loss
k 最近傍分類器の損失
説明
L = loss(mdl,Tbl,ResponseVarName)Tbl.ResponseVarName に含まれている場合に mdl が Tbl 内のデータをどの程度適切に分類するかを表すスカラーを返します。mdl を学習させるために使用した応答変数が Tbl に含まれている場合、ResponseVarName を指定する必要はありません。
関数 loss は、損失を計算するときに、mdl の Prior プロパティに格納されている、学習に使用されたクラス確率に対して、Tbl.ResponseVarName のクラス確率を正規化します。
分類損失 (L) の意味は損失関数と重み付けの方式によって異なりますが、一般に優れた分類器の方が分類損失の値が小さくなります。詳細は、分類損失を参照してください。
L = loss(___,Name,Value)
メモ
X または Tbl の予測子データに欠損値があり、LossFun が "classifcost"、"classiferror"、または "mincost" に設定されていない場合、関数 loss で NaN が返されることがあります。詳細については、欠損値がある予測子データに対して loss で NaN が返されることがあるを参照してください。
例
入力引数
名前と値の引数
アルゴリズム
"分類損失" 関数は分類モデルの予測誤差を評価します。複数のモデルで同じタイプの損失を比較した場合、損失が低い方が予測モデルとして優れていることになります。
以下のシナリオを考えます。
L は加重平均分類損失です。
n は標本サイズです。
バイナリ分類は以下です。
yj は観測されたクラス ラベルです。陰性クラスを示す -1 または陽性クラスを示す 1 (あるいは、
ClassNamesプロパティの最初のクラスを示す -1 または 2 番目のクラスを示す 1) を使用して符号化されます。f(Xj) は予測子データ X の観測値 (行) j に対する陽性クラスの分類スコアです。
mj = yjf(Xj) は、yj に対応するクラスに観測値 j を分類する分類スコアです。正の値の mj は正しい分類を示しており、平均損失に対する寄与は大きくありません。負の値の mj は正しくない分類を示しており、平均損失に大きく寄与します。
マルチクラス分類 (つまり、K ≥ 3) をサポートするアルゴリズムの場合、次のようになります。
yj* は、K - 1 個の 0 と、観測された真のクラス yj に対応する位置の 1 から構成されるベクトルです。たとえば、2 番目の観測値の真のクラスが 3 番目のクラスであり K = 4 の場合、y2* = [
0 0 1 0]′ になります。クラスの順序は入力モデルのClassNamesプロパティ内の順序に対応します。f(Xj) は予測子データ X の観測値 j に対するクラス スコアのベクトルで、長さは K です。スコアの順序は入力モデルの
ClassNamesプロパティ内のクラスの順序に対応します。mj = yj*′f(Xj).したがって mj は、観測された真のクラスについてモデルが予測するスカラー分類スコアです。
観測値 j の重みは wj です。観測値の重みは、その合計が
Priorプロパティに格納された対応するクラスの事前確率になるように正規化されます。そのため、次のようになります。
この状況では、名前と値の引数 LossFun を使用して指定できる、サポートされる損失関数は次の表のようになります。
| 損失関数 | LossFun の値 | 式 |
|---|---|---|
| 二項分布からの逸脱度 | "binodeviance" | |
| 観測誤分類コスト | "classifcost" | ここで、 はスコアが最大のクラスに対応するクラス ラベル、 は真のクラスが yj である場合に観測値をクラス に分類するユーザー指定のコストです。 |
| 10 進数の誤分類率 | "classiferror" | ここで、I{·} はインジケーター関数です。 |
| クロスエントロピー損失 | "crossentropy" |
加重クロスエントロピー損失は次となります。 ここで重み は、合計が 1 ではなく n になるように正規化されます。 |
| 指数損失 | "exponential" | |
| ヒンジ損失 | "hinge" | |
| ロジスティック損失 | "logit" | |
| 最小予測誤分類コスト | "mincost" |
重み付きの最小予測分類コストは、次の手順を観測値 j = 1、...、n について使用することにより計算されます。
最小予測誤分類コスト損失の加重平均は次となります。 |
| 二次損失 | "quadratic" |
既定のコスト行列 (正しい分類の場合の要素値は 0、誤った分類の場合の要素値は 1) を使用する場合、"classifcost"、"classiferror"、および "mincost" の損失の値は同じです。既定以外のコスト行列をもつモデルでは、ほとんどの場合は "classifcost" の損失と "mincost" の損失が等価になります。これらの損失が異なる値になる可能性があるのは、最大の事後確率をもつクラスへの予測と最小の予測コストをもつクラスへの予測が異なる場合です。"mincost" は分類スコアが事後確率の場合にしか適さないことに注意してください。
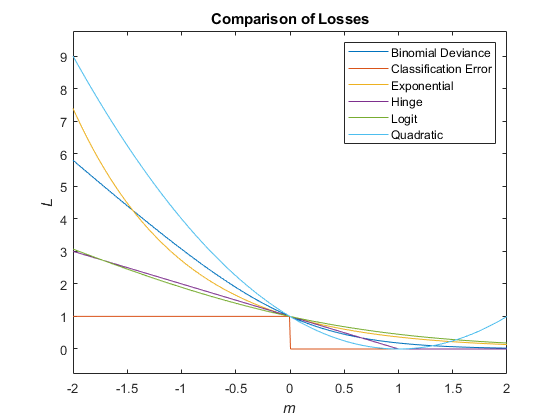
次の図では、1 つの観測値のスコア m に対する損失関数 ("classifcost"、"crossentropy"、および "mincost" を除く) を比較しています。いくつかの関数は、点 (0,1) を通過するように正規化されています。