fitrgp
ガウス過程回帰 (GPR) モデルの当てはめ
構文
説明
Mdl = fitrgp(Tbl,ResponseVarName)Tbl 内の標本データを使用して学習させたガウス過程回帰 (GPR) モデルを返します。ResponseVarName は、Tbl 内の応答変数の名前です。
Mdl = fitrgp(___,Name=Value)
たとえば、近似法、予測法、共分散関数またはアクティブ セット選択法を指定できます。交差検証済みモデルを学習させることもできます。
Mdl は RegressionGP オブジェクトです。このオブジェクトのオブジェクト関数とプロパティについては、RegressionGP を参照してください。
交差検証済みモデルを学習させた場合、Mdl は RegressionPartitionedGP オブジェクトになります。交差検証したオブジェクトをさらに分析するには、RegressionPartitionedGP オブジェクトのオブジェクト関数を使用します。
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitrgp(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
この例では、UCI Machine Learning Repository [3]にあるアワビのデータ[1]、[2]を使用します。データをダウンロードして、abalone.data という名前で現在のフォルダに保存します。
データを table に格納します。最初の 7 行を表示します。
tbl = readtable('abalone.data','Filetype','text',... 'ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height',... 'WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20このデータセットには、4177 個の観測値が含まれています。目標は、8 つの物理的な測定値からアワビの年齢を予測することです。最後の変数は貝殻の輪の数で、アワビの年齢を示します。最初の予測子は、カテゴリカル変数です。table の最後の変数は、応答変数です。
パラメーター推定に回帰変数サブセット法を、予測に完全独立条件法を使用して、GPR モデルを当てはめます。予測子を標準化します。
gprMdl = fitrgp(tbl,'NoShellRings','KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1)
grMdl =
RegressionGP
PredictorNames: {1x8 cell}
ResponseName: 'Var9'
ResponseTransform: 'none'
NumObservations: 4177
KernelFunction: 'ARDSquaredExponential'
KernelInformation: [1x1 struct]
BasisFunction: 'Constant'
Beta: 10.9148
Sigma: 2.0243
PredictorLocation: [10x1 double]
PredictorScale: [10x1 double]
Alpha: [1000x1 double]
ActiveSetVectors: [1000x10 double]
PredictMethod: 'FIC'
ActiveSetSize: 1000
FitMethod: 'SR'
ActiveSetMethod: 'Random'
IsActiveSetVector: [4177x1 logical]
LogLikelihood: -9.0013e+03
ActiveSetHistory: [1x1 struct]
BCDInformation: []
学習済みのモデルを使用して、応答を予測します。
ypred = resubPredict(gprMdl);
真の応答と予測応答をプロットします。
figure(); plot(tbl.NoShellRings,'r.'); hold on plot(ypred,'b'); xlabel('x'); ylabel('y'); legend({'data','predictions'},'Location','Best'); axis([0 4300 0 30]); hold off;
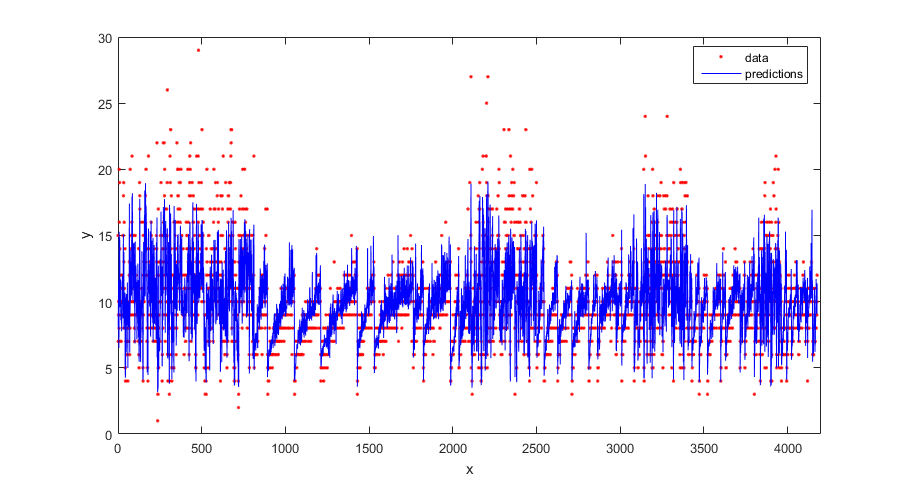
学習済みのモデルについて学習データの回帰損失 (再代入損失) を計算します。
L = resubLoss(gprMdl)
L =
4.0064標本データを生成します。
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
パラメーターの推定に線形基底関数と厳密近似法を使用して、GPR モデルを当てはめます。厳密予測法も使用します。
gprMdl = fitrgp(x,y,'Basis','linear',... 'FitMethod','exact','PredictMethod','exact');
学習済みのモデルを使用して、x の行に対応する応答を予測します (再代入予測)。
ypred = resubPredict(gprMdl);
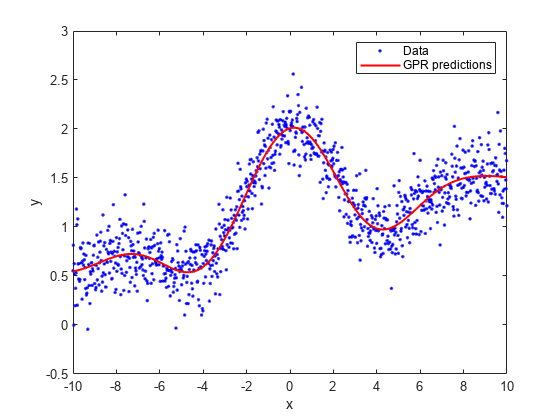
真の応答と予測値をプロットします。
plot(x,y,'b.'); hold on; plot(x,ypred,'r','LineWidth',1.5); xlabel('x'); ylabel('y'); legend('Data','GPR predictions'); hold off
標本データを読み込みます。
load('gprdata2.mat')このデータには、1 つの予測子変数と連続応答が含まれています。このデータは、シミュレーションされたものです。
既定のカーネル パラメーターで二乗指数カーネル関数を使用して、GPR モデルを当てはめます。
gprMdl1 = fitrgp(x,y,'KernelFunction','squaredexponential');
次に、2 番目のモデルを当てはめます。今回は、カーネル パラメーターの初期値を指定します。
sigma0 = 0.2; kparams0 = [3.5, 6.2]; gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential',... 'KernelParameters',kparams0,'Sigma',sigma0);
両方のモデルから再代入予測を計算します。
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2);
両方のモデルの応答予測と学習データの応答をプロットします。
figure(); plot(x,y,'r.'); hold on plot(x,ypred1,'b'); plot(x,ypred2,'g'); xlabel('x'); ylabel('y'); legend({'data','default kernel parameters',... 'kparams0 = [3.5,6.2], sigma0 = 0.2'},... 'Location','Best'); title('Impact of initial kernel parameter values'); hold off
![Figure contains an axes object. The axes object with title Impact of initial kernel parameter values, xlabel x, ylabel y contains 3 objects of type line. One or more of the lines displays its values using only markers These objects represent data, default kernel parameters, kparams0 = [3.5,6.2], sigma0 = 0.2.](../examples/stats/win64/ImpactofSpecifyingInitialKernelParameterValuesExample_01.png)
GPR パラメーターを推定するために fitrgp が最大化する周辺の対数尤度には、複数のローカルな解が存在します。どの解に収束するかは、初期点によって決まります。それぞれのローカルな解は、特定のデータ解釈に対応します。この例では、既定の初期カーネル パラメーターを使用した解は、ノイズが多い低周波信号に対応します。一方、カスタムな初期カーネル パラメーターを使用した 2 番目の解は、ノイズが少ない高周波信号に対応します。
標本データを読み込みます。
load('gprdata.mat')6 つの連続予測子変数があります。学習データ セットには 500 個の観測値が、テスト データ セットには 100 個の観測値があります。このデータは、シミュレーションされたものです。
各予測子について長さスケールが異なる二乗指数カーネル関数を使用して、GPR モデルを当てはめます。この共分散関数は、次のように定義されます。
ここで、 は予測子 ( = 1、2、...、) の長さスケールを表します。 と は信号標準偏差です。制約がないパラメーター化 は、次のようになります。
カーネル関数の長さスケールを 10 で、信号標準偏差とノイズ標準偏差を応答の標準偏差で初期化します。
sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(Xtrain,2); sigmaM0 = 10*ones(d,1);
カーネル パラメーターの初期値を使用して、GPR モデルを当てはめます。学習データの予測子を標準化します。厳密な近似法および予測法を使用します。
gprMdl = fitrgp(Xtrain,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
テスト データの回帰損失を計算します。
L = loss(gprMdl,Xtest,ytest)
L = 0.6919
カーネル情報にアクセスします。
gprMdl.KernelInformation
ans = struct with fields:
Name: 'ARDSquaredExponential'
KernelParameters: [7×1 double]
KernelParameterNames: {7×1 cell}
カーネル パラメーターの名前を表示します。ARD カーネルを使用する場合、長さスケール パラメーターは展開された予測子に対応します。長さスケール パラメーターの名前を展開された予測子の名前に置き換えます。
paramNames = gprMdl.KernelInformation.KernelParameterNames
paramNames = 7×1 cell
{'LengthScale1'}
{'LengthScale2'}
{'LengthScale3'}
{'LengthScale4'}
{'LengthScale5'}
{'LengthScale6'}
{'SigmaF' }
paramNames(1:end-1) = gprMdl.ExpandedPredictorNames
paramNames = 7×1 cell
{'x1' }
{'x2' }
{'x3' }
{'x4' }
{'x5' }
{'x6' }
{'SigmaF'}
カーネル パラメーターを表示します。
sigmaM = gprMdl.KernelInformation.KernelParameters(1:end-1,1)
sigmaM = 6×1
104 ×
0.0004
0.0007
0.0004
4.7605
0.1018
0.0056
sigmaF = gprMdl.KernelInformation.KernelParameters(end)
sigmaF = 28.1720
sigma = gprMdl.Sigma
sigma = 0.8162
学習した長さスケールの対数をプロットします。
figure() plot((1:d)',log(sigmaM),'ro-'); xlabel('Length scale number'); ylabel('Log of length scale');

4 番目と 5 番目の予測子変数における長さスケールの対数が、他と比較して大きくなっています。これらの予測子変数は、他の予測子変数ほどは応答に影響を与えないようです。
4 番目と 5 番目の変数を予測子変数として使用せずに GPR モデルを当てはめます。
X = [Xtrain(:,1:3) Xtrain(:,6)]; sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(X,2); sigmaM0 = 10*ones(d,1); gprMdl = fitrgp(X,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
テスト データの回帰誤差を計算します。
xtest = [Xtest(:,1:3) Xtest(:,6)]; L = loss(gprMdl,xtest,ytest)
L = 0.6928
損失は、すべての変数を予測子変数として使用した場合と同じような値になっています。
テスト データについて予測応答を計算します。
ypred = predict(gprMdl,xtest);
元の応答および当てはめた値をプロットします。
figure; plot(ytest,'r'); hold on; plot(ypred,'b'); legend('True response','GPR predicted values','Location','Best'); hold off

fitrgp を使用して、GPR モデルのハイパーパラメーターを自動的に最適化します。最適化されたハイパーパラメーター値を使用するモデルと既定のハイパーパラメーター値を使用するモデルで、モデルの当てはめを比較します。
gprdata2 データ セットを読み込みます。
load gprdata2シミュレーション データは、1 つの予測子変数と 1 つの連続応答で構成されています。
既定のカーネル パラメーターで二乗指数カーネル関数を使用して、GPR モデルを当てはめます。
gprMdl1 = fitrgp(x,y,KernelFunction="squaredexponential");自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。再現性を得るために、乱数シードを設定し、"expected-improvement-plus" の獲得関数を使用します。
rng(0,"twister") hpoOptions = hyperparameterOptimizationOptions(AcquisitionFunctionName="expected-improvement-plus"); gprMdl2 = fitrgp(x,y,KernelFunction="squaredexponential", ... OptimizeHyperparameters="auto",HyperparameterOptimizationOptions=hpoOptions);
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | Standardize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 1 | Best | 0.42258 | 1.5225 | 0.42258 | 0.42258 | 2.7255 | false |
| 2 | Accept | 1.5061 | 1.9339 | 0.42258 | 0.72573 | 0.0057724 | true |
| 3 | Accept | 1.6498 | 0.73634 | 0.42258 | 0.44024 | 25.905 | true |
| 4 | Best | 0.29824 | 2.1104 | 0.29824 | 0.34769 | 0.0098001 | false |
| 5 | Accept | 0.29873 | 2.32 | 0.29824 | 0.28958 | 0.00010004 | false |
| 6 | Accept | 0.29873 | 2.6094 | 0.29824 | 0.29843 | 0.00010043 | false |
| 7 | Accept | 1.5335 | 1.8128 | 0.29824 | 0.29874 | 0.0010605 | false |
| 8 | Accept | 1.4588 | 1.6501 | 0.29824 | 0.93331 | 0.015898 | false |
| 9 | Accept | 2.0988 | 0.86788 | 0.29824 | 1.0628 | 29.197 | false |
| 10 | Accept | 0.29873 | 2.0644 | 0.29824 | 0.29875 | 0.00010018 | false |
| 11 | Accept | 0.29839 | 2.0358 | 0.29824 | 0.92386 | 0.0081946 | false |
| 12 | Accept | 1.0384 | 1.5563 | 0.29824 | 0.9334 | 0.0029634 | false |
| 13 | Accept | 0.29873 | 2.0199 | 0.29824 | 0.29875 | 0.00010028 | false |
| 14 | Accept | 0.29873 | 2.0423 | 0.29824 | 0.2985 | 0.00013764 | false |
| 15 | Accept | 0.42286 | 0.87571 | 0.29824 | 0.29852 | 1.7961 | false |
| 16 | Accept | 1.0387 | 1.4747 | 0.29824 | 0.29753 | 0.00021994 | false |
| 17 | Accept | 0.29873 | 1.9232 | 0.29824 | 0.29877 | 0.0001181 | false |
| 18 | Accept | 0.42357 | 0.79 | 0.29824 | 0.29878 | 0.99648 | false |
| 19 | Accept | 0.42164 | 0.76652 | 0.29824 | 0.29879 | 0.56592 | false |
| 20 | Best | 0.037686 | 1.5945 | 0.037686 | 0.037782 | 0.30638 | false |
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | Standardize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 21 | Accept | 0.037728 | 1.1352 | 0.037686 | 0.037733 | 0.21519 | false |
| 22 | Accept | 0.038324 | 1.0433 | 0.037686 | 0.037677 | 0.12756 | false |
| 23 | Accept | 0.037841 | 1.123 | 0.037686 | 0.037707 | 0.1587 | false |
| 24 | Accept | 0.04014 | 0.97319 | 0.037686 | 0.03764 | 0.082293 | false |
| 25 | Accept | 0.039534 | 1.0481 | 0.037686 | 0.037656 | 0.098414 | false |
| 26 | Accept | 0.037718 | 1.1948 | 0.037686 | 0.037656 | 0.34831 | true |
| 27 | Accept | 0.42164 | 0.80799 | 0.037686 | 0.037659 | 0.57775 | true |
| 28 | Accept | 0.037733 | 1.3255 | 0.037686 | 0.037652 | 0.21148 | true |
| 29 | Accept | 0.039512 | 0.89786 | 0.037686 | 0.037648 | 0.099436 | true |
| 30 | Accept | 0.28105 | 1.8193 | 0.037686 | 0.037647 | 0.054662 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 70.1885 seconds
Total objective function evaluation time: 44.075
Best observed feasible point:
Sigma Standardize
_______ ___________
0.30638 false
Observed objective function value = 0.037686
Estimated objective function value = 0.037806
Function evaluation time = 1.5945
Best estimated feasible point (according to models):
Sigma Standardize
_______ ___________
0.21519 false
Estimated objective function value = 0.037647
Estimated function evaluation time = 1.1122
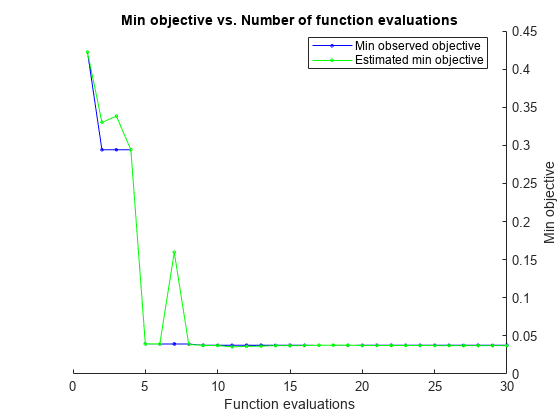

学習させた回帰モデル gprMdl2 は、最適な推定実行可能点に対応し、Sigma と Standardize に同じハイパーパラメーター値を使用しています。
bestPoint 関数を使用して、gprMdl2 の学習に使用されたハイパーパラメーター値を調べます。既定では、bestPoint は、ハイパーパラメーターの最適化時に fitrgp で使用されたものと同じ最適点の基準 ("min-visited-upper-confidence-interval") を使用します。一般に、近似関数では、データ セット内のノイズへの過適合を防ぐために、基準 "min-visited-upper-confidence-interval" (基準 "min-observed" ではなく) に基づいて最適なハイパーパラメーター値を判別します。
bestEstimatedPoint = bestPoint(gprMdl2.HyperparameterOptimizationResults)
bestEstimatedPoint=1×2 table
Sigma Standardize
_______ ___________
0.21519 false
結果が gprMdl2 のプロパティと一致することを確認します。GPR モデルで標準化を使用する場合、RegressionGP オブジェクトの PredictorLocation プロパティと PredictorScale プロパティは空以外になることに注意してください。
modelProperties = table(gprMdl2.Sigma, ... struct(Mean=gprMdl2.PredictorLocation, ... StandardDeviation=gprMdl2.PredictorScale), ... VariableNames=["Sigma","Standardize"])
modelProperties=1×2 table
Sigma Standardize
_______ ___________
0.21519 1×1 struct
modelProperties.Standardize
ans = struct with fields:
Mean: []
StandardDeviation: []
最適化前と最適化後の当てはめを視覚的に比較します。
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2); figure plot(x,y,".") hold on plot(x,ypred1) plot(x,ypred2) xlabel("x"); ylabel("y"); legend(["Data","Default fit","Optimized fit"], ... Location="best") title("Impact of Optimization") hold off
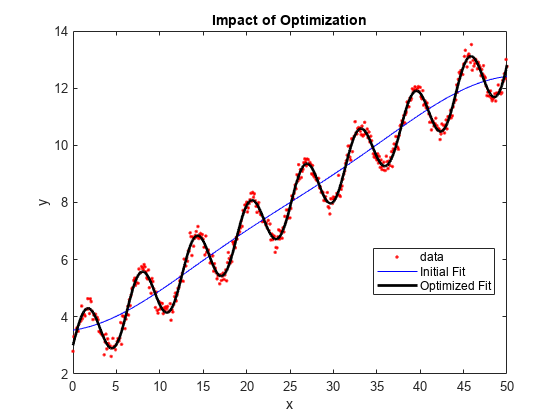
最適化されたハイパーパラメーターを使用するモデルの方が学習データによく当てはまっています。
この例では、UCI Machine Learning Repository [3]にあるアワビのデータ[1]、[2]を使用します。データをダウンロードして、abalone.data という名前で現在のフォルダに保存します。
データを table に格納します。最初の 7 行を表示します。
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height','WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20このデータセットには、4177 個の観測値が含まれています。目標は、8 つの物理的な測定値からアワビの年齢を予測することです。最後の変数は貝殻の輪の数で、アワビの年齢を示します。最初の予測子は、カテゴリカル変数です。table の最後の変数は、応答変数です。
データの 25% を検証用に使用して、交差検証 GPR モデルを学習させます。
rng('default') % For reproducibility cvgprMdl = fitrgp(tbl,'NoShellRings','Standardize',1,'Holdout',0.25);
分割外観測値で学習させたモデルを使用して、分割の平均損失を計算します。
kfoldLoss(cvgprMdl)
ans = 4.6409
分割外データの応答を予測します。
ypred = kfoldPredict(cvgprMdl);
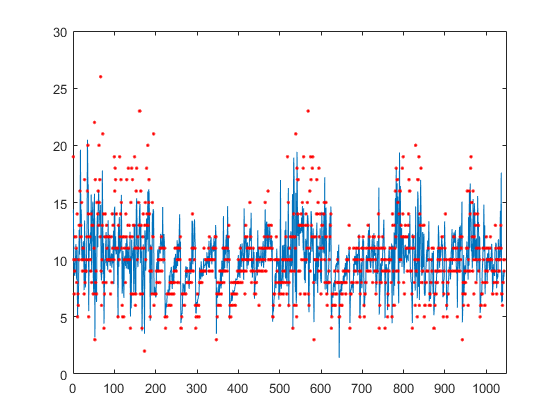
検証と予測に使用した真の応答をプロットします。
figure(); plot(ypred(cvgprMdl.Partition.test)); hold on; y = table2array(tbl(:,end)); plot(y(cvgprMdl.Partition.test),'r.'); axis([0 1050 0 30]); xlabel('x') ylabel('y') hold off;
標本データを生成します。
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
二乗指数カーネル関数をカスタムなカーネル関数として定義します。
二乗指数カーネル関数は、次のように計算できます。
ここで、 は信号標準偏差、 は長さスケールです。 と はどちらも 0 より大きくなければなりません。この条件は、制約のないパラメーター表現ベクトル について制約のないパラメーター表現 および を使用することにより適用できます。
したがって、二乗指数カーネル関数は、次のカスタムなカーネル関数として定義できます。
kfcn = @(XN,XM,theta) (exp(theta(2))^2)*exp(-(pdist2(XN,XM).^2)/(2*exp(theta(1))^2));
ここで、pdist2(XN,XM).^2 は距離行列を計算します。
カスタムなカーネル関数 kfcn を使用して、GPR モデルを当てはめます。カーネル パラメーターの初期値を指定します (カスタムなカーネル関数を使用するので、制約のないパラメーター表現ベクトル theta の初期値を指定しなければなりません)。
theta0 = [1.5,0.2]; gprMdl = fitrgp(x,y,'KernelFunction',kfcn,'KernelParameters',theta0);
組み込みカーネル関数の場合、fitrgp はパラメーター推定に解析的微分を使用します。カスタムなカーネル関数の場合は、数値微分を使用します。
このモデルの再代入損失を計算します。
L = resubLoss(gprMdl)
L = 0.0391
組み込まれている二乗指数カーネル関数オプションを使用して、GPR モデルを当てはめます。カーネル パラメーターの初期値を指定します (組み込まれているカスタムなカーネル関数を使用して初期パラメーター値を指定しているので、信号標準偏差と長さスケールの初期値を直接指定しなければなりません)。
sigmaL0 = exp(1.5); sigmaF0 = exp(0.2); gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential','KernelParameters',[sigmaL0,sigmaF0]);
このモデルの再代入損失を計算します。
L2 = resubLoss(gprMdl2)
L2 = 0.0391
予想どおり、2 つの損失の値は同じです。
生成されたデータに対して、多数の予測子を使用して GPR モデルに学習をさせます。LBFGS オプティマイザーの初期ステップ サイズを指定します。
結果に再現性をもたせるために、乱数発生器のシードとタイプを設定します。
rng(0,'twister'); % For reproducibility
300 個の観測値と 3000 個の予測子がある標本データを生成します。応答変数は 4 番目、7 番目および 13 番目の予測子に依存します。
N = 300; P = 3000; X = rand(N,P); y = cos(X(:,7)) + sin(X(:,4).*X(:,13)) + 0.1*randn(N,1);
カーネル パラメーターの初期値を設定します。
sigmaL0 = sqrt(P)*ones(P,1); % Length scale for predictors sigmaF0 = 1; % Signal standard deviation
初期ノイズ標準偏差を 1 に設定します。
sigmaN0 = 1;
相対勾配ノルムの終了許容誤差として 1e-2 を指定します。
opts = statset('fitrgp');
opts.TolFun = 1e-2;初期カーネル パラメーター値、初期ノイズ標準偏差および関連度自動決定 (ARD) 二乗指数カーネル関数を使用して GPR モデルを当てはめます。
LBFGS オプティマイザーにおけるヘッシアンの初期近似を決定するため、初期ステップ サイズとして 1 を指定します。
gpr = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Verbose',1, ... 'Optimizer','lbfgs','OptimizerOptions',opts, ... 'KernelParameters',[sigmaL0;sigmaF0],'Sigma',sigmaN0,'InitialStepSize',1);
o Parameter estimation: FitMethod = Exact, Optimizer = lbfgs
o Solver = LBFGS, HessianHistorySize = 15, LineSearchMethod = weakwolfe
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 0 | 3.004966e+02 | 2.569e+02 | 0.000e+00 | | 3.893e-03 | 0.000e+00 | YES |
| 1 | 9.525779e+01 | 1.281e+02 | 1.003e+00 | OK | 6.913e-03 | 1.000e+00 | YES |
| 2 | 3.972026e+01 | 1.647e+01 | 7.639e-01 | OK | 4.718e-03 | 5.000e-01 | YES |
| 3 | 3.893873e+01 | 1.073e+01 | 1.057e-01 | OK | 3.243e-03 | 1.000e+00 | YES |
| 4 | 3.859904e+01 | 5.659e+00 | 3.282e-02 | OK | 3.346e-03 | 1.000e+00 | YES |
| 5 | 3.748912e+01 | 1.030e+01 | 1.395e-01 | OK | 1.460e-03 | 1.000e+00 | YES |
| 6 | 2.028104e+01 | 1.380e+02 | 2.010e+00 | OK | 2.326e-03 | 1.000e+00 | YES |
| 7 | 2.001849e+01 | 1.510e+01 | 9.685e-01 | OK | 2.344e-03 | 1.000e+00 | YES |
| 8 | -7.706109e+00 | 8.340e+01 | 1.125e+00 | OK | 5.771e-04 | 1.000e+00 | YES |
| 9 | -1.786074e+01 | 2.323e+02 | 2.647e+00 | OK | 4.217e-03 | 1.250e-01 | YES |
| 10 | -4.058422e+01 | 1.972e+02 | 6.796e-01 | OK | 7.035e-03 | 1.000e+00 | YES |
| 11 | -7.850209e+01 | 4.432e+01 | 8.335e-01 | OK | 3.099e-03 | 1.000e+00 | YES |
| 12 | -1.312162e+02 | 3.334e+01 | 1.277e+00 | OK | 5.432e-02 | 1.000e+00 | YES |
| 13 | -2.005064e+02 | 9.519e+01 | 2.828e+00 | OK | 5.292e-03 | 1.000e+00 | YES |
| 14 | -2.070150e+02 | 1.898e+01 | 1.641e+00 | OK | 6.817e-03 | 1.000e+00 | YES |
| 15 | -2.108086e+02 | 3.793e+01 | 7.685e-01 | OK | 3.479e-03 | 1.000e+00 | YES |
| 16 | -2.122920e+02 | 7.057e+00 | 1.591e-01 | OK | 2.055e-03 | 1.000e+00 | YES |
| 17 | -2.125610e+02 | 4.337e+00 | 4.818e-02 | OK | 1.974e-03 | 1.000e+00 | YES |
| 18 | -2.130162e+02 | 1.178e+01 | 8.891e-02 | OK | 2.856e-03 | 1.000e+00 | YES |
| 19 | -2.139378e+02 | 1.933e+01 | 2.371e-01 | OK | 1.029e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 20 | -2.151111e+02 | 1.550e+01 | 3.015e-01 | OK | 2.765e-02 | 1.000e+00 | YES |
| 21 | -2.173046e+02 | 5.856e+00 | 6.537e-01 | OK | 1.414e-02 | 1.000e+00 | YES |
| 22 | -2.201781e+02 | 8.918e+00 | 8.484e-01 | OK | 6.381e-03 | 1.000e+00 | YES |
| 23 | -2.288858e+02 | 4.846e+01 | 2.311e+00 | OK | 2.661e-03 | 1.000e+00 | YES |
| 24 | -2.392171e+02 | 1.190e+02 | 6.283e+00 | OK | 8.113e-03 | 1.000e+00 | YES |
| 25 | -2.511145e+02 | 1.008e+02 | 1.198e+00 | OK | 1.605e-02 | 1.000e+00 | YES |
| 26 | -2.742547e+02 | 2.207e+01 | 1.231e+00 | OK | 3.191e-03 | 1.000e+00 | YES |
| 27 | -2.849931e+02 | 5.067e+01 | 3.660e+00 | OK | 5.184e-03 | 1.000e+00 | YES |
| 28 | -2.899797e+02 | 2.068e+01 | 1.162e+00 | OK | 6.270e-03 | 1.000e+00 | YES |
| 29 | -2.916723e+02 | 1.816e+01 | 3.213e-01 | OK | 1.415e-02 | 1.000e+00 | YES |
| 30 | -2.947674e+02 | 6.965e+00 | 1.126e+00 | OK | 6.339e-03 | 1.000e+00 | YES |
| 31 | -2.962491e+02 | 1.349e+01 | 2.352e-01 | OK | 8.999e-03 | 1.000e+00 | YES |
| 32 | -3.004921e+02 | 1.586e+01 | 9.880e-01 | OK | 3.940e-02 | 1.000e+00 | YES |
| 33 | -3.118906e+02 | 1.889e+01 | 3.318e+00 | OK | 1.213e-01 | 1.000e+00 | YES |
| 34 | -3.189215e+02 | 7.086e+01 | 3.070e+00 | OK | 8.095e-03 | 1.000e+00 | YES |
| 35 | -3.245557e+02 | 4.366e+00 | 1.397e+00 | OK | 2.718e-03 | 1.000e+00 | YES |
| 36 | -3.254613e+02 | 3.751e+00 | 6.546e-01 | OK | 1.004e-02 | 1.000e+00 | YES |
| 37 | -3.262823e+02 | 4.011e+00 | 2.026e-01 | OK | 2.441e-02 | 1.000e+00 | YES |
| 38 | -3.325606e+02 | 1.773e+01 | 2.427e+00 | OK | 5.234e-02 | 1.000e+00 | YES |
| 39 | -3.350374e+02 | 1.201e+01 | 1.603e+00 | OK | 2.674e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 40 | -3.379112e+02 | 5.280e+00 | 1.393e+00 | OK | 1.177e-02 | 1.000e+00 | YES |
| 41 | -3.389136e+02 | 3.061e+00 | 7.121e-01 | OK | 2.935e-02 | 1.000e+00 | YES |
| 42 | -3.401070e+02 | 4.094e+00 | 6.224e-01 | OK | 3.399e-02 | 1.000e+00 | YES |
| 43 | -3.436291e+02 | 8.833e+00 | 1.707e+00 | OK | 5.231e-02 | 1.000e+00 | YES |
| 44 | -3.456295e+02 | 5.891e+00 | 1.424e+00 | OK | 3.772e-02 | 1.000e+00 | YES |
| 45 | -3.460069e+02 | 1.126e+01 | 2.580e+00 | OK | 3.907e-02 | 1.000e+00 | YES |
| 46 | -3.481756e+02 | 1.546e+00 | 8.142e-01 | OK | 1.565e-02 | 1.000e+00 | YES |
Infinity norm of the final gradient = 1.546e+00
Two norm of the final step = 8.142e-01, TolX = 1.000e-12
Relative infinity norm of the final gradient = 6.016e-03, TolFun = 1.000e-02
EXIT: Local minimum found.
o Alpha estimation: PredictMethod = Exact
多数の予測子がある ARD カーネルを GPR モデルで使用するので、ヘッシアンに対して LBFGS 近似を使用すると、ヘッセ行列全体を格納するよりメモリ効率が向上します。また、初期ステップ サイズを使用してヘッシアンの初期近似を決定すると、最適化が高速になる可能性があります。
負の学習済み長さスケールの指数を使用して、予測子の重みを求めます。重みを正規化します。
sigmaL = gpr.KernelInformation.KernelParameters(1:end-1); % Learned length scales weights = exp(-sigmaL); % Predictor weights weights = weights/sum(weights); % Normalized predictor weights
正規化した予測子の重みをプロットします。
figure; semilogx(weights,'ro'); xlabel('Predictor index'); ylabel('Predictor weight');
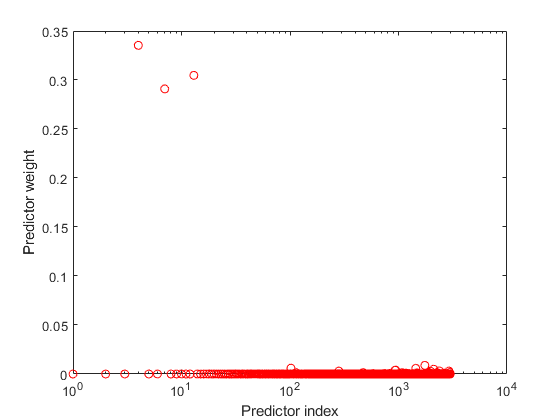
学習済みの GPR モデルは、4 番目、7 番目および 13 番目の予測子に最大の重みを割り当てています。無関係な予測子の重みはゼロに近くなります。
入力引数
名前と値の引数
出力引数
詳細
ヒント
fitrgpは、近似法、予測法およびアクティブ セット選択法についてどのような組み合わせでも受け入れます。予測した応答の標準偏差を計算できないために予測区間を計算できない場合があります。predictを参照してください。また、学習データのサイズのため、厳密法を使用すると計算コストが高くなる場合もあります。PredictorNamesプロパティには、元の予測子変数名のそれぞれについて 1 つずつ要素が格納されます。たとえば、3 つの予測子があり、そのうちの 1 つは 3 つの水準があるカテゴリカル変数である場合、PredictorNamesは 1 行 3 列の文字ベクトルの cell 配列になります。ExpandedPredictorNamesプロパティには、ダミー変数を含む予測子変数のそれぞれについて 1 つずつ要素が格納されます。たとえば、3 つの予測子があり、そのうちの 1 つは 3 つの水準があるカテゴリカル変数である場合、ExpandedPredictorNamesは 1 行 5 列の文字ベクトルの cell 配列になります。同様に、
Betaプロパティには、ダミー変数を含む各予測子について 1 つずつベータ係数が格納されます。Xプロパティには、はじめに入力した状態で学習データが格納されます。ダミー変数は含まれません。多数の予測子がある ARD カーネルを使用する場合など、GPR モデルに多数のカーネル パラメーターがある場合、
fitrgpでヘッシアン近似を初期化する既定のアプローチは低速になる可能性があります。このような場合は、"auto"または初期ステップ サイズの値を指定することを検討します。反復的診断メッセージの表示に
Verbose=1を設定し、fitrgpによる既定の最適化で LBFGS または準ニュートン オプティマイザーを使用して GPR モデルの学習を始めることができます。数秒後になっても反復的な診断メッセージが表示されない場合、ヘッシアン近似の初期化に時間がかかりすぎている可能性があります。このような場合は、学習をやり直し、最適化を高速化するために初期ステップ サイズを使用することを検討します。モデルに学習をさせた後で、新しいデータについて応答を予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
GPR モデルの当てはめでは、次のモデル パラメーターをデータから推定します。
ベクトル 内のカーネル パラメーターに関してパラメーター化された共分散関数 (カーネル (共分散) 関数のオプションを参照)
ノイズ分散
固定基底関数の係数ベクトル
名前と値の引数
KernelParametersの値は、信号標準偏差 と特性長スケール の初期値から構成されるベクトルです。これらの値を使用してカーネル パラメーターが決定されます。同様に、名前と値の引数Sigmaにはノイズ標準偏差 の初期値が格納されます。最適化時に、ノイズ標準偏差とカーネル パラメーターの初期値を使用して、制約がない初期パラメーター値のベクトル が作成されます。
名前と値の引数
Betaによって指定された明示的な基底係数 が と の推定値から解析的に決定されます。したがって、数値最適化を初期化するときに はベクトル に現れません。メモ
GPR モデルのパラメーター推定を指定しなかった場合、名前と値の引数
Betaの値と他の初期パラメーター値が既知の GPR パラメーター値として使用されます (Betaを参照)。他のすべてのケースでは、Betaの値は目的関数から解析的に最適化されます。準ニュートン オプティマイザーでは、密で対称的なランク 1 に基づく (SR1) 準ニュートン近似による信頼領域法をヘッシアンに対して使用します。LBFGS オプティマイザーでは、メモリ制限 Broyden-Fletcher-Goldfarb-Shanno (LBFGS) 準ニュートン近似による標準的な直線探索法をヘッシアンに対して使用します。Nocedal および Wright [6] を参照してください。
名前と値の引数
InitialStepSizeを"auto"に設定した場合、 を使用して初期ステップ サイズ が決定されます。は初期ステップ ベクトル、 は制約がない初期パラメーター値のベクトルです。
最適化時に、初期ステップ サイズ が次のように使用されます。
Optimizer="quasinewton"と初期ステップ サイズを指定した場合、ヘッシアンの初期近似は になります。Optimizer="lbfgs"と初期ステップ サイズを指定した場合、逆ヘッシアンの初期近似は になります。は初期勾配ベクトル、 は単位行列です。
参照
[1] Nash, W.J., T. L. Sellers, S. R. Talbot, A. J. Cawthorn, and W. B. Ford. "The Population Biology of Abalone (Haliotis species) in Tasmania. I. Blacklip Abalone (H. rubra) from the North Coast and Islands of Bass Strait." Sea Fisheries Division, Technical Report No. 48, 1994.
[2] Waugh, S. "Extending and Benchmarking Cascade-Correlation: Extensions to the Cascade-Correlation Architecture and Benchmarking of Feed-forward Supervised Artificial Neural Networks." University of Tasmania Department of Computer Science thesis, 1995.
[3] Lichman, M. UCI Machine Learning Repository, Irvine, CA: University of California, School of Information and Computer Science, 2013. http://archive.ics.uci.edu/ml.
[4] Rasmussen, C. E. and C. K. I. Williams. Gaussian Processes for Machine Learning. MIT Press. Cambridge, Massachusetts, 2006.
[5] Lagarias, J. C., J. A. Reeds, M. H. Wright, and P. E. Wright. "Convergence Properties of the Nelder-Mead Simplex Method in Low Dimensions." SIAM Journal of Optimization. Vol. 9, Number 1, 1998, pp. 112–147.
[6] Nocedal, J. and S. J. Wright. Numerical Optimization, Second Edition. Springer Series in Operations Research, Springer Verlag, 2006.