kfoldPredict
交差検証済み分類モデルの観測値の分類
構文
説明
label = kfoldPredict(CVMdl,'IncludeInteractions',includeInteractions)
例
判別分析モデルの 10 分割の交差検証予測を使用して、混同行列を作成します。
fisheriris データ セットを読み込みます。X には 150 種類の花に関する花の測定値が格納されており、y は各花の種類またはクラスの一覧です。クラスの順序を指定する変数 order を作成します。
load fisheriris
X = meas;
y = species;
order = unique(y)order = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
関数 fitcdiscr を使用して、10 分割の交差検証判別分析モデルを作成します。既定では、fitcdiscr により、学習セットとテスト セットで花の種類の比率がほぼ同じになることが保証されます。花のクラスの順序を指定します。
cvmdl = fitcdiscr(X,y,'KFold',10,'ClassNames',order);
テスト セットの花の種類を予測します。
predictedSpecies = kfoldPredict(cvmdl);
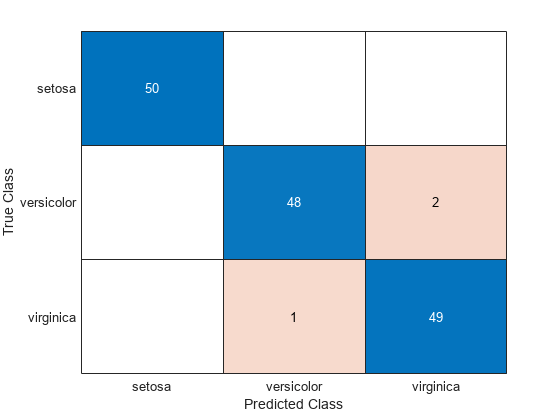
真のクラス値を予測したクラス値と比較する混同行列を作成します。
confusionchart(y,predictedSpecies)
フィッシャーのアヤメのデータに基づいてモデルの交差検証予測を求めます。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheririsAdaBoostM2 を使用して分類木のアンサンブルに学習をさせます。弱学習器として木の切り株を指定します。
rng(1); % For reproducibility t = templateTree('MaxNumSplits',1); Mdl = fitcensemble(meas,species,'Method','AdaBoostM2','Learners',t);
10 分割交差検証を使用して学習済みアンサンブルを交差検証します。
CVMdl = crossval(Mdl);
ラベルとスコアを予測された交差検証を推定します。
[elabel,escore] = kfoldPredict(CVMdl);
各クラスの最大スコアと最小スコアを表示します。
max(escore)
ans = 1×3
9.3862 8.9871 10.1866
min(escore)
ans = 1×3
0.0018 3.8359 0.9573
最初にホールドアウト検証を使用して分割し、次に 3 分割交差検証を使用して分割した分類モデルについて、それらの損失と予測を計算します。2 つの損失と予測のセットを比較します。
fisheriris データ セットから table を作成します。このデータ セットには、3 種のアヤメの花のがく片と花弁からの長さと幅の測定値が含まれています。最初の 8 つの観測値を表示します。
fisheriris = readtable("fisheriris.csv");
head(fisheriris) SepalLength SepalWidth PetalLength PetalWidth Species
___________ __________ ___________ __________ __________
5.1 3.5 1.4 0.2 {'setosa'}
4.9 3 1.4 0.2 {'setosa'}
4.7 3.2 1.3 0.2 {'setosa'}
4.6 3.1 1.5 0.2 {'setosa'}
5 3.6 1.4 0.2 {'setosa'}
5.4 3.9 1.7 0.4 {'setosa'}
4.6 3.4 1.4 0.3 {'setosa'}
5 3.4 1.5 0.2 {'setosa'}
データの分割にはcvpartitionを使用します。まず、観測値の約 70% を学習データ、約 30% を検証データに使用して、ホールドアウト検証用の分割を作成します。次に、3 分割交差検証用の分割を作成します。
rng(0,"twister") % For reproducibility holdoutPartition = cvpartition(fisheriris.Species,Holdout=0.30); kfoldPartition = cvpartition(fisheriris.Species,KFold=3);
holdoutPartition と kfoldPartition は、どちらも無作為な層化区分です。それぞれtraining関数とtest関数を使用して、学習セットと検証セットにおける観測値のインデックスを特定できます。
fisheriris のデータを使用して分類木モデルに学習させます。応答変数として Species を指定します。
Mdl = fitctree(fisheriris,"Species");crossval を使用して、分割された分類モデルを作成します。
holdoutMdl = crossval(Mdl,CVPartition=holdoutPartition)
holdoutMdl =
ClassificationPartitionedModel
CrossValidatedModel: 'Tree'
PredictorNames: {'SepalLength' 'SepalWidth' 'PetalLength' 'PetalWidth'}
ResponseName: 'Species'
NumObservations: 150
KFold: 1
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
kfoldMdl = crossval(Mdl,CVPartition=kfoldPartition)
kfoldMdl =
ClassificationPartitionedModel
CrossValidatedModel: 'Tree'
PredictorNames: {'SepalLength' 'SepalWidth' 'PetalLength' 'PetalWidth'}
ResponseName: 'Species'
NumObservations: 150
KFold: 3
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
holdoutMdl と kfoldMdl は ClassificationPartitionedModel オブジェクトです。
kfoldLoss を使用して、holdoutMdl と kfoldMdl の最小予測誤分類コストを計算します。どちらのモデルも既定のコスト行列を使用しているため、このコストは分類誤差と同じになります。
holdoutL = kfoldLoss(holdoutMdl)
holdoutL = 0.0889
kfoldL = kfoldLoss(kfoldMdl)
kfoldL = 0.0600
holdoutL は 1 つの検証セットに対する予測を使用して計算された誤差で、kfoldL は検証データの 3 つの分割に対する予測を使用して計算された平均誤差です。未観測データに対するモデルの性能については、交差検証のメトリクスの方が優れた指標となる傾向があります。
kfoldPredict を使用して、2 つのモデルの検証データの予測を計算します。
[holdoutLabels,holdoutScores] = kfoldPredict(holdoutMdl); [kfoldLabels,kfoldScores] = kfoldPredict(kfoldMdl); holdoutClassNames = holdoutMdl.ClassNames; holdoutScores = array2table(holdoutScores,VariableNames=holdoutClassNames); kfoldClassNames = kfoldMdl.ClassNames; kfoldScores = array2table(kfoldScores,VariableNames=kfoldClassNames); predictions = table(holdoutLabels,kfoldLabels, ... holdoutScores,kfoldScores, ... VariableNames=["holdoutMdl Labels","kfoldMdl Labels", ... "holdoutMdl Scores","kfoldMdl Scores"])
predictions=150×4 table
holdoutMdl Labels kfoldMdl Labels holdoutMdl Scores kfoldMdl Scores
_________________ _______________ _________________________________ _________________________________
setosa versicolor virginica setosa versicolor virginica
______ __________ _________ ______ __________ _________
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
⋮
holdoutMdl.Trained の学習に使用された観測値に対して、kfoldPredict は NaN スコアを返します。これらの観測値について、関数は最も頻度が高いクラス ラベルを予測ラベルとして選択します。このケースでは、すべてのクラスの頻度が同じであるため、関数は最初のクラス (setosa) を予測ラベルとして選択します。関数は、学習させたモデルを使用して検証セットの観測値に対する予測を返します。kfoldPredict は、その観測値を使用せずに学習させた kfoldMdl.Trained のモデルを使用して kfoldMdl のそれぞれの予測を返します。
未観測データに対する応答を予測するには、holdoutMdl や kfoldMdl などの分割されたモデルではなく、データ セット全体で学習させたモデル (Mdl) とその predict 関数を使用します。
入力引数
出力引数
アルゴリズム
kfoldPredict は、対応するオブジェクト関数 predict で説明されているように、予測を計算します。モデル固有の説明については、次の表に示す該当する関数 predict のリファレンス ページを参照してください。