TreeBagger
バギングされた決定木のアンサンブル
説明
TreeBagger オブジェクトは、分類または回帰のいずれかについてバギングされた決定木のアンサンブルです。個々の決定木には、過適合になる傾向があります。bootstrap aggregation を意味する "バギング" は、過適合の影響を減らして汎化を改善するアンサンブル法です。
作成
関数 TreeBagger は、入力データのブートストラップ標本を使用して、TreeBagger アンサンブル モデル内のすべての木を成長させます。標本に含まれない観測値は、その木にとって "out-of-bag" と見なされます。この関数は、ランダム フォレスト アルゴリズム[1]を使用して、各決定分岐の予測子のサブセットを無作為に選択します。
構文
説明
ヒント
既定では、関数 TreeBagger は分類決定木を成長させます。回帰決定木を成長させるには、名前と値の引数 Method を "regression" として指定します。
Mdl = TreeBagger(NumTrees,Tbl,ResponseVarName)Tbl 内の予測子と変数 Tbl.ResponseVarName 内のクラス ラベルによって学習させた、NumTrees 本のバギング分類木のアンサンブル オブジェクト (Mdl) を返します。
Mdl = TreeBagger(NumTrees,Tbl,formula)Tbl 内の予測子によって学習させた Mdl を返します。入力 formula は、Mdl を当てはめるために使用する Tbl 内の予測子変数のサブセットおよび応答の説明モデルです。formula はウィルキンソンの表記法を使用して指定します。
Mdl = TreeBagger(___,Name=Value)Mdl を返します。たとえば、名前と値の引数 PredictorSelection を使用して、カテゴリカル予測子での最適な分割を検出するためのアルゴリズムを指定できます。
入力引数
名前と値の引数
出力引数
プロパティ
オブジェクト関数
例
フィッシャーのアヤメのデータ セット用にバギング分類木のアンサンブルを作成します。次に、最初の成長した木を表示し、out-of-bag 分類誤差をプロットして、out-of-bag 観測値のラベルを予測します。
fisheriris データ セットを読み込みます。150 本のアヤメについて 4 つの測定値が含まれる数値行列 X を作成します。対応するアヤメの種類が含まれる文字ベクトルの cell 配列 Y を作成します。
load fisheriris
X = meas;
Y = species;再現性を得るため、乱数発生器を default に設定します。
rng("default")データ セット全体を使用して、バギング分類木のアンサンブルに学習をさせます。50 個の弱学習器を指定します。各木の out-of-bag 観測値を格納します。既定の設定では、TreeBagger は木を深く成長させます。
Mdl = TreeBagger(50,X,Y,... Method="classification",... OOBPrediction="on")
Mdl =
TreeBagger
Ensemble with 50 bagged decision trees:
Training X: [150x4]
Training Y: [150x1]
Method: classification
NumPredictors: 4
NumPredictorsToSample: 2
MinLeafSize: 1
InBagFraction: 1
SampleWithReplacement: 1
ComputeOOBPrediction: 1
ComputeOOBPredictorImportance: 0
Proximity: []
ClassNames: 'setosa' 'versicolor' 'virginica'
Properties, Methods
Mdl は分類木の TreeBagger アンサンブルです。
Mdl.Trees プロパティは、アンサンブルの学習済み分類木を格納する 50 行 1 列の cell ベクトルです。それぞれの木は CompactClassificationTree オブジェクトです。最初の学習済み分類木をグラフィックで表示します。
view(Mdl.Trees{1},Mode="graph")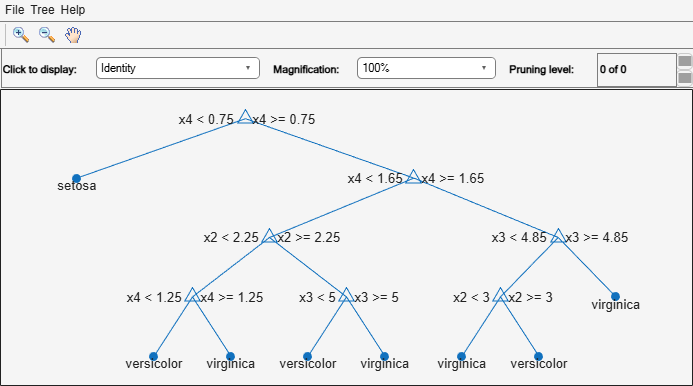
out-of-bag 分類誤差を、成長した分類木の数にプロットします。
plot(oobError(Mdl)) xlabel("Number of Grown Trees") ylabel("Out-of-Bag Classification Error")
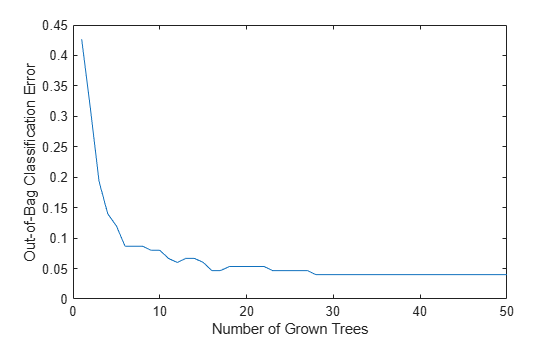
成長した木の数が増加すると、out-of-bag 誤差は減少します。
out-of-bag 観測値のラベルを予測します。10 件の観測値の無作為なセットについて結果を表示します。
oobLabels = oobPredict(Mdl); ind = randsample(length(oobLabels),10); table(Y(ind),oobLabels(ind),... VariableNames=["TrueLabel" "PredictedLabel"])
ans=10×2 table
TrueLabel PredictedLabel
______________ ______________
{'setosa' } {'setosa' }
{'virginica' } {'virginica' }
{'setosa' } {'setosa' }
{'virginica' } {'virginica' }
{'setosa' } {'setosa' }
{'virginica' } {'virginica' }
{'setosa' } {'setosa' }
{'versicolor'} {'versicolor'}
{'versicolor'} {'virginica' }
{'virginica' } {'virginica' }
carsmall データ セット用にバギング回帰木のアンサンブルを作成します。次に、条件付き平均応答と条件付き四分位数を予測します。
carsmall データ セットを読み込みます。自動車のエンジン排気量の値を格納する数値ベクトルとして X を作成します。ガロンあたりの走行マイル数を格納する数値ベクトルとして Y を作成します。
load carsmall
X = Displacement;
Y = MPG;再現性を得るため、乱数発生器を default に設定します。
rng("default")データ セット全体を使用して、バギング回帰木のアンサンブルに学習をさせます。100 個の弱学習器を指定します。
Mdl = TreeBagger(100,X,Y,... Method="regression")
Mdl =
TreeBagger
Ensemble with 100 bagged decision trees:
Training X: [94x1]
Training Y: [94x1]
Method: regression
NumPredictors: 1
NumPredictorsToSample: 1
MinLeafSize: 5
InBagFraction: 1
SampleWithReplacement: 1
ComputeOOBPrediction: 0
ComputeOOBPredictorImportance: 0
Proximity: []
Properties, Methods
Mdl は回帰木用の TreeBagger アンサンブルです。
標本内の最小値と最大値の間で 10 等分したエンジン排気量について、条件付き平均応答 (YMean) と条件付き四分位数 (YQuartiles) を予測します。
predX = linspace(min(X),max(X),10)';
YMean = predict(Mdl,predX);
YQuartiles = quantilePredict(Mdl,predX,...
Quantile=[0.25,0.5,0.75]);観測値、推定された平均応答、および推定された四分位数をプロットします。
hold on plot(X,Y,"o"); plot(predX,YMean) plot(predX,YQuartiles) hold off ylabel("Fuel Economy") xlabel("Engine Displacement") legend("Data","Mean Response",... "First Quartile","Median",..., "Third Quartile")

バギング回帰木の 2 つのアンサンブルを作成します。1 つは予測子の分割に標準 CART アルゴリズムを使用し、もう 1 つは予測子の分割に曲率検定を使用します。次に、2 つのアンサンブルについて予測子の重要度の推定を比較します。
carsmall データ セットを読み込み、変数 Cylinders、Mfg、および Model_Year をカテゴリカル変数に変換します。次に、カテゴリカル変数で表現されるカテゴリの個数を表示します。
load carsmall
Cylinders = categorical(Cylinders);
Mfg = categorical(cellstr(Mfg));
Model_Year = categorical(Model_Year);
numel(categories(Cylinders))ans = 3
numel(categories(Mfg))
ans = 28
numel(categories(Model_Year))
ans = 3
8 つの自動車のメトリクスを含む table を作成します。
Tbl = table(Acceleration,Cylinders,Displacement,...
Horsepower,Mfg,Model_Year,Weight,MPG);再現性を得るため、乱数発生器を default に設定します。
rng("default")データ セット全体を使用して、200 本のバギング回帰木のアンサンブルに学習をさせます。欠損値がデータに含まれているので、代理分岐を使用するように指定します。予測子の重要度の推定に関する out-of-bag 情報を格納します。
既定では、TreeBagger は、予測子を分割するためのアルゴリズムである標準 CART を使用します。変数 Cylinders と変数 Model_Year にはそれぞれ 3 つしかカテゴリがないので、標準 CART ではこの 2 つの変数よりも連続予測子が分割されます。
MdlCART = TreeBagger(200,Tbl,"MPG",... Method="regression",Surrogate="on",... OOBPredictorImportance="on");
TreeBagger は、予測子の重要度の推定を OOBPermutedPredictorDeltaError プロパティに格納します。
impCART = MdlCART.OOBPermutedPredictorDeltaError;
データ セット全体を使用して、200 本の回帰木のランダム フォレストに学習をさせます。偏りの無い木を成長させるため、予測子の分割に曲率検定を使用するよう指定します。
MdlUnbiased = TreeBagger(200,Tbl,"MPG",... Method="regression",Surrogate="on",... PredictorSelection="curvature",... OOBPredictorImportance="on"); impUnbiased = MdlUnbiased.OOBPermutedPredictorDeltaError;
棒グラフを作成して、2 つのアンサンブルについて予測子の重要度の推定 impCART および impUnbiased を比較します。
tiledlayout(1,2,Padding="compact"); nexttile bar(impCART) title("Standard CART") ylabel("Predictor Importance Estimates") xlabel("Predictors") h = gca; h.XTickLabel = MdlCART.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = "none"; nexttile bar(impUnbiased); title("Curvature Test") ylabel("Predictor Importance Estimates") xlabel("Predictors") h = gca; h.XTickLabel = MdlUnbiased.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = "none";

CART モデルでは、連続予測子 Weight は 2 番目に最も重要な予測子です。不偏のモデルでは、Weight の予測子の重要度は値とランクが下がっています。
tall 配列内の観測値に対するバギング分類木のアンサンブルに学習をさせ、観測値に重みを付けてモデル内の各木の誤分類確率を求めます。この例ではデータ セット airlinesmall.csv を使用します。これは、飛行機のフライト データについての表形式ファイルが含まれている大規模なデータ セットです。
tall 配列に対する計算を実行する場合、MATLAB® は並列プール (Parallel Computing Toolbox™ がある場合は既定) またはローカルの MATLAB セッションを使用します。Parallel Computing Toolbox がある場合にローカルの MATLAB セッションを使用して例を実行するには、関数 mapreducer を使用してグローバルな実行環境を変更します。
mapreducer(0)
データ セットが含まれているフォルダーの場所を参照するデータストアを作成します。処理する変数のサブセットを選択します。関数 datastore で NaN 値に置き換えるため、"NA" 値を欠損データとして扱います。データストア内のデータを含む tall table tt を作成します。
ds = datastore("airlinesmall.csv"); ds.SelectedVariableNames = ["Month" "DayofMonth" "DayOfWeek",... "DepTime" "ArrDelay" "Distance" "DepDelay"]; ds.TreatAsMissing = "NA"; tt = tall(ds)
tt =
M×7 tall table
Month DayofMonth DayOfWeek DepTime ArrDelay Distance DepDelay
_____ __________ _________ _______ ________ ________ ________
10 21 3 642 8 308 12
10 26 1 1021 8 296 1
10 23 5 2055 21 480 20
10 23 5 1332 13 296 12
10 22 4 629 4 373 -1
10 28 3 1446 59 308 63
10 8 4 928 3 447 -2
10 10 6 859 11 954 -1
: : : : : : :
: : : : : : :
フライトが遅れた場合に真になる論理変数を定義することにより、10 分以上遅れたフライトを判別します。この変数にクラス ラベル Y を含めます。この変数のプレビューには、はじめの数行が含まれています。
Y = tt.DepDelay > 10
Y = M×1 tall logical array 1 0 1 1 0 1 0 0 : :
予測子データの tall 配列 X を作成します。
X = tt{:,1:end-1}X =
M×6 tall double matrix
10 21 3 642 8 308
10 26 1 1021 8 296
10 23 5 2055 21 480
10 23 5 1332 13 296
10 22 4 629 4 373
10 28 3 1446 59 308
10 8 4 928 3 447
10 10 6 859 11 954
: : : : : :
: : : : : :
クラス 1 の観測値に 2 倍の重みを任意に割り当てることにより、観測値の重みに対する tall 配列 W を作成します。
W = Y+1;
欠損データが含まれている X、Y および W の行を削除します。
R = rmmissing([X Y W]); X = R(:,1:end-2); Y = R(:,end-1); W = R(:,end);
データ セット全体を使用して、20 本のバギング分類木のアンサンブルに学習をさせます。重みベクトルと一様な事前確率を指定します。再現性を得るため、rng と tallrng を使用して乱数発生器のシードを設定します。tall 配列の場合、ワーカーの個数と実行環境によって結果が異なる可能性があります。詳細については、コードの実行場所の制御を参照してください。
rng("default") tallrng("default") tMdl = TreeBagger(20,X,Y,... Weights=W,Prior="uniform")
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.47 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 1.5 sec Evaluation completed in 1.6 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 3.8 sec Evaluation completed in 3.8 sec
tMdl =
CompactTreeBagger
Ensemble with 20 bagged decision trees:
Method: classification
NumPredictors: 6
ClassNames: '0' '1'
Properties, Methods
tMdl は、20 本のバギングされた決定木による CompactTreeBagger アンサンブルです。tall データの場合、関数 TreeBagger は CompactTreeBagger オブジェクトを返します。
モデル内の各木の誤分類確率を計算します。名前と値の引数 Weights を使用して、ベクトル W に格納されている重みを各観測値に適用します。
terr = error(tMdl,X,Y,Weights=W)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 4.7 sec Evaluation completed in 4.7 sec
terr = 20×1
0.1420
0.1214
0.1115
0.1078
0.1037
0.1027
0.1005
0.0997
0.0981
0.0983
⋮
決定木のアンサンブルについて、平均の誤分類確率を求めます。
avg_terr = mean(terr)
avg_terr = 0.1022
詳細
ヒント
TreeBaggerモデルMdlのTreesプロパティには、Mdl.NumTrees個のCompactClassificationTreeオブジェクトまたはCompactRegressionTreeオブジェクトの cell ベクトルが格納されます。t番目の成長した木をグラフィックで表示するには次のように入力します。view(Mdl.Trees{t})回帰問題の場合、
TreeBaggerは平均および分位点回帰 (つまり、分位点回帰フォレスト[5]) をサポートします。与えられたデータに対する平均応答の予測または平均二乗誤差の推定を行うには、
TreeBaggerモデル オブジェクトとデータをpredictまたはerrorにそれぞれ渡します。out-of-bag 観測値について同様の操作を実行するには、oobPredictまたはoobErrorを使用します。与えられたデータに対する応答分布の分位数または分位数誤差を推定するには、
TreeBaggerモデル オブジェクトとデータをquantilePredictまたはquantileErrorにそれぞれ渡します。out-of-bag 観測値について同様の操作を実行するには、oobQuantilePredictまたはoobQuantileErrorを使用します。
標準 CART には、相違する値が少ない分割予測子 (カテゴリカル変数など) よりも、相違する値が多い分割予測子 (連続変数など) を選択する傾向があります[4]。以下のいずれかに該当する場合は、曲率検定または交互作用検定の指定を検討してください。
データに、相違する値の個数が他の予測子よりも比較的少ない予測子がある場合 (予測子データ セットが異種混合である場合など)。
目的は、予測子の重要度を分析することです。
TreeBaggerは、予測子の重要度の推定をOOBPermutedPredictorDeltaErrorプロパティに格納します。
予測子の選択に関する詳細については、分類木の場合は名前と値の引数
PredictorSelectionを、回帰木の場合は名前と値の引数PredictorSelectionを参照してください。
アルゴリズム
名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列 (C) が変更なしで格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。モデルの学習用に、事前確率と観測値の重みが更新されて、コスト行列で指定されているペナルティが組み込まれます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。関数
TreeBaggerは誤分類コストが大きいクラスをオーバーサンプリングし、誤分類コストが小さいクラスをアンダーサンプリングして、in-bag の標本を生成します。その結果、out-of-bag の標本では、誤分類コストが大きいクラスの観測値は少なくなり、誤分類コストが小さいクラスの観測値は多くなります。小さなデータ セットと歪みが大きいコスト行列を使用してアンサンブル分類を学習させる場合、クラスあたりの out-of-bag の観測値の数は非常に少なくなることがあります。そのため、推定された out-of-bag の誤差の変動幅が非常に大きくなり、解釈が困難になる場合があります。事前確率が大きいクラスでも同じ現象が発生する場合があります。決定木を成長させるときの関数
TreeBaggerによる分割予測子の選択方法とノード分割アルゴリズムの詳細については、分類木の場合はアルゴリズムを、回帰木の場合はアルゴリズムを参照してください。
代替機能
Statistics and Machine Learning Toolbox™ には、バギングおよびランダム フォレスト用に 3 つのオブジェクトが用意されています。
関数
fitcensembleによって作成される分類用のClassificationBaggedEnsembleオブジェクト関数
fitrensembleによって作成される回帰用のRegressionBaggedEnsembleオブジェクト関数
TreeBaggerによって作成される分類および回帰用のTreeBaggerオブジェクト
TreeBagger とバギング アンサンブル (ClassificationBaggedEnsemble および RegressionBaggedEnsemble) の違いについては、TreeBagger とバギング アンサンブルの比較を参照してください。
参照
[1] Breiman, Leo. "Random Forests." Machine Learning 45 (2001): 5–32. https://doi.org/10.1023/A:1010933404324.
[2] Breiman, Leo, Jerome Friedman, Charles J. Stone, and R. A. Olshen. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
[3] Loh, Wei-Yin. "Regression Trees with Unbiased Variable Selection and Interaction Detection." Statistica Sinica 12, no. 2 (2002): 361–386. https://www.jstor.org/stable/24306967.
[4] Loh, Wei-Yin, and Yu-Shan Shih. "Split Selection for Classification Trees." Statistica Sinica 7, no. 4 (1997): 815–840. https://www.jstor.org/stable/24306157.
[5] Meinshausen, Nicolai. "Quantile Regression Forests." Journal of Machine Learning Research 7, no. 35 (2006): 983–999. https://jmlr.org/papers/v7/meinshausen06a.html.
[6] Genuer, Robin, Jean-Michel Poggi, Christine Tuleau-Malot, and Nathalie Villa-Vialanei. "Random Forests for Big Data." Big Data Research 9 (2017): 28–46. https://doi.org/10.1016/j.bdr.2017.07.003.