resubPredict
再代入による分類木の観測値の分類
構文
説明
例
分類木では誤分類されるフィッシャーのアヤメのデータの総数を求めます。
load fisheriris tree = fitctree(meas,species); Ypredict = resubPredict(tree); % The predictions Ysame = strcmp(Ypredict,species); % True when == sum(~Ysame) % How many are different?
ans = 3
フィッシャーのアヤメのデータ セットを読み込みます。データを学習セット (50%) に分割します。
load fisheririsすべての花弁の測定値を使用して分類木を成長させます。
Mdl = fitctree(meas(:,3:4),species); n = size(meas,1); % Sample size K = numel(Mdl.ClassNames); % Number of classes
分類木を表示します。
view(Mdl,'Mode','graph');

この分類木には 4 つの枝刈りレベルがあります。レベル 0 は、(表示のように) 枝刈りされていない完全な木です。レベル 4 はルート ノードのみ (分割なし) です。
レベル 1 および 3 まで枝刈りした部分木を使用して、各クラスの事後確率を推定します。
[~,Posterior] = resubPredict(Mdl,'Subtrees',[1 3]);Posterior は、事後確率が格納されている n x K x 2 の配列です。Posterior の各行は観測値に、各列は Mdl.ClassNames の順序でクラスに、各ページは枝刈りレベルに対応します。
各部分木を使用して、アヤメ 125 のクラス事後確率を表示します。
Posterior(125,:,:)
ans =
ans(:,:,1) =
0 0.0217 0.9783
ans(:,:,2) =
0 0.5000 0.5000
決定株 (Posterior の 2 ページ) では、アヤメ 125 が versicolor と virginica のどちらであるかを正しく予測することが困難です。
予測子 X を X < 0.15 または X > 0.95 の場合は true に分類し、それ以外の場合は false に分類します。
0 と 1 の間で一様分布する 100 個の乱数を生成し、ツリー モデルを使用してそれらを分類します。
rng("default") % For reproducibility X = rand(100,1); Y = (abs(X - 0.55) > 0.4); tree = fitctree(X,Y); view(tree,"Mode","graph")

ツリーを枝刈りします。
tree1 = prune(tree,"Level",1); view(tree1,"Mode","graph")
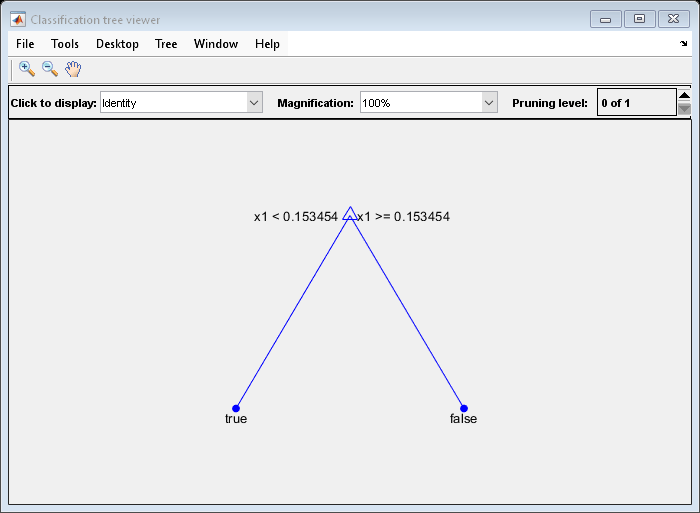
枝刈りされたツリーは、0.15 未満の観測値を正しく true に分類しています。また、0.15 から 0.95 までの観測値についても、正しく false に分類しています。しかし、0.95 より大きい観測値は false に誤って分類されます。そのため、0.15 より大きい観測値のスコアは、true では 0.05/0.85=0.06、false では 0.8/0.85=0.94 になります。
X の先頭から 10 行までの予測スコア (事後確率) を計算します。
[~,score] = resubPredict(tree1); [score(1:10,:) X(1:10)]
ans = 10×3
0.9059 0.0941 0.8147
0.9059 0.0941 0.9058
0 1.0000 0.1270
0.9059 0.0941 0.9134
0.9059 0.0941 0.6324
0 1.0000 0.0975
0.9059 0.0941 0.2785
0.9059 0.0941 0.5469
0.9059 0.0941 0.9575
0.9059 0.0941 0.9649
実際に、X で 0.15 より小さいすべての値 (右端の列) には、0 と 1 のスコアが関連付けられ (左の列と中央の列)、X のその他の値には、約 0.91 と 0.09 のスコアが関連付けられています。スコアの違い (想定した 0.06 ではなく、0.09) は、統計変動によるものです。範囲 (0.95,1) の X には、想定した 5 個ではなく 8 個の観測値があります。
sum(X > 0.95)
ans = 8
入力引数
出力引数
詳細
拡張機能
バージョン履歴
R2011a で導入
参考
resubEdge | resubMargin | resubLoss | predict | fitctree | ClassificationTree