quantilePredict
回帰の bag of trees の使用による応答の分位数の予測
構文
説明
YFit = quantilePredict(Mdl,X)Mdl を使用して、予測子データのテーブルまたは行列 X における予測応答の中央値のベクトルを返します。Mdl は TreeBagger モデル オブジェクトでなければなりません。
YFit = quantilePredict(Mdl,X,Name,Value)Name,Value 引数のペアによって指定された追加オプションを使用します。たとえば、分位確率を指定したり分位推定に含める木を指定したりします。
入力引数
名前と値の引数
出力引数
例
carsmall データ セットを読み込みます。与えられたエンジン排気量に対して自動車の燃費を予測するモデルを考えます。
load carsmallデータ セット全体を使用して、バギング回帰木のアンサンブルに学習をさせます。100 個の弱学習器を指定します。
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression');
Mdl は TreeBagger アンサンブルです。
分位点回帰を実行して、すべての並べ替えられた学習観測値について MPG の中央値を予測します。
medianMPG = quantilePredict(Mdl,sort(Displacement));
medianMPG は、並べ替えられた Displacement 内の観測値が与えられた場合の応答の条件付き分布に対応する中央値が含まれている n 行 1 列の数値ベクトルです。n は Displacement 内の観測値の個数です。
同じ Figure に観測値と推定された中央値をプロットします。中央値および平均応答を比較します。
meanMPG = predict(Mdl,sort(Displacement)); figure; plot(Displacement,MPG,'k.'); hold on plot(sort(Displacement),medianMPG); plot(sort(Displacement),meanMPG,'r--'); ylabel('Fuel economy'); xlabel('Engine displacement'); legend('Data','Median','Mean'); hold off;

carsmall データ セットを読み込みます。与えられたエンジン排気量に対して自動車の燃費を予測するモデルを考えます。
load carsmallデータ セット全体を使用して、バギング回帰木のアンサンブルに学習をさせます。100 個の弱学習器を指定します。
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression');
分位点回帰を実行して、標本内の最小値と最大値の間で 10 等分したエンジン排気量について 2.5% および 97.5% の百分位数を予測します。
predX = linspace(min(Displacement),max(Displacement),10)';
quantPredInts = quantilePredict(Mdl,predX,'Quantile',[0.025,0.975]);quantPredInts は、predX 内の観測値に対応する予測区間が含まれている 10 行 2 列の数値行列です。1 列目には 2.5% 百分位数が、2 列目には 97.5% 百分位数が含まれています。
同じ Figure に観測値と推定された中央値をプロットします。MPG の条件付き分布がガウス分布であると仮定して、百分位数の予測区間と 95% の予測区間を比較します。
[meanMPG,steMeanMPG] = predict(Mdl,predX); stndPredInts = meanMPG + [-1 1]*norminv(0.975).*steMeanMPG; figure; h1 = plot(Displacement,MPG,'k.'); hold on h2 = plot(predX,quantPredInts,'b'); h3 = plot(predX,stndPredInts,'r--'); ylabel('Fuel economy'); xlabel('Engine displacement'); legend([h1,h2(1),h3(1)],{'Data','95% percentile prediction intervals',... '95% Gaussian prediction intervals'}); hold off;

carsmall データ セットを読み込みます。与えられたエンジン排気量に対して自動車の燃費を予測するモデルを考えます。
load carsmallデータ セット全体を使用して、バギング回帰木のアンサンブルに学習をさせます。100 個の弱学習器を指定します。
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression');
4 つの学習観測値の無作為標本について、応答の重みを予測します。学習標本をプロットし、選択された観測値を特定します。
[predX,idx] = datasample(Mdl.X,4); [~,YW] = quantilePredict(Mdl,predX); n = numel(Mdl.Y); figure; plot(Mdl.X,Mdl.Y,'o'); hold on plot(predX,Mdl.Y(idx),'*','MarkerSize',10); text(predX-10,Mdl.Y(idx)+1.5,{'obs. 1' 'obs. 2' 'obs. 3' 'obs. 4'}); legend('Training Data','Chosen Observations'); xlabel('Engine displacement') ylabel('Fuel economy') hold off

YW は、応答の重みが含まれている n 行 4 列のスパース行列です。列はテスト観測値に、行は学習標本内の応答に対応します。応答の重みは、指定された分位確率に依存しません。
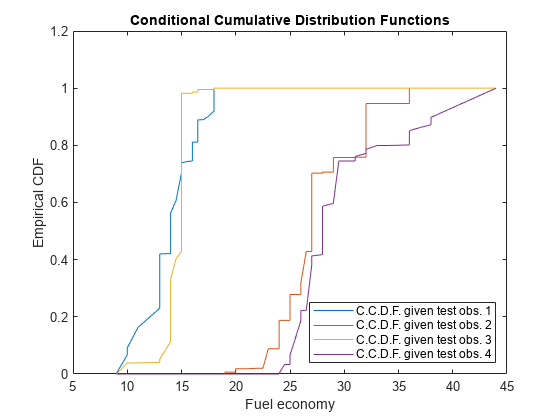
以下により、応答の条件付き累積分布関数 (CCDF) を推定します。
応答を昇順にソートし、さらにそれによって導かれたインデックスを使用して応答の重みをソートします。
並べ替えられた応答の重みの各列に対する累積和を計算します。
[sortY,sortIdx] = sort(Mdl.Y); cpdf = full(YW(sortIdx,:)); ccdf = cumsum(cpdf);
ccdf(:,j) は、与えられたテスト観測値 j に対する応答の経験 CCDF です。
同じ Figure に 4 つの経験 CCDF をプロットします。
figure; plot(sortY,ccdf); legend('C.C.D.F. given test obs. 1','C.C.D.F. given test obs. 2',... 'C.C.D.F. given test obs. 3','C.C.D.F. given test obs. 4',... 'Location','SouthEast') title('Conditional Cumulative Distribution Functions') xlabel('Fuel economy') ylabel('Empirical CDF')
詳細
ヒント
quantilePredict は、呼び出されるたびに学習データを使用して応答の条件付き分布を推定します。多数の分位数または多数の観測値についての分位数を効率的に予測するには、観測値の行列またはテーブルとして X を渡し、名前と値のペアの引数 Quantile を使用してベクトルですべての分位数を指定します。つまり、ループ内では quantilePredict を呼び出さないようにします。
アルゴリズム
TreeBaggerは、学習データを使用して回帰木のランダム フォレストを成長させます。そして、分位点ランダム フォレストを実装するため、quantilePredictは与えられた予測子変数の観測値に対する応答の経験的な条件付き分布を使用して分位数を予測します。応答の経験的な条件付き分布を取得するため、以下を行います。quantilePredictは、アンサンブル内のすべての木を介してMdl.X内のすべての学習観測値を渡し、学習観測値が属している葉ノードを格納します。quantilePredictは同様に、アンサンブル内のすべての木を介してX内の各観測値を渡します。X内の各観測値について、quantilePredictは以下を行います。各木の応答の重みを計算することにより、応答の条件付き分布を推定します。
X内の観測値 k について、アンサンブル全体に対する条件付き分布を集約します。n は学習観測値の個数 (
size(Y,1))、T はアンサンブル内の木の本数 (Mdl.NumTrees) です。
X内の観測値 k について、τ の分位数、つまり 100τ% の百分位数は になります。
quantilePredictは、すべての指定された重みを以下のようにして使用します。すべての学習観測値 j = 1,...,n およびすべての選択された木 t = 1,...,T について、
quantilePredictは (Mdl.X(とj,:)Mdl.Y(に格納されている) 学習観測値 j に対して積 vtj = btjwj,obs を求めます。btj は、木 t のブートストラップ標本に観測値 j が含まれていた回数です。wj,obs はj)Mdl.W(内の観測値の重みです。j)選択された各木について、
quantilePredictは各学習観測値が属する葉を特定します。観測値 j が属している木 t の葉に含まれているすべての観測値の集合を St(xj) とします。選択された各木について、
quantilePredictは特定の葉に含まれているすべての重みを合計が 1 になるように正規化します。つまり、次のようになります。各学習観測値および木について、
quantilePredictはTreeWeightsで指定された木の重み (wt,tree) を組み込みます。つまり、w*tj,tree = wt,treevtj* を求めます。予測に選択されなかった木の重みは 0 になります。X内のすべての検定観測値 k = 1,...,K および選択されたすべての木 t = 1,...,T について、quantilePredictは観測値が属する一意な葉を予測し、予測した葉に含まれるすべての学習観測値を特定します。quantilePredictは、次のように重み utj を割り当てます。quantilePredictは、選択されたすべての木に対する重みを合計します。つまり、次のようになります。quantilePredictは、合計が 1 になるように重みを正規化することにより、応答の重みを作成します。つまり、次のようになります。
参考文献
[1] Breiman, L. "Random Forests." Machine Learning 45, pp. 5–32, 2001.
[2] Meinshausen, N. “Quantile Regression Forests.” Journal of Machine Learning Research, Vol. 7, 2006, pp. 983–999.
バージョン履歴
R2016b で導入