kfoldPredict
交差検証済みカーネル ECOC モデルの観測値の分類
構文
説明
label = kfoldPredict(CVMdl)ClassificationPartitionedKernelECOC) CVMdl によって予測されたクラス ラベルを返します。kfoldPredict は、すべての分割について、学習分割観測値に対して学習をさせたモデルを使用して、検証分割観測値のクラス ラベルを予測します。kfoldPredict は、CVMdl の作成に使用されたものと同じデータを適用します (fitcecoc を参照)。
符号を反転した最大の平均バイナリ損失 (つまり、最小の平均バイナリ損失と等しい) の発生するクラスに観測を割り当てることで、観測の分類が予測されます。
label = kfoldPredict(CVMdl,Name,Value)
例
交差検証済みマルチクラス カーネル ECOC 分類器を使用して観測値を分類し、生成された分類の混同行列を表示します。
フィッシャーのアヤメのデータ セットを読み込みます。X には花の測定値が、Y には花の種類の名前が格納されています。
load fisheriris
X = meas;
Y = species;カーネル バイナリ学習器から構成される ECOC モデルを交差検証します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners','kernel','CrossVal','on')
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl は ClassificationPartitionedKernelECOC モデルです。既定では、10 分割交差検証が実行されます。異なる分割数を指定するには、'Crossval' ではなく名前と値のペアの引数 'KFold' を指定します。
分割の学習で fitcecoc が使用しない観測値を分類します。
label = kfoldPredict(CVMdl);
混同行列を作成して、観測値の真のクラスを予測されたラベルと比較します。
C = confusionchart(Y,label);
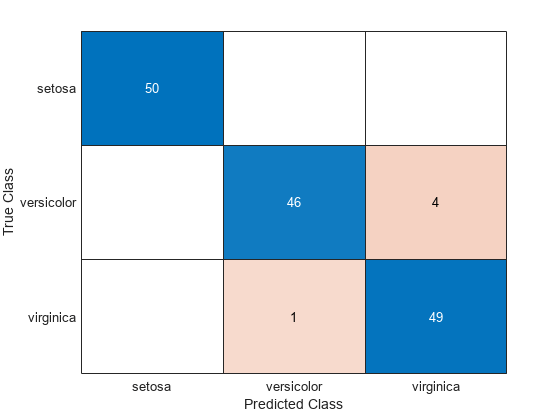
CVMdl モデルは、4 つの 'versicolor' 種のアヤメを 'virginica' 種のアヤメとして誤分類し、1 つの 'virginica' 種のアヤメを 'versicolor' 種のアヤメとして誤分類します。
フィッシャーのアヤメのデータ セットを読み込みます。X には花の測定値が、Y には花の種類の名前が格納されています。
load fisheriris
X = meas;
Y = species;5 分割の交差検証を使用して、カーネル分類モデルから構成される ECOC モデルを交差検証します。
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners','kernel','KFold',5)
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 5
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl は ClassificationPartitionedKernelECOC モデルです。これには、5 行 1 列の CompactClassificationECOC モデルの cell 配列である Trained プロパティが含まれています。
既定では、CompactClassificationECOC モデルを構成するカーネル分類モデルは SVM を使用します。SVM スコアは観測から判定境界までの符号付き距離です。したがって、定義域は です。以下のようなカスタム バイナリ損失関数を作成します。
各学習器の符号化設計行列 (M) と陽性クラスの分類スコア (s) を各観測値のバイナリ損失にマッピングする
線形損失を使用する
中央値を使用して、バイナリ学習器損失を集計します。
バイナリ損失関数用に独立した関数を作成し、MATLAB® パスに保存できます。あるいは、無名バイナリ損失関数を指定できます。この場合、無名バイナリ損失関数に対する関数ハンドル (customBL) を作成します。
customBL = @(M,s)median(1 - (M.*s),2,'omitnan')/2;交差検証ラベルを予測し、クラスごとのバイナリ損失の中央値を推定します。10 件の観測の無作為セットについて、クラスごとに中央値の符号を反転したバイナリ損失を出力します。
[label,NegLoss] = kfoldPredict(CVMdl,'BinaryLoss',customBL); idx = randsample(numel(label),10); table(Y(idx),label(idx),NegLoss(idx,1),NegLoss(idx,2),NegLoss(idx,3),... 'VariableNames',[{'True'};{'Predicted'};... unique(CVMdl.ClassNames)])
ans=10×5 table
True Predicted setosa versicolor virginica
______________ ______________ ________ __________ _________
{'setosa' } {'setosa' } 0.20926 -0.84572 -0.86354
{'setosa' } {'setosa' } 0.16144 -0.90572 -0.75572
{'virginica' } {'versicolor'} -0.83532 -0.12157 -0.54311
{'virginica' } {'virginica' } -0.97235 -0.69759 0.16994
{'virginica' } {'virginica' } -0.89441 -0.69937 0.093778
{'virginica' } {'virginica' } -0.86774 -0.47297 -0.15929
{'setosa' } {'setosa' } -0.1026 -0.69671 -0.70069
{'setosa' } {'setosa' } 0.1001 -0.89163 -0.70848
{'virginica' } {'virginica' } -1.0106 -0.52919 0.039829
{'versicolor'} {'versicolor'} -1.0298 0.027354 -0.49757
交差検証済みモデルは、10 個のランダムな観測値のうち 9 個のラベルを正しく予測します。
交差検証済みマルチクラス カーネル ECOC 分類モデルを使用して、事後クラス確率を推定します。カーネル分類モデルは、ロジスティック回帰学習器の場合のみ事後確率を返します。
フィッシャーのアヤメのデータ セットを読み込みます。X には花の測定値が、Y には花の種類の名前が格納されています。
load fisheriris
X = meas;
Y = species;バイナリ カーネル分類モデルのカーネル テンプレートを作成します。ロジスティック回帰学習器を当てはめるよう指定します。
t = templateKernel('Learner','logistic')
t =
Fit template for classification Kernel.
BetaTolerance: []
BlockSize: []
BoxConstraint: []
Epsilon: []
NumExpansionDimensions: []
GradientTolerance: []
HessianHistorySize: []
IterationLimit: []
KernelScale: []
Lambda: []
Learner: 'logistic'
LossFunction: []
Stream: []
VerbosityLevel: []
StandardizeData: []
Version: 1
Method: 'Kernel'
Type: 'classification'
t はカーネル テンプレートです。ほとんどのプロパティは空です。テンプレートを使用して ECOC 分類器に学習をさせると、該当するプロパティが既定値に設定されます。
カーネル テンプレートを使用して、ECOC モデルを交差検証します。
rng('default'); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'CrossVal','on')
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl は ClassificationPartitionedECOC モデルです。既定では、10 分割交差検証が使用されます。
検証分割のクラス事後確率を予測します。
[label,~,~,Posterior] = kfoldPredict(CVMdl);
バイナリ損失の平均が最小となるクラスに観測が割り当てられます。すべてのバイナリ学習器が事後確率を計算しているので、バイナリ損失関数は quadratic になります。
無作為に選択した 10 個の観測値について事後確率を表示します。
idx = randsample(size(X,1),10); CVMdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
table(Y(idx),label(idx),Posterior(idx,:),... 'VariableNames',{'TrueLabel','PredLabel','Posterior'})
ans=10×3 table
TrueLabel PredLabel Posterior
______________ ______________ ________________________________
{'setosa' } {'setosa' } 0.68216 0.18546 0.13238
{'virginica' } {'virginica' } 0.1581 0.14405 0.69785
{'virginica' } {'virginica' } 0.071807 0.093291 0.8349
{'setosa' } {'setosa' } 0.74918 0.11434 0.13648
{'versicolor'} {'versicolor'} 0.09375 0.67149 0.23476
{'versicolor'} {'versicolor'} 0.036202 0.85544 0.10836
{'versicolor'} {'versicolor'} 0.2252 0.50473 0.27007
{'virginica' } {'virginica' } 0.061562 0.11086 0.82758
{'setosa' } {'setosa' } 0.42448 0.21181 0.36371
{'virginica' } {'virginica' } 0.082705 0.1428 0.7745
Posterior の列は CVMdl.ClassNames のクラスの順序に対応します。