RegressionGP
ガウス過程回帰モデル
説明
RegressionGP は、ガウス過程回帰 (GPR) モデルです。GPR モデルを学習させるには、fitrgp を使用します。学習済みのモデルを使用して次を行えます。
resubPredictを使用した学習データの応答の予測、またはpredictを使用した新しい予測子データの応答の予測。予測区間を計算することもできます。resubLossを使用した学習データの回帰損失の計算、またはlossを使用した新しいデータの回帰損失の計算。
作成
RegressionGP オブジェクトの作成には fitrgp を使用します。
プロパティ
オブジェクト関数
compact | 機械学習モデルのサイズの縮小 |
crossval | 機械学習モデルの交差検証 |
gather | GPU からの Statistics and Machine Learning Toolbox オブジェクトのプロパティの収集 |
lime | Local Interpretable Model-agnostic Explanations (LIME) |
loss | Regression error for Gaussian process regression model |
partialDependence | 部分依存の計算 |
plotPartialDependence | 部分依存プロット (PDP) および個別条件付き期待値 (ICE) プロットの作成 |
postFitStatistics | 厳密ガウス過程回帰モデルの当てはめ統計量の計算 |
predict | ガウス過程回帰モデルの予測応答 |
resubLoss | 再代入回帰損失 |
resubPredict | 学習済み回帰モデルを使用した学習データについての応答の予測 |
shapley | シャープレイ値 |
例
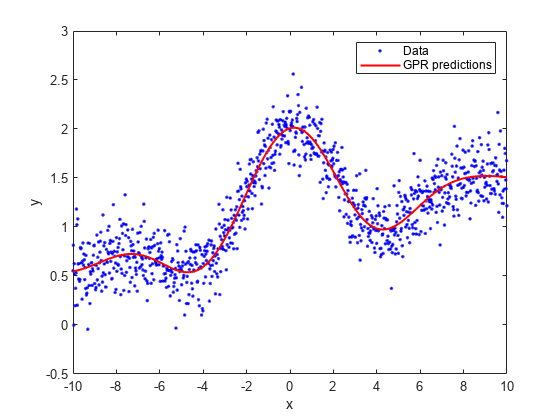
標本データを生成します。
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
パラメーターの推定に線形基底関数と厳密近似法を使用して、GPR モデルを当てはめます。厳密予測法も使用します。
gprMdl = fitrgp(x,y,'Basis','linear',... 'FitMethod','exact','PredictMethod','exact');
学習済みのモデルを使用して、x の行に対応する応答を予測します (再代入予測)。
ypred = resubPredict(gprMdl);
真の応答と予測値をプロットします。
plot(x,y,'b.'); hold on; plot(x,ypred,'r','LineWidth',1.5); xlabel('x'); ylabel('y'); legend('Data','GPR predictions'); hold off
詳細
ヒント
このクラスのプロパティには、ドット表記を使用してアクセスできます。たとえば、
KernelInformationはカーネル パラメーターとその名前が保持される構造体です。したがって、学習済みモデルgprMdlのカーネル関数のパラメーターにアクセスするには、gprMdl.KernelInformation.KernelParametersを使用します。