kfoldPredict
学習で使用しない観測値のラベルの予測
構文
説明
Label = kfoldPredict(CVMdl,Name,Value)Name,Value のペア引数により指定された追加オプションを使用して、予測クラス ラベルを返します。たとえば、事後確率推定法、復号化スキームまたは詳細レベルを指定します。
入力引数
名前と値の引数
出力引数
例
NLP のデータ セットを読み込みます。
load nlpdataX は予測子データのスパース行列、Y はクラス ラベルの categorical ベクトルです。
線形分類モデルから構成されている ECOC モデルを交差検証します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learner','linear','CrossVal','on');
CVMdl は ClassificationPartitionedLinearECOC モデルです。既定では、10 分割交差検証が実行されます。
fitcecoc で分割の学習に使用されなかった観測値のラベルを予測します。
label = kfoldPredict(CVMdl);
CVMdl 内の正則化強度は 1 つなので、label は予測の列ベクトルになり、行数は X 内の観測値数と同じになります。
混同行列を作成します。
cm = confusionchart(Y,label);
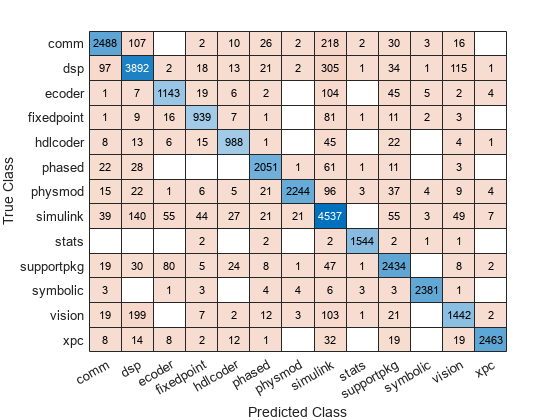
NLP のデータ セットを読み込みます。予測子データを転置します。
load nlpdata
X = X';簡単にするため、'simulink'、'dsp'、'comm' のいずれでもない Y の観測値すべてに対して 'others' というラベルを使用します。
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';SpaRSA を使用して目的関数を最適化するように指定する線形分類モデル テンプレートを作成します。
t = templateLinear('Solver','sparsa');
5 分割の交差検証を使用して、線形分類モデルから構成されている ECOC モデルを交差検証します。予測子の観測値が列に対応することを指定します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'KFold',5,'ObservationsIn','columns'); CMdl1 = CVMdl.Trained{1}
CMdl1 =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [comm dsp simulink others]
ScoreTransform: 'none'
BinaryLearners: {6×1 cell}
CodingMatrix: [4×6 double]
Properties, Methods
CVMdl は ClassificationPartitionedLinearECOC モデルです。このモデルに含まれている Trained プロパティは、各分割の学習セットを使用して学習を行った CompactClassificationECOC モデルが格納されている 5 行 1 列の cell 配列です。
既定の設定では、ECOC モデルを構成する線形分類モデルは SVM を使用します。SVM スコアは観測から判定境界までの符号付き距離です。したがって、定義域は です。以下のようなカスタム バイナリ損失関数を作成します。
各学習器の符号化設計行列 (M) と陽性クラスの分類スコア (s) を各観測値のバイナリ損失にマッピングする
線形損失を使用する
中央値を使用してバイナリ学習器の損失を集計する
バイナリ損失関数用に独立した関数を作成し、MATLAB® パスに保存できます。あるいは、無名バイナリ損失関数を指定できます。
customBL = @(M,s)median(1 - (M.*s),2,'omitnan')/2;交差検証ラベルを予測し、クラスごとのバイナリ損失の中央値を推定します。10 分割外の観測値が無作為なセットの場合、クラスごとに符号を反転したバイナリ損失の中央値を出力します。
[label,NegLoss] = kfoldPredict(CVMdl,'BinaryLoss',customBL); idx = randsample(numel(label),10); table(Y(idx),label(idx),NegLoss(idx,1),NegLoss(idx,2),NegLoss(idx,3),... NegLoss(idx,4),'VariableNames',[{'True'};{'Predicted'};... categories(CVMdl.ClassNames)])
ans=10×6 table
True Predicted comm dsp simulink others
________ _________ _________ ________ ________ _______
others others -1.2319 -1.0488 0.048758 1.6175
simulink simulink -16.407 -12.218 21.531 11.218
dsp dsp -0.7387 -0.11534 -0.88466 -0.2613
others others -0.1251 -0.8749 -0.99766 0.14517
dsp dsp 2.5867 6.4187 -3.5867 -4.4165
others others -0.025358 -1.2287 -0.97464 0.19747
others others -2.6725 -0.56708 -0.51092 2.7453
others others -1.1605 -0.88321 -0.11679 0.43504
others others -1.9511 -1.3175 0.24735 0.95111
simulink others -7.848 -5.8203 4.8203 6.8457
符号が反転した最大損失に基づき、ラベルが予測されます。
線形分類モデルから構成される ECOC モデルは、ロジスティック回帰学習器の場合のみ事後確率を返します。この例では Parallel Computing Toolbox™ と Optimization Toolbox™ が必要です。
NLP のデータ セットを読み込み、カスタム バイナリ損失の指定 で説明されているようにデータを前処理します。
load nlpdata X = X'; Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';
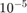 ~
~ 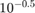 の範囲で対数間隔で配置された 5 個の正則化強度を作成します。
の範囲で対数間隔で配置された 5 個の正則化強度を作成します。
Lambda = logspace(-6,-0.5,5);
線形分類モデル テンプレートを作成します。このテンプレートでは、SpaRSA を使用して目的関数を最適化し、ロジスティック回帰学習器を使用するように指定します。
t = templateLinear('Solver','sparsa','Learner','logistic','Lambda',Lambda);
5 分割の交差検証を使用して、線形分類モデルから構成されている ECOC モデルを交差検証します。予測子の観測値が列に対応することと並列計算の使用を指定します。
rng(1); % For reproducibility Options = statset('UseParallel',true); CVMdl = fitcecoc(X,Y,'Learners',t,'KFold',5,'ObservationsIn','columns',... 'Options',Options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
交差検証事後クラス確率を予測します。並列計算の使用と、二次計画法を使用して事後確率を推定することを指定します。
[label,~,~,Posterior] = kfoldPredict(CVMdl,'Options',Options,... 'PosteriorMethod','qp'); size(label) label(3,4) size(Posterior) Posterior(3,:,4)
ans =
31572 5
ans =
categorical
others
ans =
31572 4 5
ans =
0.0285 0.0373 0.1714 0.7627
5 つの正則化強度があるので、次のようになります。
labelは 31572 行 5 列の categorical 配列になります。label(3,4)は、観測値 3 について予測された交差検証済みラベルであり、正則化強度Lambda(4)により学習をさせたモデルを使用しています。Posteriorは 31572 x 4 x 5 の行列になります。Posterior(3,:,4)は、正則化強度Lambda(4)により学習をさせたモデルを使用して推定された観測値 3 の事後クラス確率すべてのベクトルです。2 番目の次元の順序はCVMdl.ClassNamesに対応します。ランダムな 10 個の事後クラス確率の集合を表示します。
Lambda(4) を使用して学習をさせたモデルについて、交差検証ラベルおよび事後確率の無作為標本を表示します。
idx = randsample(size(label,1),10); table(Y(idx),label(idx,4),Posterior(idx,1,4),Posterior(idx,2,4),... Posterior(idx,3,4),Posterior(idx,4,4),... 'VariableNames',[{'True'};{'Predicted'};categories(CVMdl.ClassNames)])
ans =
10×6 table
True Predicted comm dsp simulink others
________ _________ __________ __________ ________ _________
others others 0.030275 0.022142 0.10416 0.84342
simulink simulink 3.4954e-05 4.2982e-05 0.99832 0.0016016
dsp others 0.15787 0.25718 0.18848 0.39647
others others 0.094177 0.062712 0.12921 0.71391
dsp dsp 0.0057979 0.89703 0.015098 0.082072
others others 0.086084 0.054836 0.086165 0.77292
others others 0.0062338 0.0060492 0.023816 0.9639
others others 0.06543 0.075097 0.17136 0.68812
others others 0.051843 0.025566 0.13299 0.7896
simulink simulink 0.00044059 0.00049753 0.70958 0.28948