MultinomialRegression
説明
MultinomialRegression は、当てはめ済みの多項回帰モデル オブジェクトです。多項回帰モデルは、予測子と値の有限の集合をもつ応答との間の関係を記述します。
当てはめた多項回帰モデルを調べるには、MultinomialRegression オブジェクトのプロパティを使用します。オブジェクト プロパティには、係数推定値、要約統計量、およびモデルの当てはめに使用されるデータに関する情報が含まれています。オブジェクト関数を使用して、応答の予測や多項回帰モデルの評価と可視化を行います。
作成
MultinomialRegression モデル オブジェクトは、fitmnr を使用してパラメーターの値を指定して作成します。
プロパティ
オブジェクト関数
coefCI | 多項回帰モデルの係数推定の信頼区間 |
coefTest | 多項回帰モデルの係数に対する線形仮説検定 |
feval | 各予測子について 1 つずつ入力を使用して多項回帰モデルの応答を予測 |
partialDependence | 部分依存の計算 |
plotPartialDependence | 部分依存プロット (PDP) および個別条件付き期待値 (ICE) プロットの作成 |
plotResiduals | 多項回帰モデルの残差プロット |
plotSlice | 当てはめられた多項回帰面を通るスライスのプロット |
predict | 多項回帰モデルの応答を予測 |
random | 当てはめられた多項回帰モデルからランダム応答を生成 |
testDeviance | 多項回帰モデルの逸脱度検定 |
例
標本データ セット fisheriris を読み込みます。
load fisheriris列ベクトル species には、3 種類のアヤメ (setosa、versicolor、virginica) が格納されています。行列 meas には、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) が格納されています。
多項回帰モデルを当てはめ、測定値を使用してアヤメの種類を予測します。当てはめたモデルの Coefficients プロパティを使用して当てはめの結果を表示します。
MnrModel = fitmnr(meas,species); MnrModel.Coefficients
ans=10×4 table
Value SE tStat pValue
_______ ______ _______ __________
(Intercept_setosa) 2018.4 12.404 162.72 0
x1_setosa 673.85 3.5783 188.32 0
x2_setosa -568.2 3.176 -178.9 0
x3_setosa -516.44 3.5403 -145.87 0
x4_setosa -2760.9 7.1203 -387.75 0
(Intercept_versicolor) 42.638 5.2719 8.0878 6.0776e-16
x1_versicolor 2.4652 1.1228 2.1956 0.028124
x2_versicolor 6.6809 1.4789 4.5176 6.2559e-06
x3_versicolor -9.4294 1.2934 -7.2906 3.086e-13
x4_versicolor -18.286 2.0967 -8.7214 2.7476e-18
MnrModel は、ノミナル多項回帰モデルをデータに当てはめた結果を含む多項回帰モデル オブジェクトです。Coefficients プロパティに meas の各予測子の係数統計量が格納されています。列 pValue の "p" 値が小さく、すべての係数が 95% の信頼水準で統計的に有意であることを示しています。fitmnr では、species のカテゴリをそれらが最初に現れる順序で並べ替えます。既定では、その最後のカテゴリが基準カテゴリとなります。
並べ替え後の応答変数カテゴリの名前を表示するには、MnrModel の ClassNames プロパティを使用します。
MnrModel.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
出力から最後のカテゴリは 'virginica' であり、既定ではそれが基準カテゴリになります。
当てはめられた係数推定値の 95% 信頼区間を取得するには、オブジェクト関数 coefCI を呼び出します。
coefCI(MnrModel)
ans = 10×2
103 ×
1.9940 2.0428
0.6668 0.6809
-0.5745 -0.5620
-0.5234 -0.5095
-2.7749 -2.7469
0.0323 0.0530
0.0003 0.0047
0.0038 0.0096
-0.0120 -0.0069
-0.0224 -0.0142
table Coefficients の Value 列の 10 個の係数について、それらの 95% 信頼区間が出力に表示されます。いずれの信頼区間もゼロと交差しておらず、すべての係数が 95% の信頼水準で対数オッズに影響することがわかります。
標本データ セット fisheriris を読み込みます。
load fisheriris列ベクトル species には、3 種類のアヤメの種 (setosa、versicolor、virginica) が格納されています。行列 meas には、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) が格納されています。
関数cvpartitionを使用して、種類と測定値のデータを学習データとテスト データに分割します。関数trainingを使用して、学習データの行のインデックスを取得します。
n = length(species);
partition = cvpartition(n,'Holdout',0.05);
idx_train = training(partition);学習データの行のインデックスを使用して学習データを作成し、測定値の行列と種類のラベルのベクトルを作成します。
meastrain = meas(idx_train,:); speciestrain = species(idx_train,:);
学習データを使用して多項回帰モデルを当てはめます。
mdl = fitmnr(meastrain,speciestrain)
mdl =
Multinomial regression with nominal responses
Value SE tStat pValue
_______ ______ ________ __________
(Intercept_setosa) 86.297 12.541 6.881 5.9436e-12
x1_setosa -1.0653 3.5795 -0.29761 0.766
x2_setosa 23.849 3.1238 7.6347 2.2637e-14
x3_setosa -27.273 3.5009 -7.7903 6.6846e-15
x4_setosa -59.644 7.0214 -8.4947 1.9852e-17
(Intercept_versicolor) 42.637 5.2214 8.1659 3.1906e-16
x1_versicolor 2.4652 1.1263 2.1887 0.028619
x2_versicolor 6.6808 1.474 4.5325 5.829e-06
x3_versicolor -9.4292 1.2946 -7.2837 3.248e-13
x4_versicolor -18.286 2.0833 -8.7775 1.671e-18
143 observations, 276 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 302.0378, p-value = 1.5168e-60
mdl は、ノミナル多項回帰モデルをデータに当てはめた結果を含む多項回帰モデル オブジェクトです。meas の各予測子の係数統計量が table 出力に表示されます。既定では、virginica が fitmnr で基準カテゴリとして使用されます。
関数testを使用して、テスト データの行のインデックスを取得します。テスト データの行のインデックスを使用してテスト データを作成し、測定値の行列と種類のラベルのベクトルを作成します。
idx_test = test(partition); meastest = meas(idx_test,:); speciestest = species(idx_test,:);
meastest の測定値について、アヤメの種類を予測します。
speciespredict = predict(mdl,meastest)
speciespredict = 7×1 cell
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'versicolor'}
{'versicolor'}
speciespredict の予測を speciestest のカテゴリ名と比較します。
speciestest
speciestest = 7×1 cell
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'versicolor'}
{'versicolor'}
出力から、meastest の測定値について、アヤメの種類がモデルで正確に予測されていることがわかります。
標本データ セット carbig を読み込みます。
load carbig;ベクトル Acceleration および Displacement には、自動車の加速度と排気量のデータがそれぞれ格納されています。ベクトル Cylinders には、それぞれの自動車のエンジンに搭載された気筒の数のデータが格納されています。
Acceleration と Displacement を予測子変数、Cylinders を応答変数として使用して、順序多項回帰モデルを当てはめます。
MnrModel = fitmnr([Acceleration,Displacement],Cylinders,Model="ordinal",... PredictorNames=["Acceleration" "Displacement"])
MnrModel =
Multinomial regression with ordinal responses
Value SE tStat pValue
_________ ________ _______ __________
(Intercept_3) 11.949 3.1817 3.7555 0.00017299
(Intercept_4) 27.08 4.9481 5.4727 4.4321e-08
(Intercept_5) 27.528 4.9738 5.5346 3.1195e-08
(Intercept_6) 45.346 7.8292 5.7919 6.9593e-09
Acceleration -0.063533 0.1041 -0.6103 0.54167
Displacement -0.16731 0.027885 -6 1.9726e-09
406 observations, 1618 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 786.5846, p-value = 1.5679e-171
MnrModel は、順序多項回帰モデルをデータに当てはめた結果を含む多項回帰モデル オブジェクトです。各予測子変数の係数統計量が table 出力に表示されます。列 pValue の "p" 値が小さく、Acceleration 項の係数が統計的に有意であると結論付けるだけの十分な証拠はないことを示しています。一方、Displacement については、99% の信頼水準で統計的に有意な影響を与えると結論付けるだけの十分な証拠があります。
ClassNames プロパティを使用して、自動車のエンジン気筒数の取り得る数を表示します。
MnrModel.ClassNames
ans = 5×1
3
4
5
6
8
既定では、出力の最後のカテゴリが基準カテゴリとなります。出力から、基準カテゴリは 8 気筒エンジンを搭載した自動車に対応することがわかります。
plotSlice を使用して、予測子変数 Displacement の値を変化させて、それぞれの気筒数の自動車である確率の積み上げヒストグラムをプロットします。既定では、Acceleration の値については、その学習データの平均に plotSlice で固定されます。
plotSlice(MnrModel,"stackedhist",PredictorToVary="Displacement") hold on lgd = legend; title(lgd, "Number of cylinders");
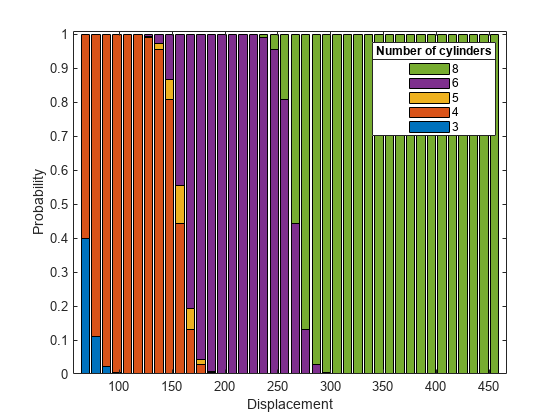
プロットから、自動車の排気量が増えるほど、より多くの気筒を搭載した自動車である確率が高くなることがわかります。これは、モデルの Displacement 項の "p" 値が小さいことと整合します。
標本データ セット carbig を読み込みます。
load carbig;ベクトル Acceleration および Displacement には、自動車の加速度と排気量のデータがそれぞれ格納されています。ベクトル Cylinders には、それぞれの自動車のエンジンに搭載された気筒の数のデータが格納されています。
Acceleration と Displacement を予測子変数、Cylinders を応答変数として使用して、順序多項回帰モデルを当てはめます。
MnrModel = fitmnr([Acceleration,Displacement],Cylinders,Model="ordinal",... PredictorNames=["Acceleration" "Displacement"])
MnrModel =
Multinomial regression with ordinal responses
Value SE tStat pValue
_________ ________ _______ __________
(Intercept_3) 11.949 3.1817 3.7555 0.00017299
(Intercept_4) 27.08 4.9481 5.4727 4.4321e-08
(Intercept_5) 27.528 4.9738 5.5346 3.1195e-08
(Intercept_6) 45.346 7.8292 5.7919 6.9593e-09
Acceleration -0.063533 0.1041 -0.6103 0.54167
Displacement -0.16731 0.027885 -6 1.9726e-09
406 observations, 1618 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 786.5846, p-value = 1.5679e-171
MnrModel は、順序多項回帰モデルをデータに当てはめた結果を含む多項回帰モデル オブジェクトです。それぞれの予測子変数の係数統計量が table 出力に表示されます。列 pValue の "p" 値が小さく、Acceleration 項の係数が統計的に有意であると結論付けるだけの十分な証拠はないことを示しています。一方、Displacement については、99% の信頼水準で統計的に有意な影響を与えると結論付けるだけの十分な証拠があります。
ClassNames プロパティを使用して、自動車のエンジン気筒数の取り得る数を表示します。
MnrModel.ClassNames
ans = 5×1
3
4
5
6
8
基準カテゴリは 8 気筒エンジンを搭載した自動車に対応します。
オブジェクト関数plotPartialDependenceを使用して、基準カテゴリの確率の Displacement 予測子に対する部分依存をプロットします。
plotPartialDependence(MnrModel,2,8)
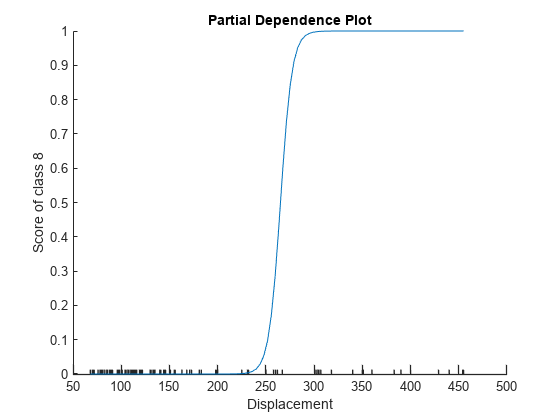
プロットから、Displacement の値が約 250 に達したところで、基準カテゴリの自動車である確率が急激に高くなることがわかります。
詳細
参照
[1] Allison, P. D. "Measures of Fit for Logistic Regression." Statistical Horizons LLC and the University of Pennsylvania, 2014.
[2] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.
[3] Long, J. S. Regression Models for Categorical and Limited Dependent Variables. Sage Publications, 1997.
[4] Dobson, A. J., and A. G. Barnett. An Introduction to Generalized Linear Models. Chapman and Hall/CRC. Taylor & Francis Group, 2008.
バージョン履歴
R2023a で導入