auc
説明
例
入力引数
出力引数
アルゴリズム
ROC 曲線の場合、auc は trapz 関数を使用した台形積分によって曲線の下の領域を計算します。適合率-再現率曲線の場合、auc は trapz 関数を使用して曲線の下の領域を計算した後、曲線の一番左の点と点 (0,0) で形成される矩形の領域 (存在する場合) を加えます。以下に例を示します。
load ionosphere rng default % For reproducibility of the partition c = cvpartition(Y,Holdout=0.25); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set XTrain = X(trainingIndices,:); YTrain = Y(trainingIndices); XTest = X(testIndices,:); YTest = Y(testIndices); Mdl = fitcsvm(XTrain,YTrain); rocObj = rocmetrics(Mdl,XTest,YTest,AdditionalMetrics="ppv"); r = plot(rocObj,XAxisMetric="tpr",... YAxisMetric="ppv",ClassNames="b"); % Plots the normal PR curve. legend(Location="southeast")
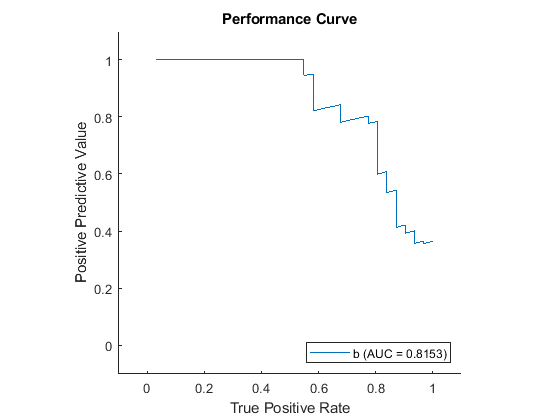
曲線の一番左の点と真陽性率のゼロの点の間に隙間があります。この隙間を埋める矩形をプロットします。これは、返される AUC に auc が加える補正を表します。
hold on rectangle(Position=[0 0 r.XData(2) r.YData(2)],FaceColor=r.Color) hold off
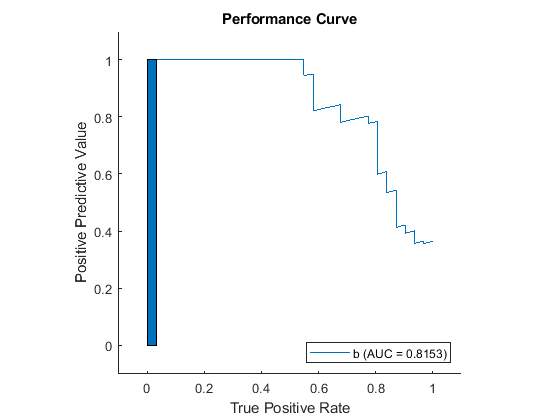
厳密には、この矩形は適合率-再現率曲線の一部ではありません。ただし、auc では、(定義域が異なる場合がある) モデル間の比較を簡単にするため、曲線の下の領域をそのままゼロまで延長したものとして扱います。
信頼区間を指定して rocmetrics オブジェクトが作成されている場合 (説明についてはリファレンス ページを参照)、返される AUC の lower 引数と upper 引数の信頼区間の計算には、元の rocmetrics オブジェクトに対して実行されたものと同じ手法が使用されます。これは、ブートストラッピングまたは交差検証のいずれかです。
バージョン履歴
R2024b で導入
参考
rocmetrics | average | plot