quantileError
回帰の bag of trees の使用による分位点損失
構文
説明
err = quantileError(Mdl,X)Mdl を X 内の予測子データの観測値に適用することにより予測した中央値に対してテーブル X 内の真の応答を比較して、平均絶対偏差 (MAD) の 1/2 を返します。
MdlはTreeBaggerモデル オブジェクトでなければなりません。X内の応答変数名は、学習データが格納されているテーブルに含まれている応答変数の名前と同じでなければなりません。
err = quantileError(Mdl,X,ResponseVarName)X に含まれている真の応答および予測子の変数を使用します。ResponseVarName は応答変数の名前です。Mdl.PredictorNames には予測子変数の名前を格納します。
err = quantileError(___,Name,Value)Name,Value ペア引数によって指定される追加オプションを使用します。たとえば、分位確率、誤差のタイプ、分位点回帰誤差の推定に含める木を指定します。
入力引数
名前と値の引数
出力引数
例
carsmall データ セットを読み込みます。与えられたエンジン排気量、重量および気筒数に対して自動車の燃費の平均を予測するモデルを考えます。Cylinders はカテゴリカル変数であるとします。
load carsmall
Cylinders = categorical(Cylinders);
X = table(Displacement,Weight,Cylinders,MPG);データ セット全体を使用して、バギング回帰木のアンサンブルに学習をさせます。100 個の弱学習器を指定します。
rng(1); % For reproducibility Mdl = TreeBagger(100,X,'MPG','Method','regression');
Mdl は TreeBagger アンサンブルです。
分位点回帰を実行し、予測された条件付き中央値を使用してアンサンブル全体の MAD を推定します。
err = quantileError(Mdl,X)
err = 1.2339
X は応答および同等の変数名が含まれているテーブルなので、応答変数の名前またはデータを指定する必要はありません。ただし、次の構文を使用して応答を指定することができます。
err = quantileError(Mdl,X,'MPG')err = 1.2339
carsmall データ セットを読み込みます。与えられたエンジン排気量、重量および気筒数に対して自動車の燃費の平均を予測するモデルを考えます。
load carsmall
X = table(Displacement,Weight,Cylinders,MPG);データの 75% を学習セットに、25% をテスト セットに無作為に分割します。サブセットのインデックスを抽出します。
rng(1); % For reproducibility cvp = cvpartition(size(X,1),'Holdout',0.25); idxTrn = training(cvp); idxTest = test(cvp);
学習セットを使用して、バギング回帰木のアンサンブルに学習をさせます。250 個の弱学習器を指定します。
Mdl = TreeBagger(250,X(idxTrn,:),'MPG','Method','regression');
テスト セットについて、0.25、0.5 および 0.75 の累積的な分位点回帰誤差を推定します。予測子データを数値行列として、応答データをベクトルとして渡します。
err = quantileError(Mdl,X{idxTest,1:3},MPG(idxTest),'Quantile',[0.25 0.5 0.75],...
'Mode','cumulative');err は、累積的な分位点回帰誤差が含まれている 250 行 3 列の行列です。列は分位確率に、行はアンサンブル内の木に対応します。誤差は累積的なので、前の木から集約した予測が含まれています。Mdl の学習にはテーブルを使用しましたが、テーブル内の予測子変数がすべて数値型である場合は、代わりに予測子データの行列を指定することができます。
同じプロットに累積的な分位数誤差をプロットします。
figure; plot(err); legend('0.25 quantile error','0.5 quantile error','0.75 quantile error'); ylabel('Quantile error'); xlabel('Tree index'); title('Cumulative Quantile Regression Error')
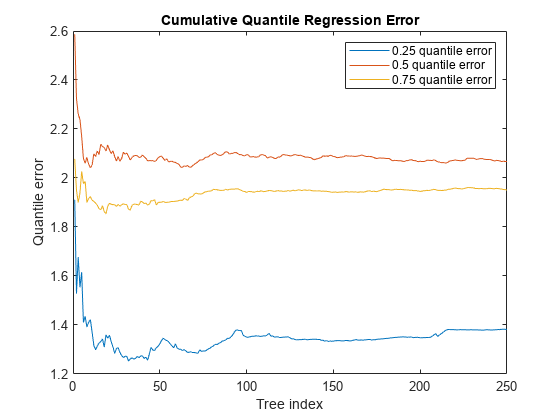
初めの 2 つの四分位数については約 60 本の木を使用して学習をさせれば十分であると考えられますが、3 番目の四分位数には約 150 本の木が必要です。
詳細
ヒント
アンサンブル内の木の本数を調整するには、
'Mode','cumulative'を設定し、木のインデックスに対して分位点回帰誤差をプロットします。必要な木の最大本数は、分位点回帰誤差が横ばい状態になる木のインデックスです。学習標本が小さい場合にモデルの性能を調べるには、代わりに
oobQuantileErrorを使用します。
参考文献
[1] Breiman, L. Random Forests. Machine Learning 45, pp. 5–32, 2001.
[2] Meinshausen, N. “Quantile Regression Forests.” Journal of Machine Learning Research, Vol. 7, 2006, pp. 983–999.
バージョン履歴
R2016b で導入