kfoldMargin
学習で使用しない観測値の分類マージン
説明
m = kfoldMargin(CVMdl,Name,Value)Name,Value 引数のペアによって指定された追加オプションを使用します。たとえば、復号化方式や詳細レベルを指定します。
入力引数
名前と値の引数
出力引数
例
NLP のデータ セットを読み込みます。
load nlpdataX は予測子データのスパース行列、Y はクラス ラベルの categorical ベクトルです。
簡単にするため、'simulink'、'dsp'、'comm' のいずれでもない Y の観測値すべてに対して 'others' というラベルを使用します。
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';マルチクラス線形分類モデルを交差検証します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learner','linear','CrossVal','on');
CVMdl は ClassificationPartitionedLinearECOC モデルです。既定では、10 分割交差検証が実行されます。'KFold' 名前と値のペアの引数を使用して分割数を変更できます。
k 分割マージンを推定します。
m = kfoldMargin(CVMdl); size(m)
ans = 1×2
31572 1
m は 31572 行 1 列のベクトルです。m(j) は観測値 j の分割外マージンの平均です。
箱ひげ図を使用して k 分割マージンをプロットします。
figure;
boxplot(m);
h = gca;
h.YLim = [-5 5];
title('Distribution of Cross-Validated Margins')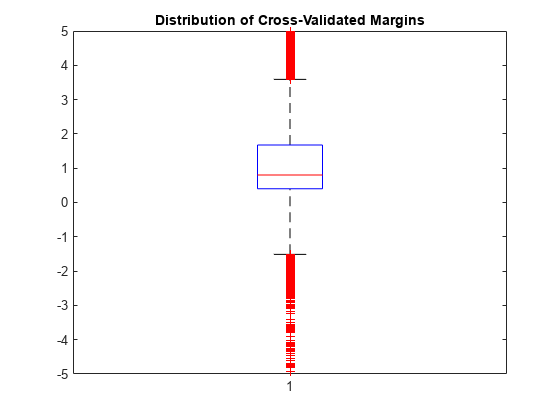
特徴選択を実行する方法の 1 つは、複数のモデルの k 分割マージンを比較することです。この基準のみに基づくと、マージンが大きい方が分類器として優れています。
NLP のデータ セットを読み込みます。k 分割交差検証マージンの推定で説明されているようにデータを前処理し、観測値が列に対応するように予測子データを配置します。
load nlpdata Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others'; X = X';
2 つのデータ セットを作成します。
fullXにはすべての予測子が含まれます。partXには、無作為に選択した予測子の 1/2 が含まれます。
rng(1); % For reproducibility p = size(X,1); % Number of predictors halfPredIdx = randsample(p,ceil(0.5*p)); fullX = X; partX = X(halfPredIdx,:);
SpaRSA を使用して目的関数を最適化するように指定する線形分類モデル テンプレートを作成します。
t = templateLinear('Solver','sparsa');
バイナリ線形分類モデルから構成されている 2 つの ECOC モデルを交差検証します。1 つではすべての予測子を、もう 1 つでは半分の予測子を使用します。観測値が列に対応することを指定します。
CVMdl = fitcecoc(fullX,Y,'Learners',t,'CrossVal','on',... 'ObservationsIn','columns'); PCVMdl = fitcecoc(partX,Y,'Learners',t,'CrossVal','on',... 'ObservationsIn','columns');
CVMdl および PCVMdl は ClassificationPartitionedLinearECOC モデルです。
各分類器の k 分割マージンを推定します。箱ひげ図を使用して k 分割マージン セットの分布をプロットします。
fullMargins = kfoldMargin(CVMdl); partMargins = kfoldMargin(PCVMdl); figure; boxplot([fullMargins partMargins],'Labels',... {'All Predictors','Half of the Predictors'}); h = gca; h.YLim = [-1 1]; title('Distribution of Cross-Validated Margins')
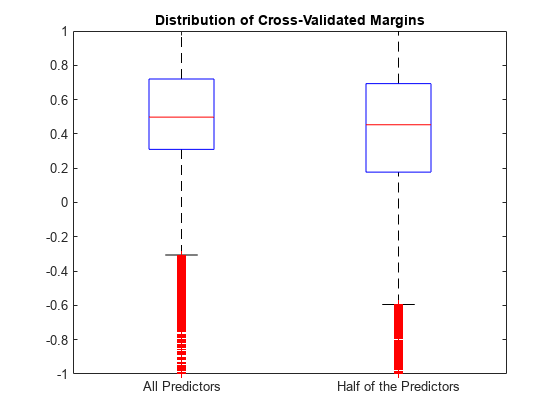
2 つの分類器で k 分割マージンの分布は似ています。
ロジスティック回帰学習器を使用する線形分類モデルに適した LASSO ペナルティの強度を決定するため、k 分割マージンの分布を比較します。
NLP のデータ セットを読み込みます。k 分割マージンを使用した特徴選択で説明されているようにデータを前処理します。
load nlpdata Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others'; X = X';
~ の範囲で対数間隔で配置された 11 個の正則化強度を作成します。
Lambda = logspace(-8,1,11);
線形分類モデル テンプレートを作成します。このテンプレートでは、LASSO ペナルティがあるロジスティック回帰を使用し、各正則化強度を使用し、SpaRSA を使用して目的関数を最適化し、目的関数の勾配の許容誤差を 1e-8 に下げるように指定します。
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8);
5 分割の交差検証を使用して、バイナリ線形分類モデルから構成されている ECOC モデルを交差検証します。
rng(10); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns','KFold',5)
CVMdl =
ClassificationPartitionedLinearECOC
CrossValidatedModel: 'LinearECOC'
ResponseName: 'Y'
NumObservations: 31572
KFold: 5
Partition: [1×1 cvpartition]
ClassNames: [comm dsp simulink others]
ScoreTransform: 'none'
Properties, Methods
CVMdl は ClassificationPartitionedLinearECOC モデルです。
各正則化強度の k 分割マージンを推定します。ロジスティック回帰のスコアは [0,1] の範囲にあります。二次バイナリ損失を適用します。
m = kfoldMargin(CVMdl,'BinaryLoss','quadratic'); size(m)
ans = 1×2
31572 11
m は各観測値の交差検証マージンから構成される 31572 行 11 列の行列です。列は正則化強度に対応します。
各正則化強度について k 分割マージンをプロットします。
figure; boxplot(m) ylabel('Cross-validated margins') xlabel('Lambda indices')

いくつかの Lambda の値では、同じようにマージン分布の中心が高くなっており、広がりが少なくなっています。Lambda の値が大きくなると、予測子変数がスパースになります。これは分類器の品質として優れています。
マージン分布の中心が低下し広がりが大きくなる直前にある正則化強度を選択します。
LambdaFinal = Lambda(5);
データ セット全体を使用して、線形分類モデルから構成されている ECOC モデルに学習をさせます。正則化強度として LambdaFinal を指定します。
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda(5),'GradientTolerance',1e-8); MdlFinal = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns');
新しい観測値のラベルを推定するには、MdlFinal と新しいデータを predict に渡します。