predict
分類木モデルを使用したラベルの予測
構文
説明
例
学習から除外されたデータ セットの数行について予測を確認します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheririsデータを学習セット (50%) と検証セット (50%) に分割します。
n = size(meas,1);
rng(1) % For reproducibility
idxTrn = false(n,1);
idxTrn(randsample(n,round(0.5*n))) = true;
idxVal = idxTrn == false; 学習セットを使用して分類木を成長させます。
Mdl = fitctree(meas(idxTrn,:),species(idxTrn));
検証データのラベルを予測し、予測されたラベルをいくつか表示します。誤分類した観測値の数をカウントします。
label = predict(Mdl,meas(idxVal,:)); label(randsample(numel(label),5))
ans = 5×1 cell
{'setosa' }
{'setosa' }
{'setosa' }
{'virginica' }
{'versicolor'}
numMisclass = sum(~strcmp(label,species(idxVal)))
numMisclass = 3
3 つの標本外観測値が誤分類されています。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheririsデータを学習セット (50%) と検証セット (50%) に分割します。
n = size(meas,1);
rng(1) % For reproducibility
idxTrn = false(n,1);
idxTrn(randsample(n,round(0.5*n))) = true;
idxVal = idxTrn == false;学習セットを使用して分類木を成長させ、表示します。
Mdl = fitctree(meas(idxTrn,:),species(idxTrn)); view(Mdl,"Mode","graph")
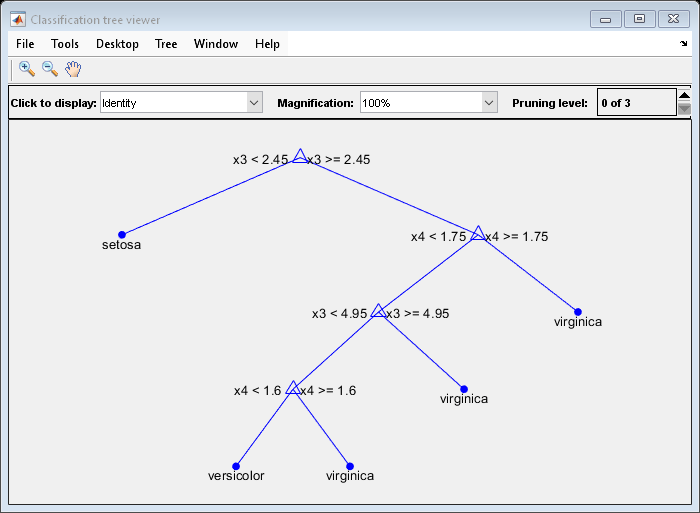
生成された木には 4 つのレベルがあります。
レベル 1 および 3 まで枝刈りした部分木を使用して、テスト セットの事後確率を推定します。事後確率をいくつか表示します。
[~,Posterior] = predict(Mdl,meas(idxVal,:), ...
Subtrees=[1 3]);
Mdl.ClassNamesans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
Posterior(randsample(size(Posterior,1),5),:,:)
ans =
ans(:,:,1) =
1.0000 0 0
1.0000 0 0
1.0000 0 0
0 0 1.0000
0 0.8571 0.1429
ans(:,:,2) =
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
Posterior の要素はクラスの事後確率です。
各行は検証セットの観測値に対応します。
各列は
Mdl.ClassNamesに含まれているクラスに対応します。各ページは部分木に対応します。
レベル 1 まで枝刈りした部分木は、レベル 3 (つまり、ルート ノード) まで枝刈りした部分木より予測が確実です。
入力引数
出力引数
詳細
アルゴリズム
predict は、葉ノードまたは欠損値に達するまで、tree の枝に沿って予測を生成します。predict が、葉ノードに達したら、そのノードの分類が返されます。
predict が予測子の欠損値をもつノードに達した場合の振る舞いは、fitctree で tree を作成したときの名前と値の引数 Surrogate の設定により異なります。
Surrogate="off"(既定値) —predictは、そのノードに達する学習標本の最大数をもつラベルを返します。Surrogate="on"—predictは、そのノードで最適な代理分岐を使用します。正の"関連性予測尺度"を含むすべての代理分岐変数がない場合、predictは、そのノードに達する学習標本の最大数をもつラベルを返します。この定義については、関連性予測尺度を参照してください。
代替機能
Simulink ブロック
Simulink® に分類木モデルの予測を統合するには、Statistics and Machine Learning Toolbox™ ライブラリにある ClassificationTree Predict ブロックを使用するか、MATLAB® Function ブロックを関数 predict と共に使用します。例については、ClassificationTree Predict ブロックの使用によるクラス ラベルの予測とMATLAB Function ブロックの使用によるクラス ラベルの予測を参照してください。
使用するアプローチを判断する際は、以下を考慮してください。
Statistics and Machine Learning Toolbox ライブラリ ブロックを使用する場合、固定小数点ツール (Fixed-Point Designer)を使用して浮動小数点モデルを固定小数点に変換できます。
MATLAB Function ブロックを関数
predictと共に使用する場合は、可変サイズの配列に対するサポートを有効にしなければなりません。MATLAB Function ブロックを使用する場合、予測の前処理や後処理のために、同じ MATLAB Function ブロック内で MATLAB 関数を使用することができます。
拡張機能
バージョン履歴
R2011a で導入
参考
fitctree | compact | prune | loss | edge | margin | CompactClassificationTree | ClassificationTree