loss
クラス: ClassificationLinear
線形分類モデルの分類損失
説明
L = loss(Mdl,Tbl,ResponseVarName)Tbl 内の予測子データと Tbl.ResponseVarName 内の真のクラス ラベルに対する分類損失を返します。
L = loss(___,Name,Value)
メモ
X または Tbl の予測子データに欠損値があり、LossFun が "classifcost"、"classiferror"、または "mincost" に設定されていない場合、関数 loss で NaN が返されることがあります。詳細については、欠損値がある予測子データに対して loss で NaN が返されることがあるを参照してください。
入力引数
名前と値の引数
出力引数
例
NLP のデータ セットを読み込みます。
load nlpdataX は予測子データのスパース行列、Y はクラス ラベルの categorical ベクトルです。データには 2 つを超えるクラスがあります。
モデルでは、ある Web ページの単語数が Statistics and Machine Learning Toolbox™ ドキュメンテーションによるものであるかどうかを識別できなければなりません。したがって、Statistics and Machine Learning Toolbox™ のドキュメンテーション Web ページに対応するラベルを識別します。
Ystats = Y == 'stats';あるドキュメンテーション Web ページの単語数が Statistics and Machine Learning Toolbox™ ドキュメンテーションによるものであるかどうかを識別できるバイナリ線形分類モデルに学習をさせます。観測値の 30% をホールドアウトするように指定します。SpaRSA を使用して目的関数を最適化します。
rng(1); % For reproducibility CVMdl = fitclinear(X,Ystats,'Solver','sparsa','Holdout',0.30); CMdl = CVMdl.Trained{1};
CVMdl は ClassificationPartitionedLinear モデルです。これには Trained プロパティが含まれています。これは 1 行 1 列の cell 配列で、学習セットにより学習させた ClassificationLinear モデルが格納されています。
学習データとテスト データを分割の定義から抽出します。
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
学習標本およびテスト標本の分類誤差を推定します。
ceTrain = loss(CMdl,X(trainIdx,:),Ystats(trainIdx))
ceTrain = 1.3572e-04
ceTest = loss(CMdl,X(testIdx,:),Ystats(testIdx))
ceTest = 5.2804e-04
CMdl 内の正則化強度は 1 つなので、ceTrain と ceTest は数値スカラーになります。
NLP のデータ セットを読み込みます。テスト標本の分類損失の推定で説明されているようにデータを前処理し、予測子データを転置します。
load nlpdata Ystats = Y == 'stats'; X = X';
バイナリ線形分類モデルに学習をさせます。観測値の 30% をホールドアウトするように指定します。SpaRSA を使用して目的関数を最適化します。予測子の観測値が列に対応することを指定します。
rng(1); % For reproducibility CVMdl = fitclinear(X,Ystats,'Solver','sparsa','Holdout',0.30,... 'ObservationsIn','columns'); CMdl = CVMdl.Trained{1};
CVMdl は ClassificationPartitionedLinear モデルです。これには Trained プロパティが含まれています。これは 1 行 1 列の cell 配列で、学習セットにより学習させた ClassificationLinear モデルが格納されています。
学習データとテスト データを分割の定義から抽出します。
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
次の線形損失を評価する無名関数を作成します。
は観測値 j の重み、 は応答 j (陰性クラスの場合は -1、それ以外の場合は 1)、 は観測値 j の生の分類スコアです。カスタム損失関数は特定の形式で記述しなければなりません。カスタム損失関数の記述に関するルールについては、名前と値のペアの引数 LossFun を参照してください。
linearloss = @(C,S,W,Cost)sum(-W.*sum(S.*C,2))/sum(W);
線形損失関数を使用して、学習標本およびテスト標本の分類損失を推定します。
ceTrain = loss(CMdl,X(:,trainIdx),Ystats(trainIdx),'LossFun',linearloss,... 'ObservationsIn','columns')
ceTrain = -7.8330
ceTest = loss(CMdl,X(:,testIdx),Ystats(testIdx),'LossFun',linearloss,... 'ObservationsIn','columns')
ceTest = -7.7383
ロジスティック回帰学習器を使用する線形分類モデルに適した LASSO ペナルティの強度を決定するため、テスト標本の分類誤差率を比較します。
NLP のデータ セットを読み込みます。カスタムな分類損失の指定で説明されているようにデータを前処理します。
load nlpdata Ystats = Y == 'stats'; X = X'; rng(10); % For reproducibility Partition = cvpartition(Ystats,'Holdout',0.30); testIdx = test(Partition); XTest = X(:,testIdx); YTest = Ystats(testIdx);
~ の範囲で対数間隔で配置された 11 個の正則化強度を作成します。
Lambda = logspace(-6,-0.5,11);
各正則化強度を使用するバイナリ線形分類モデルに学習をさせます。SpaRSA を使用して目的関数を最適化します。目的関数の勾配の許容誤差を 1e-8 に下げます。
CVMdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'CVPartition',Partition,'Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8)
CVMdl =
ClassificationPartitionedLinear
CrossValidatedModel: 'Linear'
ResponseName: 'Y'
NumObservations: 31572
KFold: 1
Partition: [1×1 cvpartition]
ClassNames: [0 1]
ScoreTransform: 'none'
Properties, Methods
学習済みの線形分類モデルを抽出します。
Mdl = CVMdl.Trained{1}Mdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'logit'
Beta: [34023×11 double]
Bias: [-12.1061 -12.1061 -12.1061 -12.1061 -12.1061 -6.2137 -5.0657 -4.2469 -3.4386 -3.2542 -2.9792]
Lambda: [1.0000e-06 3.5481e-06 1.2589e-05 4.4668e-05 1.5849e-04 5.6234e-04 0.0020 0.0071 0.0251 0.0891 0.3162]
Learner: 'logistic'
Properties, Methods
Mdl は ClassificationLinear モデル オブジェクトです。Lambda は正則化強度のシーケンスなので、Mdl はそれぞれが Lambda の各正則化強度に対応する 11 個のモデルであると考えることができます。
テスト標本の分類誤差を推定します。
ce = loss(Mdl,X(:,testIdx),Ystats(testIdx),'ObservationsIn','columns');
11 個の正則化強度があるので、ce は 1 行 11 列の分類誤差率のベクトルです。
Lambda の値が大きくなると、予測子変数がスパースになります。これは分類器の品質として優れています。データ セット全体を使用し、モデルの交差検証を行ったときと同じオプションを指定して、各正則化強度について線形分類モデルに学習をさせます。モデルごとに非ゼロの係数を特定します。
Mdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'Learner','logistic','Solver','sparsa','Regularization','lasso',... 'Lambda',Lambda,'GradientTolerance',1e-8); numNZCoeff = sum(Mdl.Beta~=0);
同じ図に、各正則化強度についてのテスト標本の誤差率と非ゼロ係数の頻度をプロットします。すべての変数を対数スケールでプロットします。
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(ce),... log10(Lambda),log10(numNZCoeff + 1)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} classification error') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') title('Test-Sample Statistics') hold off
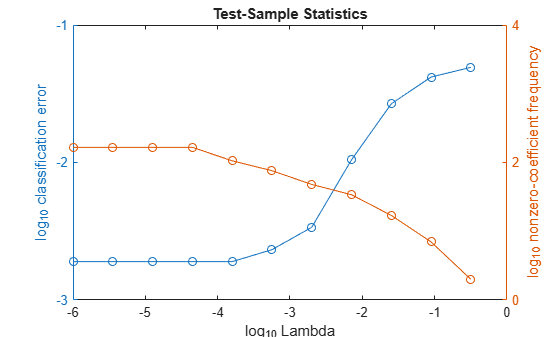
予測子変数のスパース性と分類誤差の低さのバランスがとれている正則化強度のインデックスを選択します。この場合、 ~ の値で十分なはずです。
idxFinal = 7;
選択した正則化強度のモデルを Mdl から選択します。
MdlFinal = selectModels(Mdl,idxFinal);
MdlFinal は、1 つの正則化強度が含まれている ClassificationLinear モデルです。新しい観測値のラベルを推定するには、MdlFinal と新しいデータを predict に渡します。
詳細
"分類損失" 関数は分類モデルの予測誤差を評価します。複数のモデルで同じタイプの損失を比較した場合、損失が低い方が予測モデルとして優れていることになります。
以下のシナリオを考えます。
L は加重平均分類損失です。
n は標本サイズです。
yj は観測されたクラス ラベルです。陰性クラスを示す -1 または陽性クラスを示す 1 (あるいは、
ClassNamesプロパティの最初のクラスを示す -1 または 2 番目のクラスを示す 1) を使用して符号化されます。f(Xj) は予測子データ X の観測値 (行) j に対する陽性クラスの分類スコアです。
mj = yjf(Xj) は、yj に対応するクラスに観測値 j を分類する分類スコアです。正の値の mj は正しい分類を示しており、平均損失に対する寄与は大きくありません。負の値の mj は正しくない分類を示しており、平均損失に大きく寄与します。
観測値 j の重みは wj です。観測値の重みは、その合計が
Priorプロパティに格納された対応するクラスの事前確率になるように正規化されます。そのため、次のようになります。
この状況では、名前と値の引数 LossFun を使用して指定できる、サポートされる損失関数は次の表のようになります。
| 損失関数 | LossFun の値 | 式 |
|---|---|---|
| 二項分布からの逸脱度 | "binodeviance" | |
| 観測誤分類コスト | "classifcost" | ここで、 はスコアが最大のクラスに対応するクラス ラベル、 は真のクラスが yj である場合に観測値をクラス に分類するユーザー指定のコストです。 |
| 10 進数の誤分類率 | "classiferror" | ここで、I{·} はインジケーター関数です。 |
| クロスエントロピー損失 | "crossentropy" |
加重クロスエントロピー損失は次となります。 ここで重み は、合計が 1 ではなく n になるように正規化されます。 |
| 指数損失 | "exponential" | |
| ヒンジ損失 | "hinge" | |
| ロジスティック損失 | "logit" | |
| 最小予測誤分類コスト | "mincost" |
重み付きの最小予測分類コストは、次の手順を観測値 j = 1、...、n について使用することにより計算されます。
最小予測誤分類コスト損失の加重平均は次となります。 |
| 二次損失 | "quadratic" |
既定のコスト行列 (正しい分類の場合の要素値は 0、誤った分類の場合の要素値は 1) を使用する場合、"classifcost"、"classiferror"、および "mincost" の損失の値は同じです。既定以外のコスト行列をもつモデルでは、ほとんどの場合は "classifcost" の損失と "mincost" の損失が等価になります。これらの損失が異なる値になる可能性があるのは、最大の事後確率をもつクラスへの予測と最小の予測コストをもつクラスへの予測が異なる場合です。"mincost" は分類スコアが事後確率の場合にしか適さないことに注意してください。
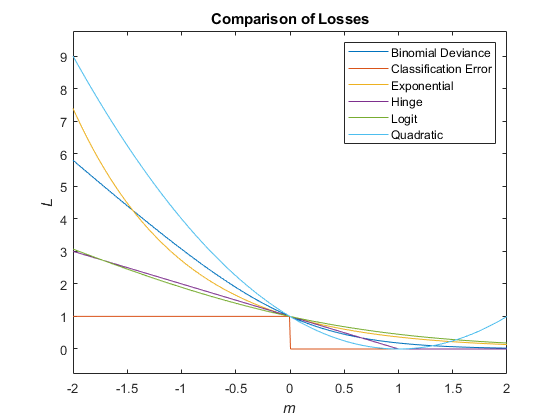
次の図では、1 つの観測値のスコア m に対する損失関数 ("classifcost"、"crossentropy"、および "mincost" を除く) を比較しています。いくつかの関数は、点 (0,1) を通過するように正規化されています。
アルゴリズム
既定の設定では、観測値の重みはクラスの事前確率です。Weights を使用して重みを指定した場合、合計がそれぞれのクラスの事前確率になるように正規化されます。重み付き分類損失の推定には、再正規化された値が使用されます。