kfoldMargin
交差検証済みカーネル ECOC モデルの分類マージン
説明
margin = kfoldMargin(CVMdl)ClassificationPartitionedKernelECOC) CVMdl によって取得した分類マージンを返します。kfoldMargin は、すべての分割について、学習分割観測値に対して学習をさせたモデルを使用して、検証分割観測値の分類マージンを計算します。
margin = kfoldMargin(CVMdl,Name,Value)
例
フィッシャーのアヤメのデータ セットを読み込みます。X には花の測定値が、Y には花の種類の名前が格納されています。
load fisheriris
X = meas;
Y = species;カーネル バイナリ学習器から構成される ECOC モデルを交差検証します。
CVMdl = fitcecoc(X,Y,'Learners','kernel','CrossVal','on')
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl は ClassificationPartitionedKernelECOC モデルです。既定では、10 分割交差検証が実行されます。異なる分割数を指定するには、'Crossval' ではなく名前と値のペアの引数 'KFold' を指定します。
検証分割観測値の分類マージンを推定します。
m = kfoldMargin(CVMdl); size(m)
ans = 1×2
150 1
m は 150 行 1 列のベクトルです。m(j) は観測値 j の分類マージンです。
箱ひげ図を使用して k 分割マージンをプロットします。
boxplot(m,'Labels','All Observations') title('Distribution of Margins')
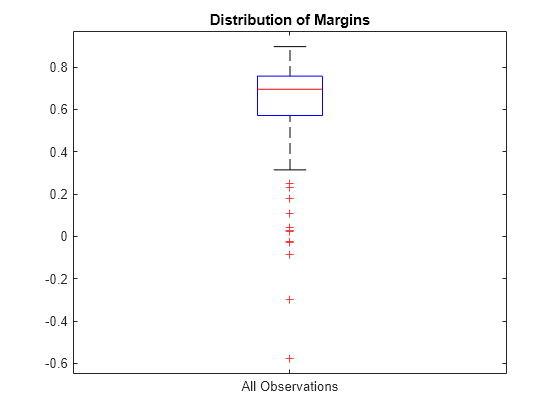
複数のモデルの k 分割マージンを比較することにより、特徴選択を実行します。この条件のみに基づくと、マージンが最大である分類器が最善の分類器となります。
フィッシャーのアヤメのデータ セットを読み込みます。X には花の測定値が、Y には花の種類の名前が格納されています。
load fisheriris
X = meas;
Y = species;予測子変数の半分を無作為に選択します。
rng(1); % For reproducibility p = size(X,2); % Number of predictors idxPart = randsample(p,ceil(0.5*p));
カーネル分類モデルから構成されている 2 つの ECOC モデルを交差検証します。1 つではすべての予測子を、もう 1 つでは半分の予測子を使用します。
CVMdl = fitcecoc(X,Y,'Learners','kernel','CrossVal','on'); PCVMdl = fitcecoc(X(:,idxPart),Y,'Learners','kernel','CrossVal','on');
CVMdl および PCVMdl は ClassificationPartitionedKernelECOC モデルです。既定では、10 分割交差検証が実行されます。異なる分割数を指定するには、'Crossval' ではなく名前と値のペアの引数 'KFold' を指定します。
各分類器の k 分割マージンを推定します。
fullMargins = kfoldMargin(CVMdl); partMargins = kfoldMargin(PCVMdl);
箱ひげ図を使用して、マージン セットの分布をプロットします。
boxplot([fullMargins partMargins], ... 'Labels',{'All Predictors','Half of the Predictors'}); title('Distribution of Margins')
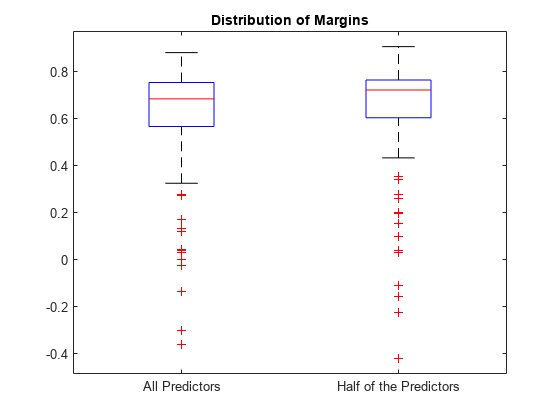
PCVMdl のマージン分布は CVMdl のマージン分布に似ています。