svds
特異値とベクトルのサブセット
構文
説明
s = svds(A,k,sigma,Name,Value)svds(A,k,sigma,'Tolerance',1e-3) はアルゴリズムの収束の許容誤差を調整します。
例
行列 A = delsq(numgrid('C',15)) は、区間 (0 8) において妥当に配置された特異値をもつ対称正定値行列です。最も大きい 6 個の特異値を計算します。
A = delsq(numgrid('C',15));
s = svds(A)s = 6×1
7.8666
7.7324
7.6531
7.5213
7.4480
7.3517
2 番目の入力に、計算する最も大きい特異値の数を指定します。
s = svds(A,3)
s = 3×1
7.8666
7.7324
7.6531
行列 A = delsq(numgrid('C',15)) は、区間 (0 8) において妥当に配置された特異値をもつ対称正定値行列です。最も小さい 5 個の特異値を計算します。
A = delsq(numgrid('C',15)); s = svds(A,5,'smallest')
s = 5×1
0.5520
0.4787
0.3469
0.2676
0.1334
スパースの 100 行 100 列のノイマン行列を作成します。
C = gallery('neumann',100);最も小さい 10 個の特異値を計算します。
ss = svds(C,10,'smallest')ss = 10×1
0.9828
0.9049
0.5625
0.5625
0.4541
0.4506
0.2256
0.1139
0.1139
0
最も小さい 10 個の非ゼロの特異値を計算します。行列にはゼロに等しい特異値があるため、'smallestnz' オプションによりその値が省略されます。
snz = svds(C,10,'smallestnz')snz = 10×1
0.9828
0.9828
0.9049
0.5625
0.5625
0.4541
0.4506
0.2256
0.1139
0.1139
スパース行列の右上および左下の非ゼロのブロックを表す 2 つの行列を作成します。
n = 500; B = rand(500); C = rand(500);
svds で使用できるように、Afun を現在のディレクトリに保存します。
function y = Afun(x,tflag,B,C,n) if strcmp(tflag,'notransp') y = [B*x(n+1:end); C*x(1:n)]; else y = [C'*x(n+1:end); B'*x(1:n)]; end
関数 Afun は B および C を使用して、実際にスパース行列 A = [zeros(n) B; C zeros(n)] 全体を作成することなく、指定されたフラグに応じて A*x または A'*x を計算します。これは行列のスパース パターンを利用して、A*x および A'*x を計算するときにメモリを節約します。
Afun を使用して、A の最も大きい 10 個の特異値を計算します。B、C および n を追加の入力として Afun に渡します。
s = svds(@(x,tflag) Afun(x,tflag,B,C,n),[1000 1000],10)
s = 250.3248 249.9914 12.7627 12.7232 12.6988 12.6608 12.6166 12.5643 12.5419 12.4512
A の最も大きい 10 個の特異値を直接計算して、結果と比較します。
A = [zeros(n) B; C zeros(n)]; s = svds(A,10)
s = 250.3248 249.9914 12.7627 12.7232 12.6988 12.6608 12.6166 12.5643 12.5419 12.4512
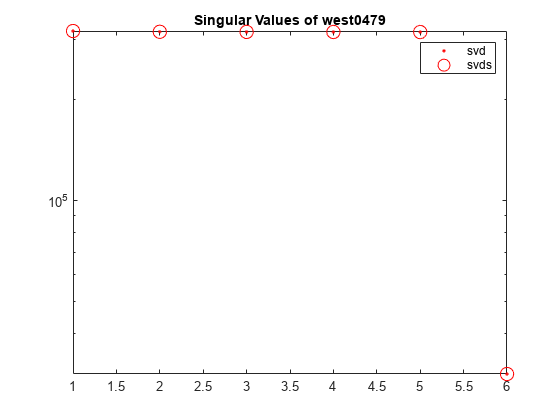
west0479 は、479 行 479 列の実数値のスパース行列です。この行列には、いくつかの大きい特異値と、多数の小さい特異値があります。
west0479 を読み込んで、A として格納します。
load west0479
A = west0479;A の特異値分解を計算し、最も大きい 6 個の特異値および対応する特異ベクトルを返します。特異値の収束を確認するために、4 番目の出力引数を指定します。
[U,S,V,cflag] = svds(A); cflag
cflag = 0
cflag は、すべての特異値が収束したことを示します。特異値は、出力行列 S の対角成分です。
s = diag(S)
s = 6×1
105 ×
3.1895
3.1725
3.1695
3.1685
3.1669
0.3038
A の完全な特異値分解を計算して、結果を確認します。A を完全な行列に変換して、svd を使用します。
[U1,S1,V1] = svd(full(A));
対数スケールを使用して svd と svds によって計算された A の最も大きい 6 個の特異値をプロットします。
s2 = diag(S1); semilogy(s2(1:6),'r.') hold on semilogy(s,'ro','MarkerSize',10) title('Singular Values of west0479') legend('svd','svds')
スパース対角行列を作成して、最も大きい 6 個の特異値を計算します。
A = diag(sparse([1e4*ones(1, 8) 1e4:-1:1])); s = svds(A)
Warning: Only 2 of the 6 requested singular values converged. Singular values that did not converge are NaN.
s = 6×1
104 ×
1.0000
0.9999
NaN
NaN
NaN
NaN
svds によって警告が出力されます。これは最大回数の反復を実行したが、許容誤差に収まらなかったためです。
収束の問題を解決する最も効果的な方法は、'SubspaceDimension' により大きい値を使用することにより、計算に使用する Krylov 部分空間の最大サイズを増加することです。これを実行するには、60 の値を使用して 'SubspaceDimension' の名前と値のペアを渡します。
s = svds(A,6,'largest','SubspaceDimension',60)
s = 6×1
104 ×
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
近特異行列の最も小さい 10 個の特異値を計算します。
rng default format shortg B = spdiags([repelem([1; 1e-7], [198, 2]) ones(200, 1)], [0 1], 200, 200); s1 = svds(B,10,'smallest')
Warning: Large residual norm detected. This is likely due to bad condition of the input matrix (condition number 1.0008e+16).
s1 = 10×1
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
0.25927
7.0888e-16
警告は、svds が適切な特異値の計算に失敗したことを示します。svds が失敗した原因は、最小と最小から 2 番目の特異値の間にギャップがあるためです。svds(...,'smallest') は B の逆行列を計算する必要があり、これにより大きい数値誤差が発生しています。
比較のために、svd を使用して、正確な特異値を計算します。
s = svd(full(B)); s = s(end-9:end)
s = 10×1
0.14196
0.12621
0.11045
0.094686
0.078914
0.063137
0.047356
0.031572
0.015787
7.0888e-16
svds でこの計算を再現するために、B の QR 分解を行います。三角行列 R の特異値は、B と同じになります。
[Q,R,p] = qr(B,0);
R の各行のノルムをプロットします。
rownormR = sqrt(diag(R*R')); semilogy(rownormR) hold on; semilogy(size(R, 1), rownormR(end), 'ro')
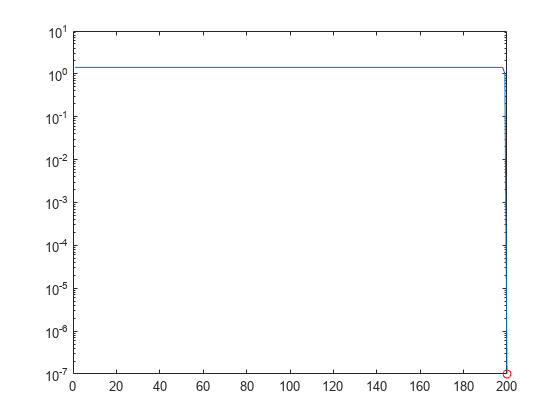
R の最後の要素はほぼゼロであるため、解が不安定になります。
この要素による悪い影響が解の正しい部分に及ばないように、R の最後の行を厳密にゼロに設定します。
R(end,:) = 0;
svds を使用して R の最も小さい 10 個の特異値を見つけます。結果は svd で得られたものと同等です。
sr = svds(R,10,'smallest')sr = 10×1
0.14196
0.12621
0.11045
0.094686
0.078914
0.063137
0.047356
0.031572
0.015787
0
この方法を使用して B の特異ベクトルを計算するには、 Q および置換ベクトル pを使用して左右の特異ベクトルを変換します。
[U,S,V] = svds(R,20,'s');
U = Q*U;
V(p,:) = V;入力引数
名前と値の引数
出力引数
ヒント
svdsketchは、svdsにどのランクを指定するかは事前にわからないが、SVD の近似が満たすべき許容誤差はわかる場合に有用です。svdsは、複数の実行にわたって再現性を確保するために、プライベート乱数ストリームを使用して既定の開始ベクトルを生成します。svdsを呼び出す前にrngを使用して乱数発生器の状態を設定しても、出力に影響しません。svdsを使用する方法は、小規模で密度の高い行列の特異値をいくつか求めるときに最も効率的な方法とは言えません。このような問題では、svd(full(A))を使用する方が迅速な場合があります。たとえば、500 行 500 列の行列の特異値を 3 個求める問題は、比較的小規模の問題であるためsvdで容易に処理できます。指定された行列で
svdsが収束しない場合は、'SubspaceDimension'の値を増加することにより Krylov 部分空間のサイズを増加します。補助的な選択肢として、反復の最大回数 ('MaxIterations') と収束の許容誤差 ('Tolerance') を調整することも、収束動作に役立つ場合があります。kを増加することでパフォーマンスが向上することがあり、特に行列に繰り返される特異値がある場合に効果的です。
参照
[1] Baglama, J. and L. Reichel, “Augmented Implicitly Restarted Lanczos Bidiagonalization Methods.” SIAM Journal on Scientific Computing. Vol. 27, 2005, pp. 19–42.
[2] Larsen, R. M. “Lanczos Bidiagonalization with partial reorthogonalization.” Dept. of Computer Science, Aarhus University. DAIMI PB-357, 1998.