作成します。コーダー コンフィギュアラーのプロパティを使用して、ECOC モデルのパラメーターのコーダー属性を指定します。コーダー コンフィギュアラーのオブジェクト関数を使用して、新しい予測子データについてラベルを予測する C コードを生成します。その後、異なる設定を使用してモデルに再学習をさせ、コードを再生成せずに、生成されたコードのパラメーターを更新します。
モデルの学習
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas;
Y = species;ガウス カーネル関数を使用し、予測子データを標準化する、SVM バイナリ学習器テンプレートを作成します。
t = templateSVM('KernelFunction','gaussian','Standardize',true);
テンプレート t を使用して、マルチクラス ECOC モデルに学習をさせます。
Mdl = fitcecoc(X,Y,'Learners',t);Mdl は、ClassificationECOC オブジェクトです。
コーダー コンフィギュアラーの作成
learnerCoderConfigurer を使用して、ClassificationECOC モデルについてコーダー コンフィギュアラーを作成します。予測子データ X を指定します。関数 learnerCoderConfigurer は、入力 X を使用して、関数 predict の入力のコーダー属性を設定します。また、出力の個数を 2 に設定して、生成されるコードが関数predictの最初の 2 つの出力 (予測されたラベルと符号を反転した平均バイナリ損失) を返すようにします。
configurer = learnerCoderConfigurer(Mdl,X,'NumOutputs',2)configurer =
ClassificationECOCCoderConfigurer with properties:
Update Inputs:
BinaryLearners: [1×1 ClassificationSVMCoderConfigurer]
Prior: [1×1 LearnerCoderInput]
Cost: [1×1 LearnerCoderInput]
Predict Inputs:
X: [1×1 LearnerCoderInput]
Code Generation Parameters:
NumOutputs: 2
OutputFileName: 'ClassificationECOCModel'
Properties, Methods
configurer は、ClassificationECOC オブジェクトのコーダー コンフィギュアラーである ClassificationECOCCoderConfigurer オブジェクトです。表示には、predict と update の調整可能な入力引数 X、BinaryLearners、Prior および Cost が示されています。
パラメーターのコーダー属性の指定
predict の引数 (予測子データと名前と値のペアの引数 'Decoding' および 'BinaryLoss') と update の引数 (SVM 学習器のサポート ベクター) のコーダー属性を指定して、生成されるコードでこれらの引数を predict と update の入力引数として使用できるようにします。
はじめに、生成されたコードが任意の個数の観測値を受け入れるように、X のコーダー属性を指定します。属性 SizeVector および VariableDimensions を変更します。属性 SizeVector は、予測子データのサイズの上限を指定し、属性 VariableDimensions は、予測子データの各次元が可変サイズと固定サイズのどちらであるかを指定します。
configurer.X.SizeVector = [Inf 4]; configurer.X.VariableDimensions = [true false];
1 番目の次元のサイズは、観測値の個数です。このケースでは、サイズの上限が Inf であり、サイズが可変、つまり X の観測値の個数が任意であることを指定します。この指定は、コードを生成するときに観測値の個数が不明である場合に便利です。
2 番目の次元のサイズは、予測子変数の個数です。この値は、機械学習モデルに対して固定しなければなりません。X には 4 つの予測子が含まれているので、SizeVector 属性の 2 番目の値は 4、VariableDimensions 属性の 2 番目の値は false でなければなりません。
次に、生成されるコードで名前と値のペアの引数 'BinaryLoss' および 'Decoding' を使用するように、BinaryLoss と Decoding のコーダー属性を変更します。BinaryLoss のコーダー属性を表示します。
configurer.BinaryLoss
ans =
EnumeratedInput with properties:
Value: 'hinge'
SelectedOption: 'Built-in'
BuiltInOptions: {'hamming' 'linear' 'quadratic' 'exponential' 'binodeviance' 'hinge' 'logit'}
IsConstant: 1
Tunability: 0
生成されるコードで既定以外の値を使用するには、コードを生成する前に値を指定しなければなりません。BinaryLoss の Value 属性として 'exponential' を指定します。
configurer.BinaryLoss.Value = 'exponential';
configurer.BinaryLossans =
EnumeratedInput with properties:
Value: 'exponential'
SelectedOption: 'Built-in'
BuiltInOptions: {'hamming' 'linear' 'quadratic' 'exponential' 'binodeviance' 'hinge' 'logit'}
IsConstant: 1
Tunability: 1
Tunability が false (logical 0) である場合に属性値を変更すると、Tunability は true (logical 1) に設定されます。
Decoding のコーダー属性を表示します。
configurer.Decoding
ans =
EnumeratedInput with properties:
Value: 'lossweighted'
SelectedOption: 'Built-in'
BuiltInOptions: {'lossweighted' 'lossbased'}
IsConstant: 1
Tunability: 0
生成されるコードで BuiltInOptions の利用可能なすべての値を使用できるようにするため、Decoding の IsConstant 属性として false を指定します。
configurer.Decoding.IsConstant = false; configurer.Decoding
ans =
EnumeratedInput with properties:
Value: [1×1 LearnerCoderInput]
SelectedOption: 'NonConstant'
BuiltInOptions: {'lossweighted' 'lossbased'}
IsConstant: 0
Tunability: 1
Decoding の Value 属性が LearnerCoderInput オブジェクトに変更されるので、'lossweighted' と 'lossbased' の両方を 'Decoding' の値として使用できます。また、SelectedOption が 'NonConstant' に、Tunability が true に設定されます。
最後に、BinaryLearners の SupportVectors のコーダー属性を変更します。SupportVectors のコーダー属性を表示します。
configurer.BinaryLearners.SupportVectors
ans =
LearnerCoderInput with properties:
SizeVector: [54 4]
VariableDimensions: [1 0]
DataType: 'double'
Tunability: 1
各学習器でサポート ベクターの個数が異なるので、VariableDimensions の既定値は [true false] です。新しいデータまたは異なる設定を使用して ECOC モデルに再学習をさせた場合、SVM 学習器のサポート ベクターの個数が変化する可能性があります。したがって、サポート ベクターの個数の上限を増やします。
configurer.BinaryLearners.SupportVectors.SizeVector = [150 4];
SizeVector attribute for Alpha has been modified to satisfy configuration constraints. SizeVector attribute for SupportVectorLabels has been modified to satisfy configuration constraints.
SupportVectors のコーダー属性が変更されると、Alpha および SupportVectorLabels のコーダー属性が構成の制約を満たすように変更されます。あるパラメーターのコーダー属性の変更によって構成の制約を満たすために他の従属パラメーターの変更が必要になる場合、従属パラメーターのコーダー属性は変更されます。
コーダー コンフィギュアラーを表示します。
configurer
configurer =
ClassificationECOCCoderConfigurer with properties:
Update Inputs:
BinaryLearners: [1×1 ClassificationSVMCoderConfigurer]
Prior: [1×1 LearnerCoderInput]
Cost: [1×1 LearnerCoderInput]
Predict Inputs:
X: [1×1 LearnerCoderInput]
BinaryLoss: [1×1 EnumeratedInput]
Decoding: [1×1 EnumeratedInput]
Code Generation Parameters:
NumOutputs: 2
OutputFileName: 'ClassificationECOCModel'
Properties, Methods
BinaryLoss と Decoding も表示に含まれるようになりました。
コードの生成
C/C++ コードを生成するには、適切に設定されている C/C++ コンパイラにアクセスできなければなりません。MATLAB Coder は、サポートされているインストール済みのコンパイラを探して使用します。mex -setup を使用すると、既定のコンパイラを表示および変更できます。詳細は、既定のコンパイラの変更を参照してください。
ECOC 分類モデル (Mdl) の関数 predict および update のコードを生成します。
generateCode(configurer)
generateCode creates these files in output folder: 'initialize.m', 'predict.m', 'update.m', 'ClassificationECOCModel.mat' Code generation successful.
関数 generateCode は、以下の処理を実行します。
コードを生成するために必要な MATLAB ファイルを生成する。これには、
Mdlの関数predictおよびupdateにそれぞれ対応する 2 つのエントリポイント関数predict.mおよびupdate.mが含まれます。2 つのエントリポイント関数に対して、
ClassificationECOCModelという名前の MEX 関数を作成する。MEX 関数のコードを
codegen\mex\ClassificationECOCModelフォルダーに作成する。MEX 関数を現在のフォルダーにコピーする。
生成されたコードの確認
予測子データを渡して、Mdl の関数 predict と MEX 関数の関数 predict が同じラベルを返すかどうかを確認します。複数のエントリポイントがある MEX 関数内のエントリポイント関数を呼び出すため、1 番目の入力引数として関数名を指定します。コードを生成する前に IsConstant 属性を変更して 'Decoding' を調整可能な入力引数として指定したので、'lossweighted' は 'Decoding' の既定値ですが、MEX 関数を呼び出すときにも同じ指定を行う必要があります。
[label,NegLoss] = predict(Mdl,X,'BinaryLoss','exponential'); [label_mex,NegLoss_mex] = ClassificationECOCModel('predict',X,'BinaryLoss','exponential','Decoding','lossweighted');
isequalを使用して、label と label_mex を比較します。
isequal(label,label_mex)
ans = logical
1
すべての入力が等しい場合、isequal は logical 1 (true) を返します。この比較により、同じラベルを Mdl の関数 predict と MEX 関数の関数 predict が返すことを確認します。
NegLoss と比較すると、NegLoss_mex には丸めによる差が含まれている可能性があります。このケースでは、小さい誤差を許容して NegLoss_mex と NegLoss を比較します。
find(abs(NegLoss-NegLoss_mex) > 1e-8)
ans = 0×1 empty double column vector
この比較により、許容誤差 1e–8 内で NegLoss と NegLoss_mex が等しいことを確認します。
モデルの再学習と生成コード内のパラメーターの更新
異なる設定を使用してモデルに再学習をさせます。ヒューリスティック手法を使用して適切なスケール係数が選択されるようにするため、'KernelScale' として 'auto' を指定します。
t_new = templateSVM('KernelFunction','gaussian','Standardize',true,'KernelScale','auto'); retrainedMdl = fitcecoc(X,Y,'Learners',t_new);
validatedUpdateInputs を使用して、更新するパラメーターを抽出します。この関数は、retrainedMdl 内の修正されたモデル パラメーターを判別し、修正されたパラメーター値がパラメーターのコーダー属性を満たすかどうかを検証します。
params = validatedUpdateInputs(configurer,retrainedMdl);
生成されたコード内のパラメーターを更新します。
ClassificationECOCModel('update',params)生成されたコードの確認
retrainedMdl の関数 predict の出力と、更新した MEX 関数の関数 predict の出力を比較します。
[label,NegLoss] = predict(retrainedMdl,X,'BinaryLoss','exponential','Decoding','lossbased'); [label_mex,NegLoss_mex] = ClassificationECOCModel('predict',X,'BinaryLoss','exponential','Decoding','lossbased'); isequal(label,label_mex)
ans = logical
1
find(abs(NegLoss-NegLoss_mex) > 1e-8)
ans = 0×1 empty double column vector
この比較により、label と label_mex が等しく、NegLoss と NegLoss_mex が許容誤差内で等しいことが確認されます。
データ セットの一部を使用してサポート ベクター マシン (SVM) モデルに学習をさせ、モデルについてコーダー コンフィギュアラーを作成します。コーダー コンフィギュアラーのプロパティを使用して、SVM モデル パラメーターのコーダー属性を指定します。コーダー コンフィギュアラーのオブジェクト関数を使用して、新しい予測子データについて応答を予測する C コードを生成します。その後、データ セット全体を使用してモデルに再学習をさせ、コードを再生成せずに、生成されたコードのパラメーターを更新します。
モデルの学習
carsmall データ セットを読み込みます。
load carsmall
X = [Horsepower,Weight];
Y = MPG;最初の 50 個の観測値と自動カーネル スケールのガウス カーネル関数を使用して SVM 回帰モデルに学習させます。
Mdl = fitrsvm(X(1:50,:),Y(1:50), ... 'KernelFunction','gaussian','KernelScale','auto');
Mdl は、RegressionSVM オブジェクトです。
コーダー コンフィギュアラーの作成
learnerCoderConfigurer を使用して、RegressionSVM モデルについてコーダー コンフィギュアラーを作成します。予測子データ X を指定します。関数 learnerCoderConfigurer は、入力 X を使用して、関数 predict の入力のコーダー属性を設定します。
configurer = learnerCoderConfigurer(Mdl,X(1:50,:));
Warning: Default response is removed to support learnerCoderConfigurer. The model will predict NaNs for observations with missing values.
configurer は、RegressionSVM オブジェクトのコーダー コンフィギュアラーである RegressionSVMCoderConfigurer オブジェクトです。
パラメーターのコーダー属性の指定
生成されたコードのパラメーターをモデルの再学習後に更新できるようにするため、SVM 回帰モデルのパラメーターのコーダー属性を指定します。この例では、生成されたコードに渡す予測子データのコーダー属性と、SVM 回帰モデルのサポート ベクターのコーダー属性を指定します。
はじめに、生成されたコードが任意の個数の観測値を受け入れるように、X のコーダー属性を指定します。属性 SizeVector および VariableDimensions を変更します。属性 SizeVector は、予測子データのサイズの上限を指定し、属性 VariableDimensions は、予測子データの各次元が可変サイズと固定サイズのどちらであるかを指定します。
configurer.X.SizeVector = [Inf 2]; configurer.X.VariableDimensions = [true false];
1 番目の次元のサイズは、観測値の個数です。このケースでは、サイズの上限が Inf であり、サイズが可変、つまり X の観測値の個数が任意であることを指定します。この指定は、コードを生成するときに観測値の個数が不明である場合に便利です。
2 番目の次元のサイズは、予測子変数の個数です。この値は、機械学習モデルに対し固定でなければなりません。X には 2 つの予測子が含まれているので、属性 SizeVector の値は 2、属性 VariableDimensions の値は false でなければなりません。
新しいデータまたは異なる設定を使用して SVM モデルに再学習をさせた場合、サポート ベクターの個数が変化する可能性があります。したがって、生成されたコードのサポート ベクターを更新できるように SupportVectors のコーダー属性を指定します。
configurer.SupportVectors.SizeVector = [250 2];
SizeVector attribute for Alpha has been modified to satisfy configuration constraints.
configurer.SupportVectors.VariableDimensions = [true false];
VariableDimensions attribute for Alpha has been modified to satisfy configuration constraints.
SupportVectors のコーダー属性が変更されると、Alpha のコーダー属性が構成の制約を満たすように変更されます。あるパラメーターのコーダー属性の変更によって構成の制約を満たすために他の従属パラメーターの変更が必要になる場合、従属パラメーターのコーダー属性は変更されます。
コードの生成
C/C++ コードを生成するには、適切に設定されている C/C++ コンパイラにアクセスできなければなりません。MATLAB Coder は、サポートされているインストール済みのコンパイラを探して使用します。mex -setup を使用すると、既定のコンパイラを表示および変更できます。詳細は、既定のコンパイラの変更を参照してください。
generateCodeを使用して、SVM 回帰モデル (Mdl) の関数 predict および update について、既定の設定でコードを生成します。
generateCode(configurer)
generateCode creates these files in output folder: 'initialize.m', 'predict.m', 'update.m', 'RegressionSVMModel.mat' Code generation successful.
generateCode は、コードを生成するために必要な MATLAB ファイルを生成します。これには、Mdl の関数 predict および update にそれぞれ対応する 2 つのエントリポイント関数 predict.m および update.m が含まれます。次に generateCode は、2 つのエントリポイント関数に対して RegressionSVMModel という名前の MEX 関数を codegen\mex\RegressionSVMModel フォルダー内に作成し、この MEX 関数を現在のフォルダーにコピーします。
生成されたコードの確認
予測子データを渡して、Mdl の関数 predict と MEX 関数の関数 predict が同じ予測応答を返すかどうかを確認します。複数のエントリポイントがある MEX 関数内のエントリポイント関数を呼び出すため、1 番目の入力引数として関数名を指定します。
yfit = predict(Mdl,X);
yfit_mex = RegressionSVMModel('predict',X);yfit と比較すると、yfit_mex には丸めによる差が含まれている場合があります。このような場合は、小さい誤差を許容して yfit と yfit_mex を比較します。
find(abs(yfit-yfit_mex) > 1e-6)
ans = 0×1 empty double column vector
この比較により、許容誤差 1e–6 内で yfit と yfit_mex が等しいことを確認します。
モデルの再学習と生成コード内のパラメーターの更新
データ セット全体を使用してモデルに再学習をさせます。
retrainedMdl = fitrsvm(X,Y, ... 'KernelFunction','gaussian','KernelScale','auto');
validatedUpdateInputs を使用して、更新するパラメーターを抽出します。この関数は、retrainedMdl 内の修正されたモデル パラメーターを判別し、修正されたパラメーター値がパラメーターのコーダー属性を満たすかどうかを検証します。
params = validatedUpdateInputs(configurer,retrainedMdl);
Warning: Default response is removed to support learnerCoderConfigurer. The model will predict NaNs for observations with missing values.
生成されたコード内のパラメーターを更新します。
RegressionSVMModel('update',params)生成されたコードの確認
retrainedMdl の関数 predict の出力と、更新した MEX 関数の関数 predict の出力を比較します。
yfit = predict(retrainedMdl,X);
yfit_mex = RegressionSVMModel('predict',X);
find(abs(yfit-yfit_mex) > 1e-6)ans = 0×1 empty double column vector
この比較により、許容誤差 1e-6 内で yfit と yfit_mex が等しいことを確認します。
データ セットの一部を使用して回帰木に学習させ、モデルについてコーダー コンフィギュアラーを作成します。コーダー コンフィギュアラーのプロパティを使用してモデル パラメーターのコーダー属性を指定します。コーダー コンフィギュアラーのオブジェクト関数を使用して、新しい予測子データについて応答を予測する C コードを生成します。その後、データ セット全体を使用してモデルに再学習をさせ、コードを再生成せずに、生成されたコードのパラメーターを更新します。
モデルの学習
carbig データ セットを読み込み、観測値の半分を使用して回帰木モデルに学習させます。
load carbig X = [Displacement Horsepower Weight]; Y = MPG; rng('default') % For reproducibility n = length(Y); idxTrain = randsample(n,n/2); XTrain = X(idxTrain,:); YTrain = Y(idxTrain); Mdl = fitrtree(XTrain,YTrain);
Mdl は、RegressionTree オブジェクトです。
コーダー コンフィギュアラーの作成
learnerCoderConfigurer を使用して、RegressionTree モデルについてコーダー コンフィギュアラーを作成します。予測子データ XTrain を指定します。関数 learnerCoderConfigurer は、入力 XTrain を使用して、関数 predict の入力のコーダー属性を設定します。また、生成されるコードが予測される応答および予測子のノード数を返すようにするため、出力の個数を 2 に設定します。
configurer = learnerCoderConfigurer(Mdl,XTrain,'NumOutputs',2);configurer は、RegressionTree オブジェクトのコーダー コンフィギュアラーである RegressionTreeCoderConfigurer オブジェクトです。
パラメーターのコーダー属性の指定
生成されたコードのパラメーターをモデルの再学習後に更新できるようにするため、回帰木モデルのパラメーターのコーダー属性を指定します。
生成されたコードが任意の個数の観測値を受け入れるように、configurer の X プロパティのコーダー属性を指定します。属性 SizeVector および VariableDimensions を変更します。属性 SizeVector は、予測子データのサイズの上限を指定し、属性 VariableDimensions は、予測子データの各次元が可変サイズと固定サイズのどちらであるかを指定します。
configurer.X.SizeVector = [Inf 3]; configurer.X.VariableDimensions
ans = 1×2 logical array
1 0
1 番目の次元のサイズは、観測値の個数です。属性 SizeVector の値を Inf に設定すると、ソフトウェアは属性 VariableDimensions の値を 1 に変更します。言い換えると、サイズの上限は Inf であり、サイズは可変です。これは、予測子データが任意の数の観測値をもつことができることを意味しています。この指定は、コードを生成するときに観測値の個数が不明である場合に便利です。
2 番目の次元のサイズは、予測子変数の個数です。この値は、1 つの機械学習モデルに対して固定でなければなりません。予測子データには 3 個の予測子が含まれているため、属性 SizeVector の値は 3、属性 VariableDimensions の値は 0 でなければなりません。
新しいデータまたは異なる設定を使用して木モデルに再学習させる場合、木のノードの数が変化する可能性があります。したがって、生成されたコードでノードの数を更新できるように、Children、CutPoint、CutPredictorIndex または NodeMean のいずれかのプロパティの SizeVector 属性の最初の次元を指定します。そうすると、他のプロパティは自動的に変更されます。
たとえば、NodeMean プロパティの SizeVector 属性の最初の値を Inf に設定します。ソフトウェアによって Children、CutPoint および CutPredictorIndex の SizeVector 属性および VariableDimensions 属性が変更され、木のノード数の新しい上限に合致するようになります。さらに、NodeMean の VariableDimensions 属性の最初の値が 1 に変更されます。
configurer.NodeMean.SizeVector = [Inf 1];
SizeVector attribute for Children has been modified to satisfy configuration constraints. SizeVector attribute for CutPoint has been modified to satisfy configuration constraints. SizeVector attribute for CutPredictorIndex has been modified to satisfy configuration constraints. VariableDimensions attribute for Children has been modified to satisfy configuration constraints. VariableDimensions attribute for CutPoint has been modified to satisfy configuration constraints. VariableDimensions attribute for CutPredictorIndex has been modified to satisfy configuration constraints.
configurer.NodeMean.VariableDimensions
ans = 1×2 logical array
1 0
コードの生成
C/C++ コードを生成するには、適切に設定されている C/C++ コンパイラにアクセスできなければなりません。MATLAB Coder は、サポートされているインストール済みのコンパイラを探して使用します。mex -setup を使用すると、既定のコンパイラを表示および変更できます。詳細は、既定のコンパイラの変更を参照してください。
回帰木モデル (Mdl) の関数 predict および update のコードを生成します。
generateCode(configurer)
generateCode creates these files in output folder: 'initialize.m', 'predict.m', 'update.m', 'RegressionTreeModel.mat' Code generation successful.
関数 generateCode は、以下の処理を実行します。
コードを生成するために必要な MATLAB ファイルを生成する。これには、
Mdlの関数predictおよびupdateにそれぞれ対応する 2 つのエントリポイント関数predict.mおよびupdate.mが含まれます。2 つのエントリポイント関数に対して、
RegressionTreeModelという名前の MEX 関数を作成する。MEX 関数のコードを
codegen\mex\RegressionTreeModelフォルダーに作成する。MEX 関数を現在のフォルダーにコピーする。
生成されたコードの確認
予測子データを渡して、Mdl の関数 predict と MEX 関数の関数 predict が同じ予測応答を返すかどうかを確認します。複数のエントリポイントがある MEX 関数内のエントリポイント関数を呼び出すため、1 番目の入力引数として関数名を指定します。
[Yfit,node] = predict(Mdl,XTrain);
[Yfit_mex,node_mex] = RegressionTreeModel('predict',XTrain);Yfit を Yfit_mex と、node を node_mex と比較します。
max(abs(Yfit-Yfit_mex),[],'all')ans = 0
isequal(node,node_mex)
ans = logical
1
一般的に、Yfit と比較すると、Yfit_mex には丸めによる差が含まれている可能性があります。この場合では、比較によって Yfit と Yfit_mex が等しいことが確かめられます。
isequal は、すべての入力引数が等しい場合に logical 1 (true) を返します。この比較により、Mdl の関数 predict と MEX 関数の関数 predict が同じノード数を返すことを確認します。
モデルの再学習と生成コード内のパラメーターの更新
データ セット全体を使用してモデルに再学習をさせます。
retrainedMdl = fitrtree(X,Y);
validatedUpdateInputs を使用して、更新するパラメーターを抽出します。この関数は、retrainedMdl 内の修正されたモデル パラメーターを判別し、修正されたパラメーター値がパラメーターのコーダー属性を満たすかどうかを検証します。
params = validatedUpdateInputs(configurer,retrainedMdl);
生成されたコード内のパラメーターを更新します。
RegressionTreeModel('update',params)生成されたコードの確認
retrainedMdl の関数 predict の出力引数と、更新した MEX 関数の関数 predict の出力引数を比較します。
[Yfit,node] = predict(retrainedMdl,X); [Yfit_mex,node_mex] = RegressionTreeModel('predict',X); max(abs(Yfit-Yfit_mex),[],'all')
ans = 0
isequal(node,node_mex)
ans = logical
1
この比較により、予測された応答およびノード数が等しいことを確認します。
入力引数
機械学習モデル。モデル オブジェクトを指定します。サポートされるモデルは次の表に記載されています。
| モデル | モデル オブジェクト |
|---|---|
| マルチクラス分類用の二分決定木 | CompactClassificationTree |
| 1 クラスおよびバイナリ分類用の SVM | CompactClassificationSVM |
| バイナリ分類用の線形モデル | ClassificationLinear |
| SVM モデルおよび線形モデル用のマルチクラス モデル | CompactClassificationECOC |
| 回帰用の二分決定木 | CompactRegressionTree |
| サポート ベクター マシン (SVM) 回帰 | CompactRegressionSVM |
| 線形回帰 | RegressionLinear |
機械学習モデルのコード生成に関する使用上の注意事項および制限事項については、モデル オブジェクトのページの「コード生成」セクションを参照してください。
機械学習モデル内の更新するパラメーター。更新する各パラメーターについてのフィールドをもつ構造体を指定します。
関数 validatedUpdateInputs を使用して params を作成します。この関数は、再学習済みモデルの修正されたパラメーターを検出し、修正されたパラメーターの値がパラメーターのコーダー属性を満たすかどうかを検証し、更新するパラメーターを構造体として返します。
更新できるパラメーターは、次の表に記載されているように、機械学習モデルによって異なります。
| モデル | 更新するパラメーター |
|---|---|
| マルチクラス分類用の二分決定木 | Children, ClassProbability, Cost, CutPoint, CutPredictorIndex, Prior |
| 1 クラスおよびバイナリ分類用の SVM |
|
| バイナリ分類用の線形モデル | Beta, Bias, Cost, Prior |
| SVM モデルおよび線形モデル用のマルチクラス モデル | |
| 回帰用の二分決定木 | Children, CutPoint, CutPredictorIndex, NodeMean |
| SVM 回帰 |
|
| 線形回帰 | Beta, Bias |
出力引数
ヒント
モデルに再学習をさせるときに、次の表に記載されている名前と値のペアの引数のいずれかを変更した場合、
updateを使用してパラメーターを更新することはできません。C/C++ コードを再生成しなければなりません。モデル 更新がサポートされない引数 マルチクラス分類用の二分決定木 fitctreeの引数 —ClassNames、ScoreTransform1 クラスおよびバイナリ分類用の SVM fitcsvmの引数 —ClassNames、KernelFunction、PolynomialOrder、ScoreTransform、Standardizeバイナリ分類用の線形モデル fitclinearの引数 —ClassNames、ScoreTransformSVM モデルおよび線形モデル用のマルチクラス モデル fitcecocの引数 —ClassNames、Codingfitcecocのバイナリ学習器をテンプレート オブジェクト (Learnersを参照) として指定する場合、各バイナリ学習器について、以下のものを変更することはできません。回帰用の二分決定木 fitrtreeの引数 —ResponseTransformSVM 回帰 fitrsvmの引数 —KernelFunction、PolynomialOrder、ResponseTransform、Standardize線形回帰 fitrlinearの引数 —ResponseTransformコーダー コンフィギュアラーのワークフローで
generateCodeを使用して、エントリポイント関数update.mと、そのエントリポイント関数の MEX 関数の両方を作成します。MEX 関数の名前がmyModelであると仮定して、この構文を使用してupdateを呼び出します。myModel('update',params)このページで説明している構文がエントリポイント関数でどのように使用されているかを確認するには、関数
typeを使用してupdate.mファイルおよびinitialize.mファイルの内容を表示します。type update.m type initialize.m
update.mファイルおよびinitialize.mファイルの内容を表示する例については、コーダー コンフィギュアラーの使用によるコードの生成を参照してください。
アルゴリズム
コーダー コンフィギュアラーのワークフローで、update の入力引数 Mdl は、loadLearnerForCoder で返されるモデルです。このモデルと updatedMdl オブジェクトは、主に予測に必要なプロパティを含む、縮小した分類モデルまたは回帰モデルです。
拡張機能
使用上の注意事項および制限事項:
learnerCoderConfigurerを使用してコーダー コンフィギュアラーを作成してから、オブジェクト関数generateCodeを使用してpredictおよびupdateに対するコードを生成します。機械学習モデル
Mdlのコード生成に関する使用上の注意事項および制限事項については、モデル オブジェクトのページの「コード生成」セクションを参照してください。モデル モデル オブジェクト マルチクラス分類用の二分決定木 CompactClassificationTree1 クラスおよびバイナリ分類用の SVM CompactClassificationSVMバイナリ分類用の線形モデル ClassificationLinearSVM モデルおよび線形モデル用のマルチクラス モデル CompactClassificationECOC回帰用の二分決定木 CompactRegressionTreeサポート ベクター マシン (SVM) 回帰 CompactRegressionSVM線形回帰 RegressionLinear
詳細は、統計と機械学習の関数のコード生成の紹介を参照してください。
バージョン履歴
R2018b で導入
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Web サイトの選択
Web サイトを選択すると、翻訳されたコンテンツにアクセスし、地域のイベントやサービスを確認できます。現在の位置情報に基づき、次のサイトの選択を推奨します:
また、以下のリストから Web サイトを選択することもできます。
最適なサイトパフォーマンスの取得方法
中国のサイト (中国語または英語) を選択することで、最適なサイトパフォーマンスが得られます。その他の国の MathWorks のサイトは、お客様の地域からのアクセスが最適化されていません。
南北アメリカ
- América Latina (Español)
- Canada (English)
- United States (English)
ヨーロッパ
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)