predict
非線形回帰モデルの応答予測
構文
説明
例
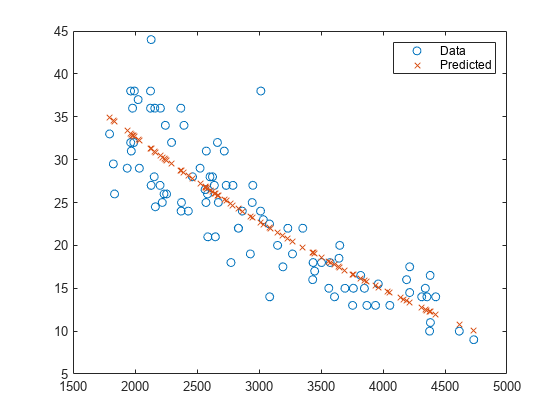
自動車の燃費の非線形モデルを重量の関数として作成し、応答を予測します。
carsmall データから、重量の関数として自動車の燃費の指数モデルを作成します。すべての変数がほぼ同じサイズになるように、1000 のファクタで重み付けをスケーリングします。
load carsmall X = Weight; y = MPG; modelfun = 'y ~ b1 + b2*exp(-b3*x/1000)'; beta0 = [1 1 1]; mdl = fitnlm(X,y,modelfun,beta0);
データに対する予測された応答を作成します。
Xnew = X; ypred = predict(mdl,Xnew);
元の応答と予測された応答をプロットして、相違点を確認します。
plot(X,y,'o',X,ypred,'x') legend('Data','Predicted')
自動車の燃費の非線形モデルを重量の関数として作成し、いくつかの応答の信頼区間を調べます。
carsmall データから、重量の関数として自動車の燃費の指数モデルを作成します。すべての変数がほぼ同じサイズになるように、1000 のファクタで重み付けをスケーリングします。
load carsmall X = Weight; y = MPG; modelfun = 'y ~ b1 + b2*exp(-b3*x/1000)'; beta0 = [1 1 1]; mdl = fitnlm(X,y,modelfun,beta0);
最小、平均および最大のデータ点の予測応答を作成します。
Xnew = [min(X);mean(X);max(X)]; [ypred,yci] = predict(mdl,Xnew)
ypred = 3×1
34.9469
22.6868
10.0617
yci = 3×2
32.5212 37.3726
21.4061 23.9674
7.0148 13.1086
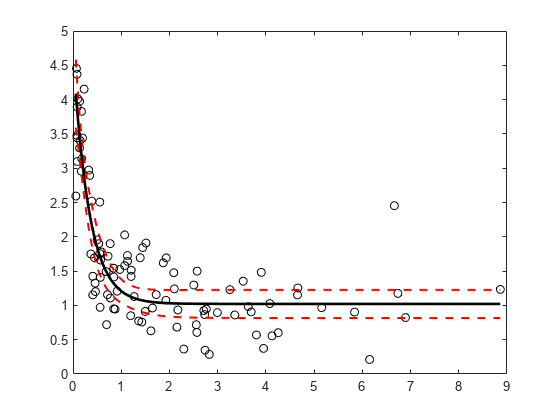
次の非線形回帰モデルから標本データを生成します。
ここで、、 および は係数です。誤差項 は平均 0 および標準偏差 0.5 の正規分布に従います。
modelfun = @(b,x)(b(1)+b(2)*exp(-b(3)*x)); rng('default') % For reproducibility b = [1;3;2]; x = exprnd(2,100,1); y = modelfun(b,x) + normrnd(0,0.5,100,1);
ロバスト近似オプションを使用して非線形モデルを当てはめます。
opts = statset('nlinfit'); opts.RobustWgtFun = 'bisquare'; b0 = [2;2;2]; mdl = fitnlm(x,y,modelfun,b0,'Options',opts);
近似した回帰モデルと 95% の同時信頼限界をプロットします。
xrange = [min(x):.01:max(x)]'; [ypred,yci] = predict(mdl,xrange,'Simultaneous',true); figure() plot(x,y,'ko') % observed data hold on plot(xrange,ypred,'k','LineWidth',2) plot(xrange,yci','r--','LineWidth',1.5)
標本データを読み込みます。
S = load('reaction');
X = S.reactants;
y = S.rate;
beta0 = S.beta;観測の重みの関数ハンドルを指定した後、指定した観測の重み関数を使用してレート データに Hougen-Watson モデルを当てはめます。
a = 1; b = 1;
weights = @(yhat) 1./((a + b*abs(yhat)).^2);
mdl = fitnlm(X,y,@hougen,beta0,'Weights',weights);観測値の重みの関数を使用して、反応物レベル [100,100,100] で新しい観測値について 95% の予測区間を計算します。
[ypred,yci] = predict(mdl,[100,100,100],'Prediction','observation', ... 'Weights',weights)
ypred = 1.8149
yci = 1×2
1.5264 2.1033
入力引数
名前と値の引数
出力引数
参照
[1] Lane, T. P. and W. H. DuMouchel. “Simultaneous Confidence Intervals in Multiple Regression.” The American Statistician. Vol. 48, No. 4, 1994, pp. 315–321. Available at https://doi.org/10.1080/00031305.1994.10476090
[2] Seber, G. A. F., and C. J. Wild. Nonlinear Regression. Hoboken, NJ: Wiley-Interscience, 2003.
バージョン履歴
R2012a で導入