このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
線形代数
MATLAB 環境の行列
このトピックでは、MATLAB® で行列を作成し、基本的な行列演算を行う方法を紹介します。
MATLAB 環境では、"行列" という用語を使って、2 次元グリッドに配置された実数または複素数を含む変数を示します。"配列" とは一般的に数値のベクトル、行列または高次元グリッドです。MATLAB のすべての配列は四角形になり、すべての次元の成分は同じ長さになります。行列で定義される数学演算は、線形代数で取り扱う内容です。
行列の作成
MATLAB には、さまざまな行列を作成する関数が多数用意されています。たとえば、パスカルの三角形に基づくエントリを含んだ対称行列を作成することができます。
A = pascal(3)
A =
1 1 1
1 2 3
1 3 6
または、行方向と列方向の和が等しい非対称の "魔方陣行列" を作成することもできます。
B = magic(3)
B =
8 1 6
3 5 7
4 9 2
もう 1 つの例は、ランダムな整数からなる 3 行 2 列の方形行列です。ここでは、randi への最初の入力が整数値の取り得る範囲を示し、次の 2 つの入力が行と列の数を示します。
C = randi(10,3,2)
C =
9 10
10 7
2 1列ベクトルは m 行 1 列の行列、行ベクトル は 1 行 n 列の行列、スカラー は 1 行 1 列の行列です。行列を手動で定義するには、大かっこ [ ] を使用して配列の先頭と末尾を示します。大かっこ内で行末を示すには、セミコロン ; を使用します。スカラー (1 行 1 列の行列) の場合、大かっこは不要です。たとえば、以下のステートメントは列ベクトル、行ベクトル、およびスカラーを生成します。
u = [3; 1; 4] v = [2 0 -1] s = 7
u =
3
1
4
v =
2 0 -1
s =
7
行列の作成と取り扱い方法の詳細は、行列の作成、連結、および拡張を参照してください。
行列の加算と減算
行列と配列の加算および減算は要素ごとに、すなわち "要素単位" で実行されます。たとえば、A を B に加算し、その結果から A を減算すると B に戻ります。
X = A + B
X =
9 2 7
4 7 10
5 12 8Y = X - A
Y =
8 1 6
3 5 7
4 9 2加算と減算では、両方の行列の次元に互換性がなければなりません。次元に整合性がない場合はエラーになります。
X = A + C
Error using + Matrix dimensions must agree.
詳細については、配列と行列の演算を参照してください。
ベクトル積と転置
同じ長さの行ベクトルと列ベクトルの乗算は、順番を変えても計算結果は同じになります。結果は、"内積" と呼ばれるスカラーか、"外積" と呼ばれる行列のいずれかになります。
u = [3; 1; 4]; v = [2 0 -1]; x = v*u
x =
2X = u*v
X =
6 0 -3
2 0 -1
8 0 -4実数行列の "転置" 演算では、aij と aji を交換します。複素数行列の場合、もう 1 つの考慮事項は、配列内の複素数エントリの複素共役から "複素共役転置" を形成するかどうかです。MATLAB はアポストロフィ演算子 (') を使用して複素共役転置を行い、ドットアポストロフィ演算子 (.') を使用して共役なしの転置を行います。すべての要素が実数の行列では、これら 2 つの演算子の処理は同じになります。
例の行列 A = pascal(3) は "対称" であるため、A' は A と等しくなります。しかし、B = magic(3) は対称でないため、B' の各要素は主対角に対し鏡像の位置になります。
B = magic(3)
B =
8 1 6
3 5 7
4 9 2X = B'
X =
8 3 4
1 5 9
6 7 2ベクトルの場合、転置によって行ベクトルは列ベクトル (またはその逆) になります。
x = v'
x =
2
0
-1x と y が共に実数の列ベクトルの場合、積 x*y は定義されません。ただし、次の 2 つの積、
x'*y
と
y'*x
は同じスカラーの結果を生成します。これらは使用頻度が高く、"内" 積、"スカラー" 積、"ドット" 積と呼ばれています。dot という名前の、ドット積専用の関数も用意されています。
複素数ベクトルや行列 z に対して、z' は複素共役転置を表します。すなわち、各要素の虚数部の符号が逆になります。たとえば、次の複素行列を考えます。
z = [1+2i 7-3i 3+4i; 6-2i 9i 4+7i]
z = 1.0000 + 2.0000i 7.0000 - 3.0000i 3.0000 + 4.0000i 6.0000 - 2.0000i 0.0000 + 9.0000i 4.0000 + 7.0000i
z の複素共役転置は次のようになります。
z'
ans = 1.0000 - 2.0000i 6.0000 + 2.0000i 7.0000 + 3.0000i 0.0000 - 9.0000i 3.0000 - 4.0000i 4.0000 - 7.0000i
各要素の虚数部がその符号を保持し、共役を取らない複素転置は z.' で定義します。
z.'
ans = 1.0000 + 2.0000i 6.0000 - 2.0000i 7.0000 - 3.0000i 0.0000 + 9.0000i 3.0000 + 4.0000i 4.0000 + 7.0000i
複素ベクトルに対して 2 つのスカラー積 x'*y と y'*x は互いに複素共役で、スカラー積 x'*x は実数です。
行列の乗算
行列の乗算は、線形変換の構成を反映するように定義されており、線形方程式を簡潔に表現できます。行列積 C = AB は、A の列の次元が B の行の次元と等しいとき、またはどちらかがスカラーの場合に定義されます。A が m 行 p 列で、B が p 行n 列の行列の場合、積 C は m 行 n 列の行列になります。積は、実際には MATLAB の for ループ、colon 表記、ベクトルのドット積を使って定義できます。
A = pascal(3); B = magic(3); m = 3; n = 3; for i = 1:m for j = 1:n C(i,j) = A(i,:)*B(:,j); end end
MATLAB では、C = A*B のように、アスタリスクを使って行列の乗算を示します。行列の乗算は可換的ではありません。つまり、通常において A*B は B*A と等価ではありません。
X = A*B
X =
15 15 15
26 38 26
41 70 39Y = B*A
Y =
15 28 47
15 34 60
15 28 43行列は、列ベクトルを右から、行ベクトルを左から乗算します。
u = [3; 1; 4]; x = A*u
x =
8
17
30v = [2 0 -1]; y = v*B
y =
12 -7 10方形行列の乗算では、次元を一致させる必要があります。A は 3 行 3 列で、C は 3 行 2 列のため、両者を乗算して 3 行 2 列の結果が得られます (共通の内部次元が相殺されます)。
X = A*C
X =
24 17
47 42
79 77ただし、乗算は逆の順序では実行できません。
Y = C*A
Error using * Incorrect dimensions for matrix multiplication. Check that the number of columns in the first matrix matches the number of rows in the second matrix. To perform elementwise multiplication, use '.*'.
あらゆるものをスカラーで乗算できます。
s = 10; w = s*y
w = 120 -70 100
配列をスカラーで乗算する場合、スカラーは暗黙的にもう一方の入力と同じサイズに拡張されます。これはしばしば "スカラー拡張" と呼ばれます。
単位行列
一般的な数学表記では、大文字の I で単位行列を表します。単位行列は対角要素が 1 で、他の要素が 0 である任意のサイズの行列です。この行列の次元が一致する場合、AI = A かつ IA = A になります。
MATLAB の以前のバージョンでは大文字と小文字を区別して認識していなかったため、単位行列に I を使用できませんでした。これは i を既に添字や複素数単位として使用していたためです。そこで、英語の語呂合わせで関数名を作成しました。関数
eye(m,n)
は m 行 n 列の方形の単位行列を返し、eye(n) は n 行 n 列の正方の単位行列を返します。
逆行列
行列 A が正方行列で特異ではない (非ゼロの行列式の) 場合、方程式 AX = I と XA = I は同じ解 X をもちます。この解は、A の "逆数" と呼ばれ、A-1 として表されます。関数 inv と式 A^-1 は両方とも逆行列を計算します。
A = pascal(3)
A =
1 1 1
1 2 3
1 3 6X = inv(A)
X =
3.0000 -3.0000 1.0000
-3.0000 5.0000 -2.0000
1.0000 -2.0000 1.0000A*X
ans =
1.0000 0 0
0.0000 1.0000 -0.0000
-0.0000 0.0000 1.0000det で計算される "行列式" は、行列で記述される線形変換のスケーリング ファクターの尺度となります。行列式が正確にゼロの場合、行列は "特異行列" で逆行列は存在しません。
d = det(A)
d =
1一部の行列は "近特異行列" で、逆行列が存在するにもかかわらず、計算は数値誤差の影響を受けます。関数 cond は、逆行列から得られる結果の精度がわかる "逆行列計算の条件数" を計算します。条件数の範囲は、数値的に安定した行列の 1 から特異行列の Inf までです。
c = cond(A)
c = 61.9839
行列の明示的な逆行列を求める必要はあまりありません。関数 inv は、線形方程式系 Ax = b を解くときにしばしば誤用されます。実行時間と数値精度の両面でこの方程式を解く一番優れた方法は、行列バックスラッシュ演算子を x = A\b のように使用することです。詳細については、mldivide を参照してください。
クロネッカー テンソル積
2 つの行列のクロネッカー積 kron(X,Y) は、X と Y の要素のすべての組み合わせの積で作成される大規模な行列です。X が m 行 n 列で、Y が p 行q 列の場合、kron(X,Y) は mp 行 nq 列の行列になります。要素は、X の各要素が行列 Y 全体で乗算されるように配置されます。
[X(1,1)*Y X(1,2)*Y . . . X(1,n)*Y
. . .
X(m,1)*Y X(m,2)*Y . . . X(m,n)*Y]クロネッカー積は 0 と 1 からなる行列を使って、繰り返し小さな行列のコピーを作成します。たとえば X が 2 行 2 列の行列であるとき、
X = [1 2
3 4]また、I = eye(2,2) が 2 行 2 列の単位行列であるとき、
kron(X,I)
ans =
1 0 2 0
0 1 0 2
3 0 4 0
0 3 0 4と
kron(I,X)
ans =
1 2 0 0
3 4 0 0
0 0 1 2
0 0 3 4kron の他に、配列の複製に役立つ関数としては repmat、repelem、および blkdiag などがあります。
ベクトルと行列のノルム
ベクトル x の p ノルムは次のように定義され、
norm(x,p) で計算されます。この演算は、p > 1 を満たす任意の値に対して定義されますが、最も広く使われる p の値は 1、2、および ∞ です。既定値は p = 2 で、"ユークリッド長" や "ベクトル振幅" に対応します。
v = [2 0 -1]; [norm(v,1) norm(v) norm(v,inf)]
ans =
3.0000 2.2361 2.0000行列 A の p ノルム
は p = 1, 2, ∞ に対して norm(A,p) で計算されます。ここでも既定値は p = 2 です。
A = pascal(3); [norm(A,1) norm(A) norm(A,inf)]
ans = 10.0000 7.8730 10.0000
行列の各行または各列のノルムを計算する場合は、vecnorm を使用できます。
vecnorm(A)
ans =
1.7321 3.7417 6.7823線形代数関数のマルチスレッド計算
MATLAB は多数の線形代数関数と要素ごとに計算する数値関数のマルチスレッド計算をサポートしています。これらの関数は自動的にマルチスレッドで実行されます。関数や式に対し、複数の CPU を使用して計算を高速化するにはさまざまな条件があります。
関数は同時実行可能な部分へ簡単に分割できる処理を実行します。この分割部分は各処理間で通信をほとんど行わずに実行されるものでなければなりません。すなわちシーケンシャルな処理がほとんどないものを扱います。
データを分割し、複数の実行スレッドを管理する時間を含めても同時実行する価値があるように、データ サイズは十分に大きいものを扱います。たとえば配列が数千個以上の要素を含む場合は、ほとんどの関数に対して高速化の効果があります。
処理がメモリに拘束されないものを扱います。すなわち処理時間の大部分がメモリのアクセス時間にならないものを扱います。一般的には、シンプルな処理より複雑な処理をする関数の方が、高速化の効果があります。
行列の乗算 (X*Y) と行列のべき乗 (X^p) の処理は、大規模な倍精度配列 (10,000 個以上の要素) に対して計算負荷を増大させます。行列解析関数 det、rcond、hess、expm も同様です。
関連するトピック
外部の Web サイト
線形方程式
計算上の考慮事項
技術計算の中で最も重要な問題の 1 つは、線形方程式を解くことです。
行列表記では一般的な問題は次のような形式になります。[2 つの行列 A と b があるとき、Ax= b または xA= b の条件のいずれかを満たす一意の行列 x は存在しますか。]
1 行 1 列の簡単な例を考えます。たとえば次の方程式について考えます。
7x = 21
上記に一意の解は存在しますか。
もちろん存在します。この方程式には一意の解 x = 3 が存在します。解は除算から簡単に得られます。
x = 21/7 = 3
解を求める場合、7 の逆数すなわち 7-1 = 0.142857... を計算し、この 7-1 に 21 を乗算する方法は通常 "使いません"。この方法では余計な計算ステップが必要となり、7-1 を有限小数値で表すと精度が低くなります。複数の未知数がある線形方程式にも同様の考え方で、MATLAB は逆行列を使わずにこのような方程式を解きます。
標準の数学的な表記ではありませんが、MATLAB ではスカラーの場合と同じ除算記号を使用して一般的な連立方程式の解を記述します。2 つの除算記号 "スラッシュ" (/) および "バックスラッシュ" (\) が 2 つの MATLAB 関数 mrdivide および mldivide に対応します。これらの演算子は、係数行列の左右どちらかが未知の行列となる 2 つの状況で使用されます。
|
|
|
|
Ax = b または xA = b の方程式の両辺を A で割ると考えます。係数行列 A は常に「分母」 になります。
x = A\b に対する次元の整合性の条件は、2 つの行列 A と b の行数が同じであることです。その結果、解 x は b と同じ列数になり、行数は A の列数と同じになります。x = b/A に対しては、行と列の処理が反転します。
実際には Ax = b の形式の線形方程式の方が xA = b の形式より頻繁に使用されます。そのためバックスラッシュはスラッシュよりも頻繁に使用されます。この節の以降ではバックスラッシュ演算子を中心に説明します。スラッシュ演算子の特性は次の等式から推定できます。
(b/A)' = (A'\b').
係数行列 A は正方である必要はありません。A のサイズが m 行 n 列である場合、次の 3 つのケースがあります。
m = n | 正方システム。厳密解が得られます。 |
m > n | 未知数より方程式が多い過決定システム。最小二乗解を求めます。 |
m < n | 未知数より方程式が少ない劣決定システム。最大で m 個のゼロでない構成要素をもつ基本解を求めます。 |
mldivide アルゴリズム. mldivide 演算子は、さまざまなソルバーを使って各種の係数行列を処理します。実行するアルゴリズムは係数行列を調べて自動的に決められます。詳細については、関数 mldivide のリファレンス ページの「アルゴリズム」の節を参照してください。
一般解
線形方程式系 Ax = b の一般解は、すべての解を示します。次のようにして一般解を求めることができます。
対応する同次方程式 Ax = 0 を解きます。
nullコマンドを使用して「null(A)」と入力します。これによって、Ax = 0 の解空間の基底が返されます。どの解も基底ベクトルの線形結合になります。非同次方程式 Ax = b の特殊解を導出します。
Ax= b の解はすべて、手順 2 の Ax =b の特殊解に手順 1 の基底ベクトルの線形結合を加えたものとして表現できます。
この節の以降では、MATLAB を使用して手順 2 の Ax = b の特殊解を導出する方法を説明します。
正方システム
一般的な例は、正方係数行列 A と右辺に単一の列ベクトル b がある場合です。
特異でない係数行列. 行列 A が特異でない場合、x = A\b の解は b と同じサイズになります。以下に例を示します。
A = pascal(3);
u = [3; 1; 4];
x = A\u
x =
10
-12
5A*x が u と等価であることを確認してください。
A と b が正方で同じサイズの場合、x= A\b も同じサイズになります。
b = magic(3);
X = A\b
X =
19 -3 -1
-17 4 13
6 0 -6A*x が b と等価であることを確認してください。
上記 2 つの例は、厳密に整数の解になります。これは係数行列がフル ランク行列 (特異でない) の pascal(3) であるためです。
特異な係数行列. 正方行列 A が線形に独立した列をもっていない場合を「特異」といいます。A が特異な場合、Ax = b の解は存在しないかまたは一意ではありません。バックスラッシュ演算 A\b は、A が特異に近い場合か、厳密な特異性が検出された場合に警告を発します。
A が特異で Ax = b が解をもつ場合は、次のように入力することで一意ではない特殊解を導出できます。
P = pinv(A)*b
pinv(A) は A の疑似逆行列です。Ax = b が厳密解をもたない場合、pinv(A) は最小二乗解を返します。
以下に例を示します。
A = [ 1 3 7
-1 4 4
1 10 18 ]が特異であることは以下のように入力することでわかります。
rank(A)
ans =
2A はフル ランクではないため、いくつかの特異値がゼロに等しくなります。
厳密解。b =[5;2;12] に対して、方程式 Ax = b は次のような厳密解をもちます。
pinv(A)*b
ans =
0.3850
-0.1103
0.7066以下のように入力すると、pinv(A)*b が厳密解であることを確かめることができます。
A*pinv(A)*b
ans =
5.0000
2.0000
12.0000最小二乗解。ただし、b = [3;6;0] の場合、Ax = b は厳密解をもちません。この例の場合、pinv(A)*b は最小二乗解を返します。以下のように入力すると、
A*pinv(A)*b
ans =
-1.0000
4.0000
2.0000元のベクトル b には戻りません。
Ax = b が厳密解をもつかどうかは、拡大行列 [A b] を行の階段型に変換することによって判定できます。例では以下のようになります。
rref([A b])
ans =
1.0000 0 2.2857 0
0 1.0000 1.5714 0
0 0 0 1.0000最終行は最後の要素以外はすべてゼロであるため、方程式は解をもちません。この例の場合、pinv(A) は最小二乗解を返します。
過決定システム
この例では、実験データでのさまざまな曲線近似において過決定システムが頻繁に発生することを説明します。
量 y は、時間 t のいくつかの異なる値で測定され、次の観測値を生成します。次のステートメントで、データを入力して table 内に表示できます。
t = [0 .3 .8 1.1 1.6 2.3]'; y = [.82 .72 .63 .60 .55 .50]'; B = table(t,y)
B=6×2 table
t y
___ ____
0 0.82
0.3 0.72
0.8 0.63
1.1 0.6
1.6 0.55
2.3 0.5
減衰指数関数を使用してデータのモデル化を試します。
.
上記の式は、ベクトル y が他の 2 つのベクトルの線形結合で近似されることを示しています。一方はすべて 1 の定数ベクトルであり、もう一方は成分 exp(-t) を含むベクトルです。未知の係数 および は、モデルのデータの偏差の二乗和を最小化する最小二乗近似を実行することで計算可能です。2 つの未知数に対し 6 つの方程式があり、6 行 2 列の行列で表されます。
E = [ones(size(t)) exp(-t)]
E = 6×2
1.0000 1.0000
1.0000 0.7408
1.0000 0.4493
1.0000 0.3329
1.0000 0.2019
1.0000 0.1003
最小二乗解を求めるには、バックスラッシュ演算子を使用します。
c = E\y
c = 2×1
0.4760
0.3413
つまり、データの最小二乗近似は次のようになります。
次のステートメントでは、t を等間隔にインクリメントしてモデルを評価し、結果を元のデータとともにプロットします。
T = (0:0.1:2.5)'; Y = [ones(size(T)) exp(-T)]*c; plot(T,Y,'-',t,y,'o')
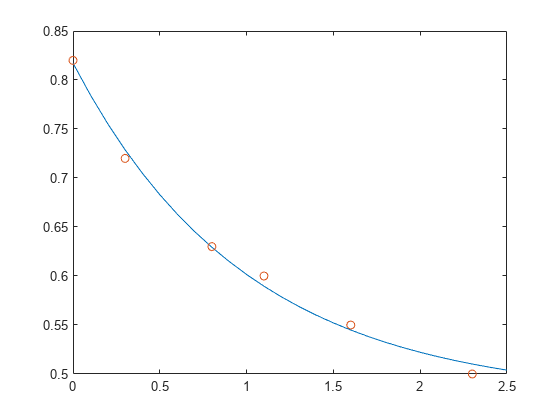
E*c は y と完全に等しくはありませんが、その差は元のデータの測定誤差より小さくなっている可能性があります。
方形行列 A は、線形独立の列がない場合はランク落ちとなります。A がランク落ちの場合、AX = B の最小二乗解は一意ではありません。A\B は A がランク落ちであり、最小二乗解を生成する場合に警告を発します。lsqminnorm を使用して、すべての解の中で最小のノルムをもつ解 X を求めることができます。
劣決定システム
この例では、劣決定システムの解が一意にならない理由について説明します。劣決定の線形システムは方程式より未知数の数が多くなります。MATLAB の行列の左除算演算で基底最小二乗解を求めます。つまり、m 行 n 列の係数行列には、最大 m 個の非ゼロの成分があります。
ここでは小さな乱数の例をあげます。
R = [6 8 7 3; 3 5 4 1] rng(0); b = randi(8,2,1)
R =
6 8 7 3
3 5 4 1
b =
7
8 線形システム Rp = b には、4 つの未知数の中に 2 つの式があります。この係数行列に含まれる整数は小さいため、format コマンドを使用して有理数形式の解を表示するのが適切です。特殊解は次のステートメントで得られます。
format rat
p = R\b
p =
0
17/7
0
-29/7 R(:,2) は R の最大ノルムをもつ列であるため、ゼロ以外の要素の 1 つは p(2) になります。R(:,2) を取り除くと R(:,4) が最大ノルムをもつため、他のゼロ以外の要素は p(4) になります。
劣決定システムの完全な一般解は、ヌル空間ベクトルの任意の線形結合に p を付加することで特性化され、有理数で表示するオプションにより関数 null を使用して求められます。
Z = null(R,'r')
Z =
-1/2 -7/6
-1/2 1/2
1 0
0 1 R*Z がゼロになります。残差 R*x - b は、以下に示す任意のベクトル x の場合は小さくなります。
x = p + Z*q
Z の列はヌル空間ベクトルであるため、積 Z*q はこれらのベクトルの線形結合です。
説明のため、任意の q を選択し、x を作成します。
q = [-2; 1]; x = p + Z*q;
残差のノルムを計算します。
format short
norm(R*x - b)ans = 2.6645e-15
解を無限に利用できる場合、最小ノルムをもつ解が特に重要となります。lsqminnorm を使用して最小ノルムをもつ最小二乗解を計算することができます。この解は norm(p) に対する可能な最小値をもちます。
p = lsqminnorm(R,b)
p =
-207/137
365/137
79/137
-424/137 複数の右辺の解法
同一の係数行列 A をもつが、異なる右辺 b をもつ線形システムを解く問題もあります。b の異なる値が同時に使用できる場合は、b を複数の列をもつ行列として構成し、単一のバックスラッシュ コマンドを使用して X = A\[b1 b2 b3 …] のように方程式系全体を一度に解くことができます。
ただし、b の異なる値がすべて同時に使用できない場合は、いくつかの方程式系を連続して解かなくてはなりません。これらの方程式系のいずれかをスラッシュ (/) またはバックスラッシュ (\) を使用して解く場合、演算子は係数行列 A を因数分解し、この行列の分解を使用して解を計算します。ただし、異なる b をもつ類似の方程式系を連続して解く場合、演算子は毎回同じ A の分解を演算するため冗長演算となります。
この問題を解決するには、A の分解を事前計算してから、その因子を再利用して異なる b の値の解を求めます。しかし実際には、この方法で分解を事前に計算することは困難です。その理由は、問題を解決するためにどの分解 (LU、LDL、コレスキーなど) を計算するかだけでなく、因子をどのように乗算するかについても知る必要があるからです。たとえば、LU 分解では、元のシステム Ax = b を解くために次の 2 つの線形システムを解かなければなりません。
[L,U] = lu(A); x = U \ (L \ b);
代わりに、連続する複数の右辺をもつ線形システムを解くために推奨される方法は、decomposition オブジェクトを使用する方法です。これらのオブジェクトによって、行列分解の事前計算によるパフォーマンス上の利点を活用できます。それらに、行列分解の使用方法に関する知識は必要 "ありません"。前述の LU 分解を以下のように置き換えることができます。
dA = decomposition(A,'lu');
x = dA\b;どの分解を使用すればよいかわからない場合は、decomposition(A) によりバックスラッシュと同様に A のプロパティに基づいて正しいタイプを選択します。
この方法によるパフォーマンス上の利点を測定する簡単なテストを次に示します。このテストでは、バックスラッシュ (\) と decomposition の両方を使用して、同じスパース線形システムの解決を 100 回繰り返します。
n = 1e3; A = sprand(n,n,0.2) + speye(n); b = ones(n,1); % Backslash solution tic for k = 1:100 x = A\b; end toc
Elapsed time is 9.006156 seconds.
% decomposition solution tic dA = decomposition(A); for k = 1:100 x = dA\b; end toc
Elapsed time is 0.374347 seconds.
この問題では、decomposition を使用した方法がバックスラッシュのみを使用した方法に比べてはるかに高速ですが、構文はシンプルです。
反復法
係数行列 A が大規模でスパース性がある場合、分解する方法は一般に効果がありません。反復法は近似解を生成できます。MATLAB は大規模でスパース性のある行列を扱う、いくつかの反復法を用意しています。
マルチスレッド計算
MATLAB は多数の線形代数関数と要素ごとに計算する数値関数のマルチスレッド計算をサポートしています。これらの関数は自動的にマルチスレッドで実行されます。関数や式に対し、複数の CPU を使用して計算を高速化するにはさまざまな条件があります。
関数は同時実行可能な部分へ簡単に分割できる処理を実行します。この分割部分は各処理間で通信をほとんど行わずに実行されるものでなければなりません。すなわちシーケンシャルな処理がほとんどないものを扱います。
データを分割し、複数の実行スレッドを管理する時間を含めても同時実行する価値があるように、データ サイズは十分に大きいものを扱います。たとえば配列が数千個以上の要素を含む場合は、ほとんどの関数に対して高速化の効果があります。
処理がメモリに拘束されないものを扱います。すなわち処理時間の大部分がメモリのアクセス時間にならないものを扱います。一般的には、シンプルな処理より複雑な処理をする関数の方が、高速化の効果があります。
関数 inv、lscov、linsolve、mldivide はマルチスレッド計算を有効にすると、大規模な倍精度配列 (10,000 個以上の要素) に対する計算速度が大幅に上昇します。
参考
mldivide | mrdivide | pinv | decomposition | lsqminnorm
関連するトピック
外部の Web サイト
分解
はじめに
この節で説明する 3 つの行列分解では、対角要素の上部または下部の要素がすべてゼロである "三角" 行列を使います。三角行列を含む線形方程式は、"前進代入" または "後退代入" のいずれかを使うと、簡単かつ高速に解くことができます。
コレスキー分解
コレスキー分解は、対称行列を三角行列と転置行列との積として表現します。
A = R′R
ここで、R は上三角行列です。
対称行列すべてがこの方法で分解できるわけではなく、このような分解をもつ行列は正定値と考えられます。これは、A の対角要素がすべて正で、非対角要素が「大きすぎない」ことを意味しています。パスカル行列を例に行列分解を行います。この章全体を通して行列の例 A は 3 行 3 列のパスカル行列を扱いますが、ここでは一時的に 6 行 6 列の行列を作成します。
A = pascal(6)
A =
1 1 1 1 1 1
1 2 3 4 5 6
1 3 6 10 15 21
1 4 10 20 35 56
1 5 15 35 70 126
1 6 21 56 126 252A の要素は二項係数になります。各要素は上と左の要素の和になります。コレスキー分解は次のようになります。
R = chol(A)
R =
1 1 1 1 1 1
0 1 2 3 4 5
0 0 1 3 6 10
0 0 0 1 4 10
0 0 0 0 1 5
0 0 0 0 0 1結果の要素は再び二項係数になります。R'*R が A に等しいということは、A が二項係数の積の和を含んでいることを示しています。
メモ
コレスキー分解は複素数行列にも適用できます。コレスキー分解を行った複素数行列は
A′ = A
コレスキー分解を使用すると、次の線形方程式
Ax = b
を次の式で置き換えることができます。
R′Rx = b
バックスラッシュ演算子は三角行列を認識するため、MATLAB 環境で次のようにすばやく解くことができます。
x = R\(R'\b)
A が n 行 n 列の行列の場合、chol(A) の計算量は O(n3) になりますが、バックスラッシュの計算量は O(n2) です。
LU 分解
LU 分解またはガウスの消去法は任意の正方行列 A を、下三角行列と上三角行列の置換行列の積として表します。
A = LU,
ここで L は対角要素に 1 をもつ下三角行列を並べ替えたもので、U は上三角行列を並べ替えたものです。
並べ替えは理論上および計算上の面で必要になります。行列
は行を並べ替えないと、三角行列の積として表現することはできません。ただし、行列は次のようになります。
は三角行列の積として表すことができます。ε が小さい場合、因子の要素は大きくなり誤差も大きくなります。よってこの並べ替えは厳密には必要ありませんが、推奨されます。部分ピボットは L の要素の大きさを 1 以下に制限し、U の要素が A の要素より大きくならないようにします。
以下に例を示します。
[L,U] = lu(B)
L =
1.0000 0 0
0.3750 0.5441 1.0000
0.5000 1.0000 0
U =
8.0000 1.0000 6.0000
0 8.5000 -1.0000
0 0 5.2941A を LU 分解すると、線形方程式
A*x = b
は次の式で高速に解くことができます。
x = U\(L\b)
行列式と逆行列は、次の関係を使って LU 分解から計算されます。
det(A) = det(L)*det(U)
と
inv(A) = inv(U)*inv(L)
det(A) = prod(diag(U)) を使用して行列式を計算することもできますが、行列式の符号が逆になる場合があります。
QR 分解
"直交" 行列または直交性の列がある行列とは、各列が単位長さをもち相互に直交関係になる実数行列です。Q が直交であれば、
QTQ = I
ここで、I は単位行列です。
最も簡単な直交行列は 2 次元の座標回転変換です。
複素数行列に対応する概念は "ユニタリ" です。直交ユニタリ行列は長さと角度が保存され誤差が大きくならないため、数値計算に効果的です。
直交分解または QR 分解は任意の方形行列を、直交行列またはユニタリ行列と上三角行列の積で表現します。列の置換も含まれます。
A = QR
または
AP = QR,
ここで、Q は直交行列またはユニタリ行列、R は上三角行列、P は置換行列です。
QR 分解には、フル サイズとエコノミー サイズ、列置換をもつものともたないものの 4 種類あります。
過決定線形システムは、列よりも多くの行をもつ方形行列を含んでいます。すなわち、m 行 n 列で m > n です。フル サイズの QR 分解は、m 行 m 列の正方直交行列 Q と m 行 n 列の上三角行列 R を生成します。
C=gallery('uniformdata',[5 4], 0);
[Q,R] = qr(C)
Q =
0.6191 0.1406 -0.1899 -0.5058 0.5522
0.1506 0.4084 0.5034 0.5974 0.4475
0.3954 -0.5564 0.6869 -0.1478 -0.2008
0.3167 0.6676 0.1351 -0.1729 -0.6370
0.5808 -0.2410 -0.4695 0.5792 -0.2207
R =
1.5346 1.0663 1.2010 1.4036
0 0.7245 0.3474 -0.0126
0 0 0.9320 0.6596
0 0 0 0.6648
0 0 0 0多くの場合、Q の最後の m – n 列は R の下部にゼロを乗算することになるため必要ありません。したがってエコノミー サイズの QR 分解は、直交要素をもつ m 行 n 列の方形行列 Q と、正方の n 行 n 列の上三角行列 R を生成します。この 5 行 4 列の例ではあまり大きな影響はありませんが、非常に大きい方形行列の場合は、時間とメモリが節約されるため数値計算ではこの手法が非常に効果的になります。
[Q,R] = qr(C,0)
Q =
0.6191 0.1406 -0.1899 -0.5058
0.1506 0.4084 0.5034 0.5974
0.3954 -0.5564 0.6869 -0.1478
0.3167 0.6676 0.1351 -0.1729
0.5808 -0.2410 -0.4695 0.5792
R =
1.5346 1.0663 1.2010 1.4036
0 0.7245 0.3474 -0.0126
0 0 0.9320 0.6596
0 0 0 0.6648LU 分解とは異なり、QR 分解はピボットや置換は必要ありません。ただし 3 番目の出力引数を設定すると、オプションの列置換が出力され、特異性やランク落ちを調べる場合に便利です。分解の各ステップでは、分解していない残りの行列の列の中で最も大きなノルムをもつ列がそのステップでの基底として使われます。この計算方法により R の対角要素を小さい順に並べることができ、要素間の関係性を調べることによって各列の間に存在する線形依存性を明らかにすることができます。この簡単な例では、C の 2 列目は 1 列目のノルムよりも大きいノルムをもちます。そこで 2つの列を交換します。
[Q,R,P] = qr(C)
Q =
-0.3522 0.8398 -0.4131
-0.7044 -0.5285 -0.4739
-0.6163 0.1241 0.7777
R =
-11.3578 -8.2762
0 7.2460
0 0
P =
0 1
1 0エコノミー サイズと列の置換を組み合わせると、3 番目の出力引数は置換行列ではなく置換ベクトルになります。
[Q,R,p] = qr(C,0)
Q =
-0.3522 0.8398
-0.7044 -0.5285
-0.6163 0.1241
R =
-11.3578 -8.2762
0 7.2460
p =
2 1QR 分解では過決定の線形方程式を等価な三角行列に変換します。次の式をみてみましょう。
norm(A*x - b)
は以下と等価です。
norm(Q*R*x - b)
直交行列の乗算はユークリッド ノルムを保存するため、この式は以下と同じです。
norm(R*x - y)
ここで y = Q'*b です。R の最後の m-n 行はゼロであるため、この式は 2 つに分けられます。
norm(R(1:n,1:n)*x - y(1:n))
と
norm(y(n+1:m))
A がフル ランクの場合は x に対して解くことができ、最初の式はゼロになります。次に 2 番目の式が残差のノルムを指定します。A がフル ランクでない場合は、R の三角構造から最小二乗問題に対する基本解を計算します。
行列分解のマルチスレッド計算
MATLAB は多数の線形関数と要素ごとに計算する数値関数のマルチスレッド計算をサポートしています。これらの関数は自動的にマルチスレッドで実行されます。関数や式に対し、複数の CPU を使用して計算を高速化するにはさまざまな条件があります。
関数は同時実行可能な部分へ簡単に分割できる処理を実行します。この分割部分は各処理間で通信をほとんど行わずに実行されるものでなければなりません。すなわちシーケンシャルな処理がほとんどないものを扱います。
データを分割し、複数の実行スレッドを管理する時間を含めても同時実行する価値があるように、データ サイズは十分に大きいものを扱います。たとえば配列が数千個以上の要素を含む場合は、ほとんどの関数に対して高速化の効果があります。
処理がメモリに拘束されないものを扱います。すなわち処理時間の大部分がメモリのアクセス時間にならないものを扱います。一般的には、シンプルな処理より複雑な処理をする関数の方が、高速化の効果があります。
関数 lu と関数 qr を使うと、大規模な倍精度配列 (10,000 個以上の要素) に対する計算を大幅に高速化します。
参考
関連するトピック
べき乗と指数
このトピックでは、さまざまな方法を使用して行列のべき乗と指数を計算する方法を説明します。
正の整数のべき乗
A が正方行列で p が正の整数の場合、A^p は A をそれ自身に p-1 回乗算します。以下に例を示します。
A = [1 1 1
1 2 3
1 3 6];
A^2ans = 3×3
3 6 10
6 14 25
10 25 46
逆数と分数のべき乗
A が正方行列で特異でない場合、A^(-p) は inv(A) を p-1 回乗算します。
A^(-3)
ans = 3×3
145.0000 -207.0000 81.0000
-207.0000 298.0000 -117.0000
81.0000 -117.0000 46.0000
MATLAB® では inv(A) と A^(-1) が同じアルゴリズムで計算されるため、結果はまったく同じになります。行列が特異に近くなる場合、inv(A) と A^(-1) はどちらも警告を発生させます。
isequal(inv(A),A^(-1))
ans = logical
1
A^(2/3) のような分数のべき乗も計算可能です。分数のべき乗を使用した結果は、行列の固有値の分布によって異なります。
A^(2/3)
ans = 3×3
0.8901 0.5882 0.3684
0.5882 1.2035 1.3799
0.3684 1.3799 3.1167
要素単位のべき乗
.^ 演算子は要素単位のべき乗を計算します。たとえば、行列の各要素を二乗するには、A.^2 を使用できます。
A.^2
ans = 3×3
1 1 1
1 4 9
1 9 36
平方根
関数 sqrt は、行列の各要素の平方根を計算するのに便利な方法です。これを行う代替方法は A.^(1/2) です。
sqrt(A)
ans = 3×3
1.0000 1.0000 1.0000
1.0000 1.4142 1.7321
1.0000 1.7321 2.4495
他の根には nthroot を使用できます。たとえば、A.^(1/3) を計算します。
nthroot(A,3)
ans = 3×3
1.0000 1.0000 1.0000
1.0000 1.2599 1.4422
1.0000 1.4422 1.8171
これらの要素ごとの根は、 となるように第 2 の行列 が計算される、行列の平方根とは異なります。関数 sqrtm(A) は、より正確なアルゴリズムによって A^(1/2) を計算します。sqrtm の中の m によって、この関数は sqrt(A) と区別されますが、後者は A.^(1/2) と同様に要素ごとに計算を行います。
B = sqrtm(A)
B = 3×3
0.8775 0.4387 0.1937
0.4387 1.0099 0.8874
0.1937 0.8874 2.2749
B^2
ans = 3×3
1.0000 1.0000 1.0000
1.0000 2.0000 3.0000
1.0000 3.0000 6.0000
スカラー基底
行列をべき乗にするだけでなく、スカラーを行列のべき乗にすることもできます。
2^A
ans = 3×3
10.4630 21.6602 38.5862
21.6602 53.2807 94.6010
38.5862 94.6010 173.7734
スカラーを行列のべき乗にする場合、MATLAB は行列の固有値と固有ベクトルを使用して行列のべき乗を計算します。[V,D] = eig(A) の場合は、 となります。
[V,D] = eig(A); V*2^D*V^(-1)
ans = 3×3
10.4630 21.6602 38.5862
21.6602 53.2807 94.6010
38.5862 94.6010 173.7734
行列の指数
行列指数は、スカラーを行列のべき乗にする特殊なケースです。行列指数の基底はオイラー数 e = exp(1) です。
e = exp(1); e^A
ans = 3×3
103 ×
0.1008 0.2407 0.4368
0.2407 0.5867 1.0654
0.4368 1.0654 1.9418
行列指数を計算するには、関数 expm がより便利です。
expm(A)
ans = 3×3
103 ×
0.1008 0.2407 0.4368
0.2407 0.5867 1.0654
0.4368 1.0654 1.9418
行列指数の計算方法はいくつかあります。詳細については、行列の指数を参照してください。
小さい数値の処理
MATLAB 関数 log1p および expm1 は、 の非常に小さい値について と を正確に計算します。たとえば、マシンの精度より小さい数値を 1 に加算しようとすると、結果は 1 に丸められます。
log(1+eps/2)
ans = 0
しかし、log1p は、より精度の高い解を返すことができます。
log1p(eps/2)
ans = 1.1102e-16
同様に では、 が非常に小さいとゼロに丸められます。
exp(eps/2)-1
ans = 0
この場合も、expm1 は、より精度の高い解を返すことができます。
expm1(eps/2)
ans = 1.1102e-16
参考
exp | expm | expm1 | power | mpower | sqrt | sqrtm | nthroot
関連するトピック
固有値
固有値分解
正方行列 A の "固有値" と "固有ベクトル" は、次の関係を満たすスカラー λ とゼロ以外のベクトル υ で表します。
Aυ = λυ。
対角行列 Λ の対角要素に固有値を配置し、行列 V の列に対応する固有ベクトルを配置すると、次のような関係になります。
AV = VΛ。
V が特異でない場合、これは固有値分解になります。
A = VΛV–1。
この微分方程式 dx/dt = Ax の係数行列は良い例です。
A =
0 -6 -1
6 2 -16
-5 20 -10この方程式の解は、行列指数 x(t) = etAx(0) で表されます。ステートメント
lambda = eig(A)
は、A の固有値を含む列ベクトルを作成します。この行列の例の固有値は複素数になります。
lambda =
-3.0710
-2.4645+17.6008i
-2.4645-17.6008i各固有値の実数部は負で、eλt は t が増加するとゼロに近づきます。2 つの固有値のゼロ以外の虚数部 ±ω は、微分方程式の解の振動構成成分 sin(ωt) に関連します。
2 つの出力引数を設定すると eig は固有ベクトルを計算し、対角に固有値を出力します。
[V,D] = eig(A)
V =
-0.8326 0.2003 - 0.1394i 0.2003 + 0.1394i
-0.3553 -0.2110 - 0.6447i -0.2110 + 0.6447i
-0.4248 -0.6930 -0.6930
D =
-3.0710 0 0
0 -2.4645+17.6008i 0
0 0 -2.4645-17.6008i最初の固有ベクトルは実数で、他の 2 つのベクトルは互いに複素共役になっています。3 つのベクトルはすべてユークリッド長で、norm(v,2) が 1 になるように正規化されています。
V*D/V を簡潔に表現できる行列 V*D*inv(V) は、A の丸め誤差の範囲内に入ります。そして inv(V)*A*V または V\A*V は D の丸め誤差の範囲内に入ります。
複数の固有値
固有ベクトル分解できない行列もあります。これらの行列は対角化できません。以下に例を示します。
A = [ 1 -2 1
0 1 4
0 0 3 ]この行列に対して、
[V,D] = eig(A)
は、以下の結果を出力します。
V =
1.0000 1.0000 -0.5571
0 0.0000 0.7428
0 0 0.3714
D =
1 0 0
0 1 0
0 0 3λ = 1 の場合、2 つの固有値が存在します。V の 1 番目と 2 番目の列は同じです。この行列に対して、完全に線形に独立した固有ベクトルの組は存在しません。
Schur 分解
高度な行列計算の多くは固有値分解を必要としません。代わりに Schur 分解を使います。
A = USU′
ここで U は直交行列で、S は 1 行 1 列および 2 行 2 列のブロックを対角要素にもつ上三角行列のブロックです。固有値は対角要素と S のブロックで表されます。一方、U の列は固有ベクトルよりも数値特性の良い直交基底を与えます。
たとえば、このフル ランクではない行列の固有値と Schur 分解を比較します。
A = [ 6 12 19
-9 -20 -33
4 9 15 ];
[V,D] = eig(A)V = -0.4741 + 0.0000i -0.4082 - 0.0000i -0.4082 + 0.0000i 0.8127 + 0.0000i 0.8165 + 0.0000i 0.8165 + 0.0000i -0.3386 + 0.0000i -0.4082 + 0.0000i -0.4082 - 0.0000i D = -1.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 1.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 1.0000 - 0.0000i
[U,S] = schur(A)
U =
-0.4741 0.6648 0.5774
0.8127 0.0782 0.5774
-0.3386 -0.7430 0.5774
S =
-1.0000 20.7846 -44.6948
0 1.0000 -0.6096
0 0.0000 1.0000完全に線形に独立した固有ベクトルの組は存在しない (V の 2 列目と 3 列目が同じ) ため、行列 A はフル ランクではありません。V の一部の列が線形に独立していないので、それは約 ~1e8 の大きな条件数をもちます。ただし、schur は、U の 3 つの異なる基底ベクトルを計算できます。U は直交であるため、cond(U) = 1 となります。
行列 S は、対角の最初のエントリとして実固有値、および 2 行 2 列のブロックの右下隅で表される反復固有値をもちます。2 行 2 列のブロックの固有値は、A の固有値でもあります。
eig(S(2:3,2:3))
ans = 1.0000 + 0.0000i 1.0000 - 0.0000i
参考
関連するトピック
外部の Web サイト
特異値
方形行列 A の "特異値" と対応する "特異ベクトル" は、スカラー σ と u と v の 1 組のベクトルで表され、次の式を満たします。
ここで、 は A のエルミート転置です。通常、特異ベクトル u と v はノルムが 1 になるようにスケーリングされます。また、u と v が A の特異ベクトルである場合は、-u と -v も A の特異ベクトルです。
特異値 σ は、A が複素数であっても、常に非負の実数です。対角行列 Σ に特異値を配置します。これに対応する特異ベクトルは 2 つの直交行列 U と V の列からなり、次のような方程式が導出されます。
U と V はユニタリ行列であるため、最初の方程式に右側から を乗算すると、特異値分解の方程式が導出されます。
m 行 n 列の行列の非スパースな特異値分解は、次で表されます。
m 行 m 列の行列 U
m 行 n 列の行列 Σ
n 行 n 列の行列 V
言い換えれば U と V は共に正方で、Σ は A と同じサイズです。A の行数が列数よりずっと多い場合 (m > n)、結果の m 行 m 列の行列 U は大きくなります。ただし、U のほとんどの列は Σ のゼロで乗算されます。このような場合 "エコノミー サイズ" で分解すると、m 行 n 列の U、n 行 n 列の Σ、同じ V が作成され、計算時間もメモリ サイズも節約されます。
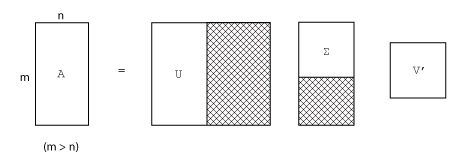
常微分方程式を表現する場合ように、あるベクトル空間内でマッピングを行う場合、固有値分解はその行列の解析に適切な方法になります。ただし、あるベクトル空間から他のベクトル空間へマッピングする行列を解析する場合は特異値分解が適切な方法になります。特異値分解は異なる次元についても扱えます。ほとんどの連立線形方程式は、この 2 番目の方法のカテゴリに入ります。
A が正方、対称、かつ正定値の場合は、この固有値分解と特異値分解は等しくなります。ただし A が対称および正定値でない場合、2 つの分解の結果のズレは大きくなります。特に実数行列の特異値分解は常に実数ですが、実数の非対称行列の固有値分解は複素数になることもあります。
例として行列を作成します。
A = [9 4
6 8
2 7];A に対して非スパースな特異値分解は次のようになります。
[U,S,V] = svd(A)
U =
-0.6105 0.7174 0.3355
-0.6646 -0.2336 -0.7098
-0.4308 -0.6563 0.6194
S =
14.9359 0
0 5.1883
0 0
V =
-0.6925 0.7214
-0.7214 -0.6925U*S*V' が丸め誤差の範囲内で A に等しいことが確かめられます。このような小さな行列の問題をエコノミー サイズで分解すると、わずかですが使用メモリ サイズを小さくできます。
[U,S,V] = svd(A,"econ")
U =
-0.6105 0.7174
-0.6646 -0.2336
-0.4308 -0.6563
S =
14.9359 0
0 5.1883
V =
-0.6925 0.7214
-0.7214 -0.6925U*S*V' が丸め誤差の範囲内で A に等しいことを再確認できます。
SVD 計算のバッチ処理
同じサイズの行列の大規模な集合を分解する必要がある場合、svd を使用してすべての分解をループで実行するのは非効率的です。代わりに、すべての行列を多次元配列に連結して pagesvd を使用すると、単一の関数呼び出しですべての配列ページの特異値分解を実行できます。
| 関数 | 使用方法 |
|---|---|
pagesvd | 関数 pagesvd を使用して、多次元配列のページで特異値分解を実行します。これは、すべて同じサイズの行列の大規模な集合で SVD を実行する効率的な方法です。 |
たとえば、2 行 2 列の 3 つの行列の集合について考えてみます。関数 cat を使用して、行列を 2 x 2 x 3 の配列に連結します。
A = [0 -1; 1 0]; B = [-1 0; 0 -1]; C = [0 1; -1 0]; X = cat(3,A,B,C);
次に、pagesvd を使用して、3 つの分解を同時に実行します。
[U,S,V] = pagesvd(X);
X の各ページに、出力 U、S、および V の対応するページがあります。たとえば、行列 A は X の最初のページにあり、その分解は U(:,:,1)*S(:,:,1)*V(:,:,1)' で与えられます。
SVD による低ランク近似
大規模なスパース行列では、svd を使用して "すべて" の特異値と特異ベクトルを計算することは、必ずしも現実的ではありません。たとえば、最も大きい特異値をいくつかだけ知る必要がある場合に、5000 行 5000 列のスパース行列の特異値をすべて計算するのは余分な作業となります。
特異値と特異ベクトルのサブセットのみが必要な場合は、関数 svd よりも、関数 svds と関数 svdsketch が推奨されます。
| 関数 | 使用方法 |
|---|---|
svds | svds を使用して、SVD によるランク k の近似を計算します。特異値のサブセットを最大にするか、最小にするか、特定の数に最も近くするかを指定できます。svds は一般的に、ランク k の最適な近似を計算します。 |
svdsketch | svdsketch を使用して、指定された許容誤差を満たす、入力行列の部分的な SVD を計算します。svds ではランクを指定する必要がありますが、svdsketch では指定された許容誤差に基づき、行列スケッチのランクが適応的に特定されます。svdsketch が最終的に使用するランク k の近似は許容誤差を満たしますが、svds と異なり、最適なものであることは保証されません。 |
たとえば、密度が約 30% である、1000 行 1000 列のランダムなスパース行列について考えてみます。
n = 1000; A = sprand(n,n,0.3);
6 つの最大特異値は次のようになります。
S = svds(A) S = 130.2184 16.4358 16.4119 16.3688 16.3242 16.2838
また、6 つの最小特異値は次のようになります。
S = svds(A,6,"smallest")
S =
0.0740
0.0574
0.0388
0.0282
0.0131
0.0066行列が比較的小さく、非スパース行列 full(A) としてメモリに収まる場合は、svds や svdsketch よりも svd(full(A)) を使用するほうが依然として高速になることがあります。ただし、非常に大規模なスパース行列の場合は、svds や svdsketch の使用が必要になります。
参考
svd | svds | svdsketch | gsvd | pagesvd
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)