このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitrlinear
高次元データに対する線形回帰モデルの当てはめ
構文
説明
fitrlinear は、高次元の完全なまたはスパース予測子データを使用して効率的に線形回帰モデルに学習をさせます。使用可能な線形回帰モデルには、正則化されたサポート ベクター マシン (SVM) と最小二乗回帰法があります。fitrlinear は、計算時間を短縮する手法 (確率的勾配降下法など) を使用して目的関数を最小化します。
多数の予測子変数が含まれている高次元データ セットに対する計算時間を短縮するには、fitrlinear を使用して線形回帰モデルに学習をさせます。低~中次元の予測子データ セットについては、低次元データの代替方法を参照してください。
Mdl = fitrlinear(Tbl,ResponseVarName)Tbl 内の予測子変数と Tbl.ResponseVarName 内の応答値を使用して、線形回帰モデルを返します。
Mdl = fitrlinear(X,Y,Name,Value)'Kfold' を使用して交差検証を行うことをお勧めします。交差検証の結果により、モデルがどの程度一般化を行うかを判断します。
[ は、Mdl,FitInfo,HyperparameterOptimizationResults] = fitrlinear(___)OptimizeHyperparameters が指定されている場合に、ハイパーパラメーターの最適化の結果も返します。
[ は、名前と値の引数 Mdl,FitInfo,AggregateOptimizationResults] = fitrlinear(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
SVM、双対 SGD およびリッジ正則化を使用して線形回帰モデルに学習をさせます。
次のモデルにより、10000 個の観測値をシミュレートします。
は、10% の要素が非ゼロ標準正規である 10000 行 1000 列のスパース行列です。
e は、平均が 0、標準偏差が 0.3 のランダムな正規誤差です。
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);線形回帰モデルに学習をさせます。既定の設定では、fitrlinear はリッジ ペナルティがあるサポート ベクター マシンを使用し、SVM 用の双対 SGD を使用して最適化を行います。近似の要約を抽出して、最適化アルゴリズムによるモデルがどの程度データに当てはまるかを判断します。
[Mdl,FitInfo] = fitrlinear(X,Y)
Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0056
Lambda: 1.0000e-04
Learner: 'svm'
Properties, Methods
FitInfo = struct with fields:
Lambda: 1.0000e-04
Objective: 0.2725
PassLimit: 10
NumPasses: 10
BatchLimit: []
NumIterations: 100000
GradientNorm: NaN
GradientTolerance: 0
RelativeChangeInBeta: 0.4907
BetaTolerance: 1.0000e-04
DeltaGradient: 1.5816
DeltaGradientTolerance: 0.1000
TerminationCode: 0
TerminationStatus: {'Iteration limit exceeded.'}
Alpha: [10000×1 double]
History: []
FitTime: 0.0675
Solver: {'dual'}
Mdl は RegressionLinear モデルです。Mdl と学習データまたは新しいデータを loss に渡して、標本内平均二乗誤差を調べることができます。または、Mdl と新しい予測子データを predict に渡して、新しい観測値の応答を予測することができます。
FitInfo は、重要な情報として終了ステータス (TerminationStatus) とソルバーによるモデルのデータへの当てはめにかかった時間 (FitTime) が含まれている構造体配列です。FitInfo を使用して、最適化終了時の結果が満足できるものであるかどうかを判断することをお勧めします。この場合、fitrlinear は最大反復回数に達しました。モデルに再学習をさせることもできますが、学習時間は短いので、データを通す回数を増やしてください。または、LBFGS など別のソルバーを試してください。
最小二乗を使用する線形回帰モデルに適した LASSO ペナルティの強度を決定するため、5 分割の交差検証を実装します。
次のモデルにより、10000 個の観測値をシミュレートします。
は、10% の要素が非ゼロ標準正規である 10000 行 1000 列のスパース行列です。
e は、平均が 0、標準偏差が 0.3 のランダムな正規誤差です。
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);~ の範囲で対数間隔で配置された 15 個の正則化強度を作成します。
Lambda = logspace(-5,-1,15);
モデルを交差検証します。実行速度を向上させるため、予測子データを転置し、観測値が列単位であることを指定します。SpaRSA を使用して目的関数を最適化します。
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','KFold',5,'Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numCLModels = numel(CVMdl.Trained)
numCLModels = 5
CVMdl は RegressionPartitionedLinear モデルです。fitrlinear は 5 分割の交差検証を実装するので、各分割について学習させる 5 つの RegressionLinear モデルが CVMdl に格納されます。
1 番目の学習済み線形回帰モデルを表示します。
Mdl1 = CVMdl.Trained{1}Mdl1 =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×15 double]
Bias: [-0.0049 -0.0049 -0.0049 -0.0049 -0.0049 -0.0048 -0.0044 -0.0037 -0.0030 -0.0031 -0.0033 -0.0036 -0.0041 -0.0051 -0.0071]
Lambda: [1.0000e-05 1.9307e-05 3.7276e-05 7.1969e-05 1.3895e-04 2.6827e-04 5.1795e-04 1.0000e-03 0.0019 0.0037 0.0072 0.0139 0.0268 0.0518 0.1000]
Learner: 'leastsquares'
Properties, Methods
Mdl1 は RegressionLinear モデル オブジェクトです。fitrlinear は最初の 4 つの分割に対して学習を行うことにより Mdl1 を構築しました。Lambda は正則化強度のシーケンスなので、Mdl1 はそれぞれが Lambda の各正則化強度に対応する 15 個のモデルであると考えることができます。
交差検証された MSE を推定します。
mse = kfoldLoss(CVMdl);
Lambda の値が大きくなると、予測子変数がスパースになります。これは回帰モデルの品質として優れています。データ セット全体を使用し、モデルの交差検証を行ったときと同じオプションを指定して、各正則化強度について線形回帰モデルに学習をさせます。モデルごとに非ゼロの係数を特定します。
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
同じ図に、各正則化強度についての交差検証された MSE と非ゼロ係数の頻度をプロットします。すべての変数を対数スケールでプロットします。
figure [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
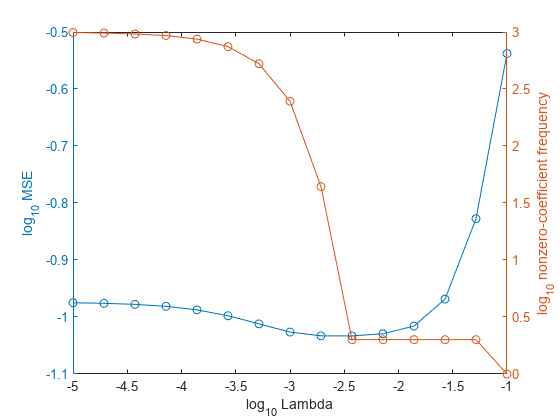
予測子変数のスパース性と MSE の低さのバランスがとれている正則化強度 (Lambda(10) など) のインデックスを選択します。
idxFinal = 10;
最小の MSE に対応するモデルを抽出します。
MdlFinal = selectModels(Mdl,idxFinal)
MdlFinal =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0050
Lambda: 0.0037
Learner: 'leastsquares'
Properties, Methods
idxNZCoeff = find(MdlFinal.Beta~=0)
idxNZCoeff = 2×1
100
200
EstCoeff = Mdl.Beta(idxNZCoeff)
EstCoeff = 2×1
1.0051
1.9965
MdlFinal は、1 つの正則化強度がある RegressionLinear モデルです。非ゼロ係数 EstCoeff は、データをシミュレートした係数に近くなっています。
この例では、fitrlinear を使用して自動的にハイパーパラメーターを最適化する方法を示します。この例では、人為的な (シミュレートされた) データをモデルに対して使用します。
は、10% の要素が非ゼロ標準正規である 10000 行 1000 列のスパース行列です。
e は、平均が 0、標準偏差が 0.3 のランダムな正規誤差です。
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。
再現性を得るために、'expected-improvement-plus' の獲得関数を使用します。
hyperopts = struct('AcquisitionFunctionName','expected-improvement-plus'); [Mdl,FitInfo,HyperparameterOptimizationResults] = fitrlinear(X,Y,... 'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',hyperopts)
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Lambda | Learner |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 1 | Best | 0.10584 | 1.5375 | 0.10584 | 0.10584 | 2.4206e-09 | svm |
| 2 | Best | 0.10564 | 1.1663 | 0.10564 | 0.10564 | 0.001807 | svm |
| 3 | Best | 0.10091 | 0.38098 | 0.10091 | 0.10092 | 2.4681e-09 | leastsquares |
| 4 | Accept | 0.11397 | 0.33001 | 0.10091 | 0.10094 | 0.021027 | leastsquares |
| 5 | Accept | 0.10091 | 0.39719 | 0.10091 | 0.10091 | 2.0258e-09 | leastsquares |
| 6 | Accept | 0.45312 | 0.65637 | 0.10091 | 0.10091 | 9.8803 | svm |
| 7 | Accept | 0.10582 | 1.2603 | 0.10091 | 0.10091 | 9.6038e-06 | svm |
| 8 | Best | 0.10091 | 0.35157 | 0.10091 | 0.10087 | 1.6009e-05 | leastsquares |
| 9 | Accept | 0.44998 | 0.21356 | 0.10091 | 0.10089 | 9.9615 | leastsquares |
| 10 | Best | 0.10069 | 0.32634 | 0.10069 | 0.10067 | 0.00079258 | leastsquares |
| 11 | Accept | 0.10586 | 1.1769 | 0.10069 | 0.10065 | 9.7512e-08 | svm |
| 12 | Accept | 0.10091 | 0.32572 | 0.10069 | 0.10085 | 3.0897e-07 | leastsquares |
| 13 | Accept | 0.10577 | 1.2404 | 0.10069 | 0.10085 | 0.00019626 | svm |
| 14 | Best | 0.10062 | 0.35156 | 0.10062 | 0.10043 | 0.0037706 | leastsquares |
| 15 | Accept | 0.10091 | 0.32826 | 0.10062 | 0.10085 | 2.4399e-08 | leastsquares |
| 16 | Accept | 0.10091 | 0.3498 | 0.10062 | 0.10087 | 2.4005e-06 | leastsquares |
| 17 | Accept | 0.10091 | 0.3369 | 0.10062 | 0.10089 | 1.0029e-09 | leastsquares |
| 18 | Accept | 0.10584 | 1.2046 | 0.10062 | 0.10089 | 1.0049e-09 | svm |
| 19 | Accept | 0.10088 | 0.3595 | 0.10062 | 0.10089 | 0.00010204 | leastsquares |
| 20 | Accept | 0.10583 | 1.2326 | 0.10062 | 0.10089 | 9.8999e-07 | svm |
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Lambda | Learner |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 21 | Best | 0.10052 | 0.32086 | 0.10052 | 0.10025 | 0.002124 | leastsquares |
| 22 | Accept | 0.10091 | 0.3624 | 0.10052 | 0.10024 | 8.7079e-08 | leastsquares |
| 23 | Best | 0.10052 | 0.34039 | 0.10052 | 0.10033 | 0.0021352 | leastsquares |
| 24 | Accept | 0.10091 | 0.37178 | 0.10052 | 0.10033 | 8.0672e-09 | leastsquares |
| 25 | Accept | 0.10052 | 0.36927 | 0.10052 | 0.10038 | 0.0021099 | leastsquares |
| 26 | Accept | 0.10091 | 0.36543 | 0.10052 | 0.10038 | 8.5163e-07 | leastsquares |
| 27 | Accept | 0.1009 | 0.34399 | 0.10052 | 0.10038 | 3.8212e-05 | leastsquares |
| 28 | Accept | 0.31858 | 0.9691 | 0.10052 | 0.10046 | 0.17205 | svm |
| 29 | Accept | 0.10574 | 1.22 | 0.10052 | 0.10047 | 0.00070859 | svm |
| 30 | Accept | 0.10082 | 0.38007 | 0.10052 | 0.10047 | 0.00028825 | leastsquares |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 32.7363 seconds
Total objective function evaluation time: 18.5696
Best observed feasible point:
Lambda Learner
_________ ____________
0.0021352 leastsquares
Observed objective function value = 0.10052
Estimated objective function value = 0.10047
Function evaluation time = 0.34039
Best estimated feasible point (according to models):
Lambda Learner
_________ ____________
0.0021352 leastsquares
Estimated objective function value = 0.10047
Estimated function evaluation time = 0.34314


Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0071
Lambda: 0.0021
Learner: 'leastsquares'
Properties, Methods
FitInfo = struct with fields:
Lambda: 0.0021
Objective: 0.0472
IterationLimit: 1000
NumIterations: 15
GradientNorm: 2.4347e-06
GradientTolerance: 1.0000e-06
RelativeChangeInBeta: 3.3860e-05
BetaTolerance: 1.0000e-04
DeltaGradient: []
DeltaGradientTolerance: []
TerminationCode: 1
TerminationStatus: {'Tolerance on coefficients satisfied.'}
History: []
FitTime: 0.0563
Solver: {'lbfgs'}
HyperparameterOptimizationResults =
BayesianOptimization with properties:
ObjectiveFcn: @createObjFcn/inMemoryObjFcn
VariableDescriptions: [3×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.1005
XAtMinObjective: [1×2 table]
MinEstimatedObjective: 0.1005
XAtMinEstimatedObjective: [1×2 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 32.7363
NextPoint: [1×2 table]
XTrace: [30×2 table]
ObjectiveTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
この最適化手法は交差検証の使用による適切な LASSO ペナルティの特定で示されているものよりシンプルですが、モデルの複雑度と交差検証損失との間のトレードオフはできません。
入力引数
名前と値の引数
出力引数
詳細
ヒント
観測値が列に対応するように予測子行列を配置して
'ObservationsIn','columns'を指定することをお勧めします。このようにすると、最適化実行時間が大幅に短縮される可能性があります。予測子データに含まれている観測値の数が少なく、予測子変数の数が多い場合、次のようにします。
'PostFitBias',trueを指定します。ソルバーが SGD または ASGD の場合、
PassLimitを 1 より大きい正の整数 (5 や 10 など) に設定します。このように設定すると、多くの場合に精度が向上します。
ソルバーが SGD または ASGD の場合、
BatchSizeは収束速度に影響を与えます。BatchSizeが小さすぎる場合、fitrlinearが最小値を計算するための反復回数は多くなりますが、反復ごとの勾配の計算時間は短くなります。BatchSizeが大きすぎる場合、fitrlinearが最小値を計算するための反復回数は少なくなりますが、反復ごとの勾配の計算時間は長くなります。
学習率 (
LearnRateを参照) が大きいと、最小値への収束が高速になりますが、発散 (最小値の限度を超える状態) の可能性があります。学習率が小さいと最小値への収束が保証されますが、終了までに時間がかかる可能性があります。LASSO ペナルティを使用する場合は、さまざまな値の
TruncationPeriodを試してください。たとえば、TruncationPeriodを1、10に設定してから100に設定します。効率のため、
fitrlinearは予測子データを標準化しません。Xを標準化して観測値が列に対応するように配置するには、次のように入力します。X = normalize(X,2);
観測値が行に対応するように配置する場合は、次のように入力します。
X = normalize(X);
メモリを節約するため、このコードは元の予測子データを標準化されたデータに置き換えます。
モデルに学習をさせた後で、新しいデータについて応答を予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
ValidationDataを指定した場合、目的関数の最適化時に以下が行われます。fitrlinearは、現在のモデルを使用してValidationDataの検証損失を定期的に推定し、最小の推定値を追跡します。fitrlinearは、検証損失を推定するときに、推定値を最小の推定値と比較します。以後の検証損失の推定値が最小推定値の 5 倍より大きくなった場合、
fitrlinearは最適化を終了します。
ValidationDataを指定して交差検証ルーチン (CrossVal、CVPartition、HoldoutまたはKFold) を実装した場合、次のようになります。fitrlinearは、学習データの分割を使用してモデルに学習をさせます。目的関数の最適化時に、fitrlinearは最適化を終了させるための他の可能な方法としてValidationDataを使用します (詳細については、前の項目を参照)。終了条件が満たされると、
fitrlinearは最適化された線形係数および切片に基づいて学習済みのモデルを構築します。k 分割交差検証を実装した場合、
fitrlinearが網羅していない学習セット分割があると、fitrlinearはステップ 2 に戻り、次の学習セット分割を使用して学習を行います。それ以外の場合、
fitrlinearは学習を終了させ、交差検証済みのモデルを返します。
交差検証済みモデルの品質を判断できます。以下に例を示します。
ステップ 1 のホールドアウトまたは分割外データを使用して検証損失を決定するには、交差検証済みのモデルを
kfoldLossに渡します。ステップ 1 のホールドアウトまたは分割外データで観測値を予測するには、交差検証済みのモデルを
kfoldPredictに渡します。
参照
[1] Ho, C. H. and C. J. Lin. “Large-Scale Linear Support Vector Regression.” Journal of Machine Learning Research, Vol. 13, 2012, pp. 3323–3348.
拡張機能
バージョン履歴
R2016a で導入参考
fitrsvm | fitlm | lasso | ridge | fitclinear | predict | kfoldPredict | kfoldLoss | RegressionLinear | RegressionPartitionedLinear