kfoldLoss
学習で使用しない観測値の分類損失
説明
L = kfoldLoss(CVMdl,Name,Value)Name,Value 引数のペアによって指定された追加オプションを使用します。たとえば、復号化方式、損失の計算に使用する分割、詳細レベルなどを指定します。
入力引数
名前と値の引数
出力引数
例
NLP のデータ セットを読み込みます。
load nlpdataX は予測子データのスパース行列、Y はクラス ラベルの categorical ベクトルです。
線形分類モデルから構成されている ECOC モデルを交差検証します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learner','linear','CrossVal','on');
CVMdl は ClassificationPartitionedLinearECOC モデルです。既定では、10 分割交差検証が実行されます。
分割外分類誤差率の平均を推定します。
ce = kfoldLoss(CVMdl)
ce = 0.0958
または、名前と値のペアの引数 'Mode','individual' を kfoldLoss で指定することにより、分割ごとの分類誤差率を取得できます。
NLP のデータ セットを読み込みます。予測子データを転置します。
load nlpdata
X = X';簡単にするため、'simulink'、'dsp'、'comm' のいずれでもない Y の観測値すべてに対して 'others' というラベルを使用します。
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';SpaRSA を使用して目的関数を最適化するように指定する線形分類モデル テンプレートを作成します。
t = templateLinear('Solver','sparsa');
5 分割の交差検証を使用して、線形分類モデルから構成されている ECOC モデルを交差検証します。SpaRSA を使用して目的関数を最適化します。予測子の観測値が列に対応することを指定します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'KFold',5,'ObservationsIn','columns'); CMdl1 = CVMdl.Trained{1}
CMdl1 =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [comm dsp simulink others]
ScoreTransform: 'none'
BinaryLearners: {6×1 cell}
CodingMatrix: [4×6 double]
Properties, Methods
CVMdl は ClassificationPartitionedLinearECOC モデルです。このモデルに含まれている Trained プロパティは、各分割の学習セットを使用して学習させた CompactClassificationECOC モデルを格納する 5 行 1 列の cell 配列です。
各観測値の最小損失を取る関数を作成し、すべての観測値の最小損失を平均化します。この関数ではクラス識別行列 (C)、観測値の重み (W)、および分類コスト (Cost) を使用しないので、~ を使用して kfoldLoss にそれらの位置を無視させます。
lossfun = @(~,S,~,~)mean(min(-S,[],2));
観測値ごとの最小損失を求める関数を使用して、平均の交差検証分類損失を推定します。また、各分割の損失を取得します。
ce = kfoldLoss(CVMdl,'LossFun',lossfun)ce = 0.0485
ceFold = kfoldLoss(CVMdl,'LossFun',lossfun,'Mode','individual')
ceFold = 5×1
0.0488
0.0511
0.0496
0.0479
0.0452
ロジスティック回帰学習器を使用する線形分類モデルから構成される ECOC モデルに適した LASSO ペナルティの強度を決定するため、5 分割の交差検証を実装します。
NLP のデータ セットを読み込みます。
load nlpdataX は予測子データのスパース行列、Y はクラス ラベルの categorical ベクトルです。
簡単にするため、'simulink'、'dsp'、'comm' のいずれでもない Y の観測値すべてに対して 'others' というラベルを使用します。
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';~ の範囲で対数間隔で配置された 11 個の正則化強度を作成します。
Lambda = logspace(-7,-2,11);
ロジスティック回帰学習器を使用するように指定する線形分類モデル テンプレートを作成し、Lambda の強度をもつ LASSO ペナルティを使用し、SpaRSA を使用して学習させ、目的関数の勾配の許容誤差を 1e-8 に下げます。
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8);
モデルを交差検証します。実行速度を向上させるため、予測子データを転置し、観測値が列単位であることを指定します。
X = X'; rng(10); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns','KFold',5);
CVMdl は ClassificationPartitionedLinearECOC モデルです。
CVMdl および格納されている各モデルを分析します。
numECOCModels = numel(CVMdl.Trained)
numECOCModels = 5
ECOCMdl1 = CVMdl.Trained{1}ECOCMdl1 =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [comm dsp simulink others]
ScoreTransform: 'none'
BinaryLearners: {6×1 cell}
CodingMatrix: [4×6 double]
Properties, Methods
numCLModels = numel(ECOCMdl1.BinaryLearners)
numCLModels = 6
CLMdl1 = ECOCMdl1.BinaryLearners{1}CLMdl1 =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [-1 1]
ScoreTransform: 'logit'
Beta: [34023×11 double]
Bias: [-0.3169 -0.3169 -0.3168 -0.3168 -0.3168 -0.3167 -0.1725 -0.0805 -0.1762 -0.3450 -0.5174]
Lambda: [1.0000e-07 3.1623e-07 1.0000e-06 3.1623e-06 1.0000e-05 3.1623e-05 1.0000e-04 3.1623e-04 1.0000e-03 0.0032 0.0100]
Learner: 'logistic'
Properties, Methods
fitcecoc は 5 分割の交差検証を実装するので、各分割について学習させる CompactClassificationECOC モデルから構成される 5 行 1 列の cell 配列が CVMdl に格納されます。各 CompactClassificationECOC モデルの BinaryLearners プロパティには ClassificationLinear モデルが格納されます。各コンパクト ECOC モデル内の ClassificationLinear モデルの数は、それぞれのラベルの数と符号化設計によって決まります。Lambda は正則化強度のシーケンスなので、CLMdl1 はそれぞれが Lambda の各正則化強度に対応する 11 個のモデルであると考えることができます。
各正則化強度について 5 分割分類誤差の平均をプロットすることにより、モデルがどの程度一般化を行うかを判断します。グリッド全体で汎化誤差を最小化する正則化強度を特定します。
ce = kfoldLoss(CVMdl); figure; plot(log10(Lambda),log10(ce)) [~,minCEIdx] = min(ce); minLambda = Lambda(minCEIdx); hold on plot(log10(minLambda),log10(ce(minCEIdx)),'ro'); ylabel('log_{10} 5-fold classification error') xlabel('log_{10} Lambda') legend('MSE','Min classification error') hold off
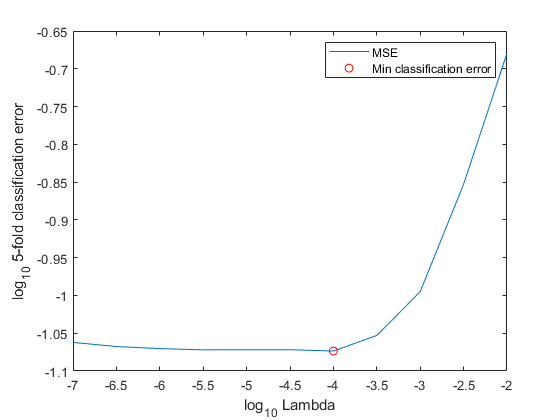
データ セット全体を使用して線形分類モデルから構成される ECOC モデルに学習をさせ、最小の正則化強度を指定します。
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',minLambda,'GradientTolerance',1e-8); MdlFinal = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns');
新しい観測値のラベルを推定するには、MdlFinal と新しいデータを predict に渡します。