lassoglm
一般化線形モデルに対する LASSO または Elastic Net 正則化
構文
説明
B = lassoglm(X,y,distr,Name,Value)Alpha=0.5 は、パラメーター Alpha が 0.5 に等しい Elastic Net を正則化の手法として設定します。
例
冗長な予測子があるデータ セットを作成し、lassoglm を使用してこれらの予測子を識別します。
100 個の観測値と 10 個の予測子が含まれているランダムな行列 X を作成します。予測子のうち 4 つのみと小量のノイズを使用して、正規分布に従う応答 y を作成します。
rng default X = randn(100,10); weights = [0.6;0.5;0.7;0.4]; y = X(:,[2 4 5 7])*weights + randn(100,1)*0.1; % Small added noise
LASSO 正則化を実行します。
B = lassoglm(X,y);
B 内の 75 番目の Lambda の値について係数ベクトルを求めます。
B(:,75)
ans = 10×1
0
0.5431
0
0.3944
0.6173
0
0.3473
0
0
0
lassoglm は冗長予測子を識別して、削除します。
ポアソン モデルからデータを作成し、lassoglm を使用して重要な予測子を特定します。
20 個の予測子が含まれているデータを作成します。予測子のうち 3 つのみと定数を使用して、ポアソン応答変数を作成します。
rng default % For reproducibility X = randn(100,20); weights = [.4;.2;.3]; mu = exp(X(:,[5 10 15])*weights + 1); y = poissrnd(mu);
データのポアソン回帰モデルの交差検証 LASSO 正則化を構築します。
[B,FitInfo] = lassoglm(X,y,'poisson','CV',10);
Lambda 正則化パラメーターの効果を確認するために交差検証プロットを調べます。
lassoPlot(B,FitInfo,plottype="CV"); legend("show") % Show legend
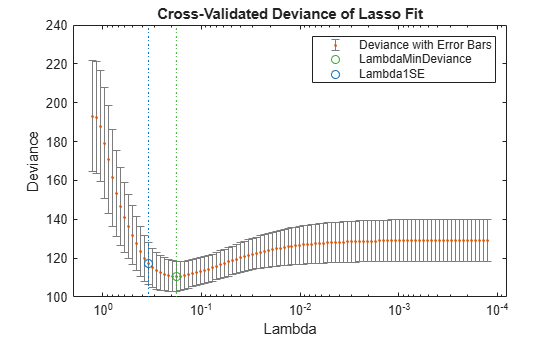
緑の円と点線は、交差検証誤差が最小になる Lambda を示しています。青の円と点線は、最小交差検証誤差に 1 標準偏差を加算した点を示しています。
識別された 2 つの点に対応する非ゼロのモデル係数を検出します。
idxLambdaMinDeviance = FitInfo.IndexMinDeviance; mincoefs = find(B(:,idxLambdaMinDeviance))
mincoefs = 7×1
3
5
6
10
11
15
16
idxLambda1SE = FitInfo.Index1SE; min1coefs = find(B(:,idxLambda1SE))
min1coefs = 3×1
5
10
15
最小値に 1 標準誤差を加えた点の係数は、データを作成するために使用した係数そのものです。
lassoglm を使用して、学生が最後の試験で B 以上を取ったかどうかを予測します。
examgrades データ セットを読み込みます。最後の試験成績を logical ベクトルに変換します。1 は 80 点以上の成績を、0 は 80 点未満の成績を表します。
load examgrades
X = grades(:,1:4);
y = grades(:,5);
yBinom = (y>=80);データを学習セットとテスト セットに分割します。
rng default % Set the seed for reproducibility c = cvpartition(yBinom,HoldOut=0.3); idxTrain = training(c,1); idxTest = ~idxTrain; XTrain = X(idxTrain,:); yTrain = yBinom(idxTrain); XTest = X(idxTest,:); yTest = yBinom(idxTest);
学習データに対する 3 分割の交差検証を使用して、一般化線形モデル回帰について LASSO 正則化を実行します。y 内の値は二項分布に従うと仮定します。予期される逸脱度が最小である Lambda に対応するモデル係数を選択します。
[B,FitInfo] = lassoglm(XTrain,yTrain,"binomial",CV=3);
idxLambdaMinDeviance = FitInfo.IndexMinDeviance;
B0 = FitInfo.Intercept(idxLambdaMinDeviance);
coef = [B0; B(:,idxLambdaMinDeviance)]coef = 5×1
-21.1911
0.0235
0.0670
0.0693
0.0949
前の手順で求めたモデル係数を使用して、テスト データについて試験成績を予測します。'logit' を使用して、二項応答のリンク関数を指定します。予測値を logical ベクトルに変換します。
yhat = glmval(coef,XTest,"logit");
yhatBinom = (yhat>=0.5);混同行列を使用して、予測の精度を判断します。
c = confusionchart(yTest,yhatBinom);

この関数は、31 個の試験成績を正しく予測しています。しかし、1 人の学生を B 以上、4 人の学生を B 未満の成績として誤って予測しています。
N 個の p 次元正規変数が含まれている行列 X を作成します。ここで N は大きく、p = 1000 です。モデル y = X*beta + noise から応答ベクトル y を作成します。ここで beta は 50% が非ゼロ値である定数のベクトルです。
rng default % For reproducibility N = 1e4; % Number of samples p = 1e3; % Number of features X = randn(N,p); beta = 1 + 3*rand(p,1); % Multiplicative coefficients activep = randperm(p,p/2); % 50% nonzero coefficients y = X(:,activep)*beta(activep) + randn(N,1)*0.1; % Add noise
共分散行列を使用せずに LASSO 当てはめを作成します。作成時間を計ります。
B = lassoglm(X,y,"normal",UseCovariance=false); % Warm up lasso for reliable timing data tic B = lassoglm(X,y,"normal",UseCovariance=false); timefalse = toc
timefalse = 2.2411
共分散行列を使用して LASSO 当てはめを作成します。作成時間を計ります。
B2 = lassoglm(X,y,"normal",UseCovariance=true); % Warm up lasso for reliable timing data tic B2 = lassoglm(X,y,"normal",UseCovariance=true); timetrue = toc
timetrue = 0.5796
共分散行列を使用した当てはめ時間は、使用しない場合の時間より小さいです。共分散行列を使用した結果の高速化係数を表示します。
speedup = timefalse/timetrue
speedup = 3.8668
返された係数 B および B2 が似ていることを確認します。
norm(B-B2)/norm(B)
ans = 3.6571e-15
結果は実質的に同一です。
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
参照
[1] Tibshirani, R. “Regression Shrinkage and Selection via the Lasso.” Journal of the Royal Statistical Society. Series B, Vol. 58, No. 1, 1996, pp. 267–288.
[2] Zou, H., and T. Hastie. “Regularization and Variable Selection via the Elastic Net.” Journal of the Royal Statistical Society. Series B, Vol. 67, No. 2, 2005, pp. 301–320.
[4] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning. 2nd edition. New York: Springer, 2008.
[5] Dobson, A. J. An Introduction to Generalized Linear Models. 2nd edition. New York: Chapman & Hall/CRC Press, 2002.
[6] McCullagh, P., and J. A. Nelder. Generalized Linear Models. 2nd edition. New York: Chapman & Hall/CRC Press, 1989.
[7] Collett, D. Modelling Binary Data. 2nd edition. New York: Chapman & Hall/CRC Press, 2003.
拡張機能
バージョン履歴
R2012a で導入