kfoldLoss
交差検証済み分類モデルの分類損失
説明
例
ionosphere データ セットを読み込みます。
load ionosphere分類木を成長させます。
tree = fitctree(X,Y);
10 分割交差検証を使用して分類木を交差検証します。
cvtree = crossval(tree);
交差検証分類誤差を推定します。
L = kfoldLoss(cvtree)
L = 0.1083
ionosphere データ セットを読み込みます。
load ionosphereAdaBoostM1 を使用して、100 本の決定木によるアンサンブル分類に学習をさせます。弱学習器として木の切り株を指定します。
t = templateTree('MaxNumSplits',1); ens = fitcensemble(X,Y,'Method','AdaBoostM1','Learners',t);
10 分割交差検証を使用してアンサンブルを交差検証します。
cvens = crossval(ens);
交差検証分類誤差を推定します。
L = kfoldLoss(cvens)
L = 0.0655
最初にホールドアウト検証を使用して分割し、次に 3 分割交差検証を使用して分割した分類モデルについて、それらの損失と予測を計算します。2 つの損失と予測のセットを比較します。
fisheriris データ セットから table を作成します。このデータ セットには、3 種のアヤメの花のがく片と花弁からの長さと幅の測定値が含まれています。最初の 8 つの観測値を表示します。
fisheriris = readtable("fisheriris.csv");
head(fisheriris) SepalLength SepalWidth PetalLength PetalWidth Species
___________ __________ ___________ __________ __________
5.1 3.5 1.4 0.2 {'setosa'}
4.9 3 1.4 0.2 {'setosa'}
4.7 3.2 1.3 0.2 {'setosa'}
4.6 3.1 1.5 0.2 {'setosa'}
5 3.6 1.4 0.2 {'setosa'}
5.4 3.9 1.7 0.4 {'setosa'}
4.6 3.4 1.4 0.3 {'setosa'}
5 3.4 1.5 0.2 {'setosa'}
データの分割にはcvpartitionを使用します。まず、観測値の約 70% を学習データ、約 30% を検証データに使用して、ホールドアウト検証用の分割を作成します。次に、3 分割交差検証用の分割を作成します。
rng(0,"twister") % For reproducibility holdoutPartition = cvpartition(fisheriris.Species,Holdout=0.30); kfoldPartition = cvpartition(fisheriris.Species,KFold=3);
holdoutPartition と kfoldPartition は、どちらも無作為な層化区分です。それぞれtraining関数とtest関数を使用して、学習セットと検証セットにおける観測値のインデックスを特定できます。
fisheriris のデータを使用して分類木モデルに学習させます。応答変数として Species を指定します。
Mdl = fitctree(fisheriris,"Species");crossval を使用して、分割された分類モデルを作成します。
holdoutMdl = crossval(Mdl,CVPartition=holdoutPartition)
holdoutMdl =
ClassificationPartitionedModel
CrossValidatedModel: 'Tree'
PredictorNames: {'SepalLength' 'SepalWidth' 'PetalLength' 'PetalWidth'}
ResponseName: 'Species'
NumObservations: 150
KFold: 1
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
kfoldMdl = crossval(Mdl,CVPartition=kfoldPartition)
kfoldMdl =
ClassificationPartitionedModel
CrossValidatedModel: 'Tree'
PredictorNames: {'SepalLength' 'SepalWidth' 'PetalLength' 'PetalWidth'}
ResponseName: 'Species'
NumObservations: 150
KFold: 3
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
holdoutMdl と kfoldMdl は ClassificationPartitionedModel オブジェクトです。
kfoldLoss を使用して、holdoutMdl と kfoldMdl の最小予測誤分類コストを計算します。どちらのモデルも既定のコスト行列を使用しているため、このコストは分類誤差と同じになります。
holdoutL = kfoldLoss(holdoutMdl)
holdoutL = 0.0889
kfoldL = kfoldLoss(kfoldMdl)
kfoldL = 0.0600
holdoutL は 1 つの検証セットに対する予測を使用して計算された誤差で、kfoldL は検証データの 3 つの分割に対する予測を使用して計算された平均誤差です。未観測データに対するモデルの性能については、交差検証のメトリクスの方が優れた指標となる傾向があります。
kfoldPredict を使用して、2 つのモデルの検証データの予測を計算します。
[holdoutLabels,holdoutScores] = kfoldPredict(holdoutMdl); [kfoldLabels,kfoldScores] = kfoldPredict(kfoldMdl); holdoutClassNames = holdoutMdl.ClassNames; holdoutScores = array2table(holdoutScores,VariableNames=holdoutClassNames); kfoldClassNames = kfoldMdl.ClassNames; kfoldScores = array2table(kfoldScores,VariableNames=kfoldClassNames); predictions = table(holdoutLabels,kfoldLabels, ... holdoutScores,kfoldScores, ... VariableNames=["holdoutMdl Labels","kfoldMdl Labels", ... "holdoutMdl Scores","kfoldMdl Scores"])
predictions=150×4 table
holdoutMdl Labels kfoldMdl Labels holdoutMdl Scores kfoldMdl Scores
_________________ _______________ _________________________________ _________________________________
setosa versicolor virginica setosa versicolor virginica
______ __________ _________ ______ __________ _________
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} 1 0 0 1 0 0
{'setosa'} {'setosa'} NaN NaN NaN 1 0 0
⋮
holdoutMdl.Trained の学習に使用された観測値に対して、kfoldPredict は NaN スコアを返します。これらの観測値について、関数は最も頻度が高いクラス ラベルを予測ラベルとして選択します。このケースでは、すべてのクラスの頻度が同じであるため、関数は最初のクラス (setosa) を予測ラベルとして選択します。関数は、学習させたモデルを使用して検証セットの観測値に対する予測を返します。kfoldPredict は、その観測値を使用せずに学習させた kfoldMdl.Trained のモデルを使用して kfoldMdl のそれぞれの予測を返します。
未観測データに対する応答を予測するには、holdoutMdl や kfoldMdl などの分割されたモデルではなく、データ セット全体で学習させたモデル (Mdl) とその predict 関数を使用します。
交差検証済みの 10 分割の一般化加法モデル (GAM) に学習させます。その後、kfoldLoss を使用して交差検証の累積分類誤差 (10 進数の誤分類率) を計算します。誤差を使用して、予測子 (予測子の線形項) あたりの最適な木の数と交互作用項あたりの最適な木の数を特定します。
代わりに、名前と値の引数OptimizeHyperparametersを使用して fitcgam の名前と値の引数の最適な値を特定することもできます。例については、OptimizeHyperparameters を使用した GAM の最適化を参照してください。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphere既定の交差検証オプションを使用して交差検証済み GAM を作成します。名前と値の引数 'CrossVal' を 'on' として指定します。p 値が 0.05 以下である利用可能な交互作用項をすべて含めるように指定します。
rng('default') % For reproducibility CVMdl = fitcgam(X,Y,'CrossVal','on','Interactions','all','MaxPValue',0.05);
'Mode' を 'cumulative' として指定すると、関数 kfoldLoss は累積誤差を返します。これは、各分割に同じ数の木を使用して取得したすべての分割の平均誤差です。各分割の木の数を表示します。
CVMdl.NumTrainedPerFold
ans = struct with fields:
PredictorTrees: [65 64 59 61 60 66 65 62 64 61]
InteractionTrees: [1 2 2 2 2 1 2 2 2 2]
kfoldLoss では、最大で 59 個の予測子木と 1 個の交互作用木を使用して累積誤差を計算できます。
10 分割交差検証を行った累積分類誤差 (10 進数の誤分類率) をプロットします。'IncludeInteractions' を false として指定して、計算から交互作用項を除外します。
L_noInteractions = kfoldLoss(CVMdl,'Mode','cumulative','IncludeInteractions',false); figure plot(0:min(CVMdl.NumTrainedPerFold.PredictorTrees),L_noInteractions)

L_noInteractions の最初の要素は、切片 (定数) 項のみを使用して取得したすべての分割の平均誤差です。L_noInteractions の (J+1) 番目の要素は、切片項と各線形項の最初の J 個の予測子木を使用して取得した平均誤差です。累積損失をプロットすると、GAM の予測子木の数が増えるにつれて誤差がどのように変化するかを観察できます。
最小誤差とその最小誤差の達成時に使用された予測子木の数を調べます。
[M,I] = min(L_noInteractions)
M = 0.0655
I = 23
GAM に 22 個の予測子木が含まれるときに誤差が最小になっています。
線形項と交互作用項の両方を使用して累積分類誤差を計算します。
L = kfoldLoss(CVMdl,'Mode','cumulative')
L = 2×1
0.0712
0.0712
L の最初の要素は、切片 (定数) 項と各線形項のすべての予測子木を使用して取得したすべての分割の平均誤差です。L の 2 番目の要素は、切片項、各線形項のすべての予測子木、および各交互作用項の 1 つの交互作用木を使用して取得した平均誤差です。交互作用項を追加しても誤差は小さくなっていません。
予測子木の数が 22 個のときの誤差で問題がなければ、一変量の GAM にもう一度学習させ、交差検証を使用せずに 'NumTreesPerPredictor',22 と指定して予測モデルを作成できます。
入力引数
名前と値の引数
出力引数
詳細
"分類損失" 関数は分類モデルの予測誤差を評価します。複数のモデルで同じタイプの損失を比較した場合、損失が低い方が予測モデルとして優れていることになります。
以下のシナリオを考えます。
L は加重平均分類損失です。
n は標本サイズです。
バイナリ分類は以下です。
yj は観測されたクラス ラベルです。陰性クラスを示す -1 または陽性クラスを示す 1 (あるいは、
ClassNamesプロパティの最初のクラスを示す -1 または 2 番目のクラスを示す 1) を使用して符号化されます。f(Xj) は予測子データ X の観測値 (行) j に対する陽性クラスの分類スコアです。
mj = yjf(Xj) は、yj に対応するクラスに観測値 j を分類する分類スコアです。正の値の mj は正しい分類を示しており、平均損失に対する寄与は大きくありません。負の値の mj は正しくない分類を示しており、平均損失に大きく寄与します。
マルチクラス分類 (つまり、K ≥ 3) をサポートするアルゴリズムの場合、次のようになります。
yj* は、K - 1 個の 0 と、観測された真のクラス yj に対応する位置の 1 から構成されるベクトルです。たとえば、2 番目の観測値の真のクラスが 3 番目のクラスであり K = 4 の場合、y2* = [
0 0 1 0]′ になります。クラスの順序は入力モデルのClassNamesプロパティ内の順序に対応します。f(Xj) は予測子データ X の観測値 j に対するクラス スコアのベクトルで、長さは K です。スコアの順序は入力モデルの
ClassNamesプロパティ内のクラスの順序に対応します。mj = yj*′f(Xj).したがって mj は、観測された真のクラスについてモデルが予測するスカラー分類スコアです。
観測値 j の重みは wj です。観測値の重みは、その合計が
Priorプロパティに格納された対応するクラスの事前確率になるように正規化されます。そのため、次のようになります。
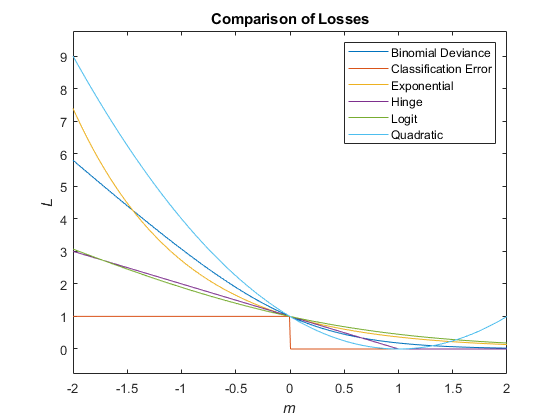
この状況では、名前と値の引数 LossFun を使用して指定できる、サポートされる損失関数は次の表のようになります。
| 損失関数 | LossFun の値 | 式 |
|---|---|---|
| 二項分布からの逸脱度 | "binodeviance" | |
| 観測誤分類コスト | "classifcost" | ここで、 はスコアが最大のクラスに対応するクラス ラベル、 は真のクラスが yj である場合に観測値をクラス に分類するユーザー指定のコストです。 |
| 10 進数の誤分類率 | "classiferror" | ここで、I{·} はインジケーター関数です。 |
| クロスエントロピー損失 | "crossentropy" |
加重クロスエントロピー損失は次となります。 ここで重み は、合計が 1 ではなく n になるように正規化されます。 |
| 指数損失 | "exponential" | |
| ヒンジ損失 | "hinge" | |
| ロジスティック損失 | "logit" | |
| 最小予測誤分類コスト | "mincost" |
重み付きの最小予測分類コストは、次の手順を観測値 j = 1、...、n について使用することにより計算されます。
最小予測誤分類コスト損失の加重平均は次となります。 |
| 二次損失 | "quadratic" |
既定のコスト行列 (正しい分類の場合の要素値は 0、誤った分類の場合の要素値は 1) を使用する場合、"classifcost"、"classiferror"、および "mincost" の損失の値は同じです。既定以外のコスト行列をもつモデルでは、ほとんどの場合は "classifcost" の損失と "mincost" の損失が等価になります。これらの損失が異なる値になる可能性があるのは、最大の事後確率をもつクラスへの予測と最小の予測コストをもつクラスへの予測が異なる場合です。"mincost" は分類スコアが事後確率の場合にしか適さないことに注意してください。
次の図では、1 つの観測値のスコア m に対する損失関数 ("classifcost"、"crossentropy"、および "mincost" を除く) を比較しています。いくつかの関数は、点 (0,1) を通過するように正規化されています。
アルゴリズム
kfoldLoss は、対応するオブジェクト関数 loss で説明されているように、分類損失を計算します。モデル固有の説明については、次の表に示す該当する関数 loss のリファレンス ページを参照してください。